

此分類用於記錄吳恩達深度學習課程的學習筆記。
課程相關信息鏈接如下:
- 原課程視頻鏈接:[雙語字幕]吳恩達深度學習deeplearning.ai
- github課程資料,含課件與筆記:吳恩達深度學習教學資料
- 課程配套練習(中英)與答案:吳恩達深度學習課後習題與答案
本篇為第四課的第三週內容,3.3到3.5的內容。
本週為第四課的第三週內容,這一課所有內容的中心只有一個:計算機視覺。應用在深度學習裏,就是專門用來進行圖學習的模型和技術,是在之前全連接基礎上的“特化”,也是相關專業裏的一個重要研究大類。
這一整節課都存在大量需要反覆理解的內容和機器學習、數學基礎。 因此我會盡可能的補足基礎,用比喻和實例來演示每個部分,從而幫助理解。
第三週的內容將從圖像分類進一步拓展到目標檢測(Object Detection) 這一更具挑戰性的計算機視覺任務。
與分類任務只需回答“圖中有什麼”不同,目標檢測需要同時解決“ 有什麼”以及“在什麼位置”兩個問題,因此在模型結構設計、訓練方式和評價標準上都更為複雜。
本篇的內容關於目標檢測算法。
1. 檢測算法1.0:對窗口分類
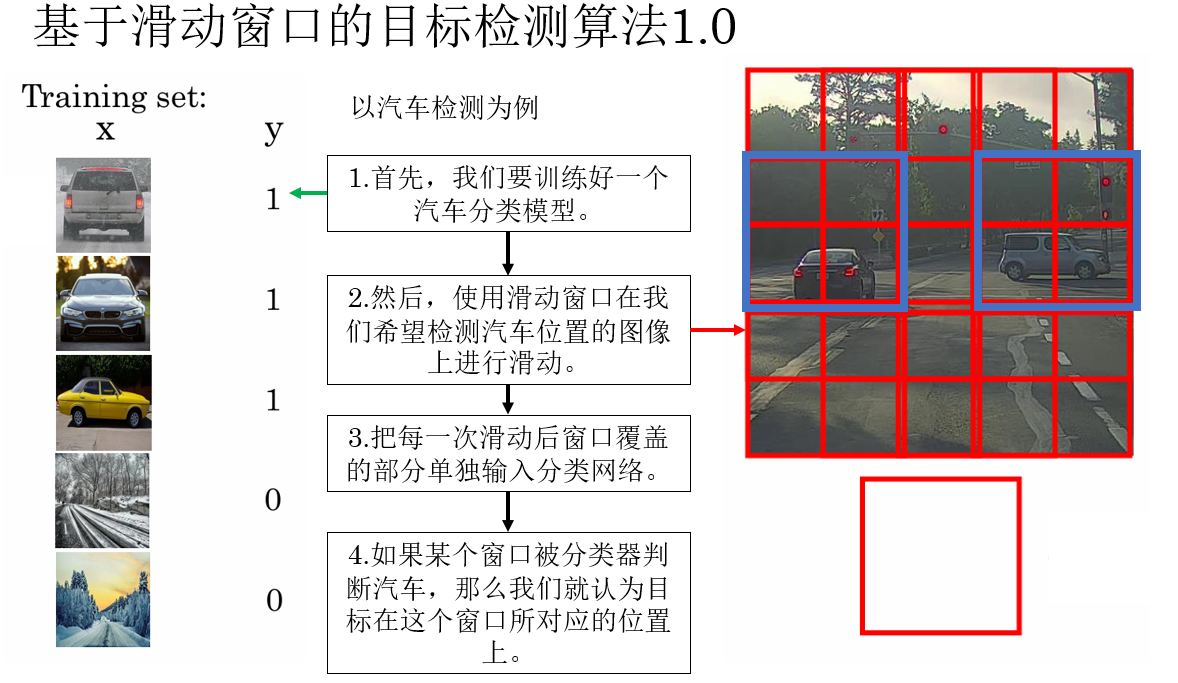
我們知道,想要實現目標檢測,首先就要完成目標識別。
只有當模型能夠回答“要找什麼”後,我們才有可能進一步讓它回答“它在哪裏”。
在早期,人們並沒有一套專門為“檢測”設計的網絡結構,於是有人提出了這樣一種想法:既然分類網絡已經很成熟,那能不能把“找位置”這個問題,轉化成一堆“分類問題”?
而實現這種邏輯的具體做法就是滑動窗口(Sliding Window)。
在這種方法中,我們用一個固定大小的窗口在整張圖像上從左到右、從上到下不斷滑動,把圖像裁剪成一塊一塊的小區域。
然後,將每一個窗口都單獨送入一個已經訓練好的圖像分類網絡中,判斷這個窗口裏“有沒有目標”。
如果某個窗口被分類器判斷為“汽車”“行人”等目標類別,那麼我們就認為:目標就出現在這個窗口所對應的位置上。
就像這樣:
從整體上看,這種檢測流程可以被理解為:
- 用滑動窗口 枚舉可能的位置
- 用分類網絡 判斷每個位置是什麼
- 將被判定為目標的窗口位置,作為最終的檢測結果
但顯然,即使假設分類器完全準確,這種算法仍有它的不足之處。
對於滑動窗口,我們可以設置它的尺寸和步長來調整它在圖像中的運動軌跡,這種固定的設置都十分死板,且同時很難兼顧不同大小目標的完整覆蓋。
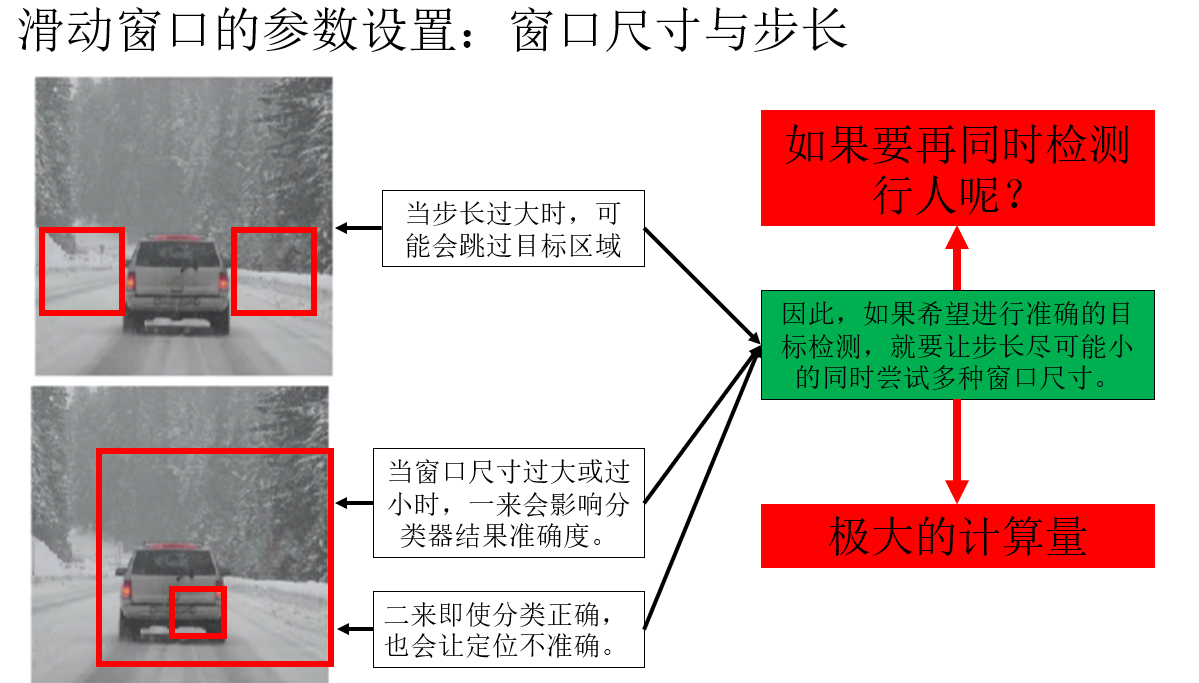
因此,你會發現這種檢測方法其實是一種“取巧”,它本質上並沒有“直接學位置”,而是通過大量的局部分類結果,間接拼湊出目標的位置,在依賴單獨訓練的分類器準確率的前提下還需要極大的計算量。
於是下一步改進出現了。
2. 檢測算法2.0:對整幅圖像應用卷積
為了更好地進行目標檢測,面對 1.0 中出現的極大計算量問題,人們運用數學邏輯,發現了這樣一種情況:當為了更精準的檢測而應用更小步長的窗口時,相鄰的窗口存在公共區域,讓部分計算重複進行。
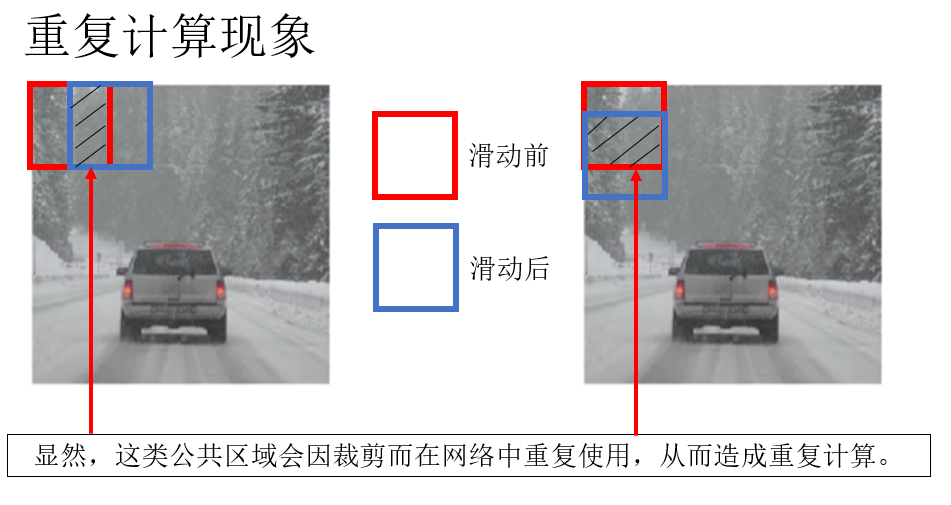
而如果不希望出現公共區域,那就又要增大步長至和尺寸同大小,就又回到了漏檢小目標、定位不精確的問題。
有沒有一種辦法,既能享有小步長帶來的精確度,又能讓重複計算的結果複用從而及減小計算量呢?
有的兄弟,有的。
在 2014 年,一篇名為 OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks 的論文發表,提出了一個利用卷積神經網絡同時實現分類、定位和檢測的統一框架。
而相比 1.0 算法,2.0 最大的改變就是不再把每個窗口裁出來送進網絡,而是直接把整張圖像送進網絡,讓卷積層自動完成“滑動 + 特徵提取”的過程,直接輸出圖像各部分的分類結果。
我們來詳細展開這一部分:
2.1 修改網絡結構適應輸出要求
明確了目標之後,你會發現,不同於原本使用全連接層輸出一維分類結果,現在我們希望讓輸出為一個二維特徵圖,圖中每一個元素就代表一個窗口的分類結果。
就像這樣:
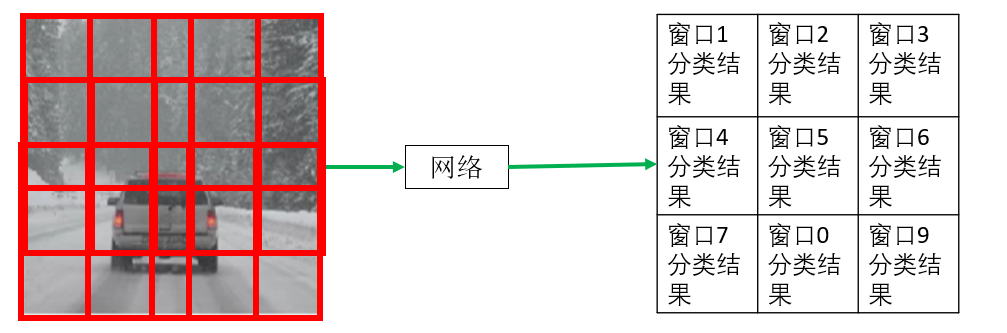
因此,現在我們需要修改網絡結構,使用卷積層取代原本的全連接層,保證輸出同樣為特徵圖。
而要合理地實現這一部分,首先,就要了解如何用卷積層等效代替全連接層。
先説結論:使用和輸入特徵圖尺寸等大小的卷積核。
就像這樣:
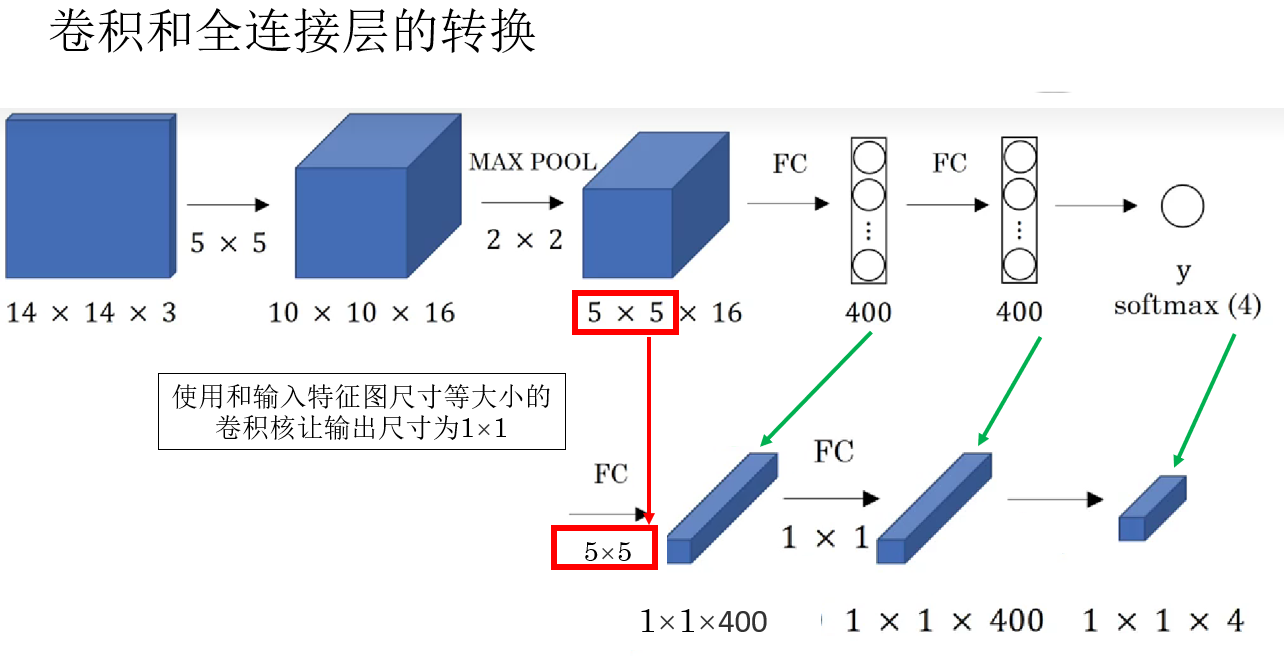
再展開説説原理:
在分類網絡中,當特徵提取部分結束後,輸入全連接層的,通常是一個形狀為 \(H \times W \times C\) 的特徵圖。
全連接層做的事情,本質上是: 把這整個特徵圖“攤平”,然後與一組權重做一次線性組合,輸出一個結果。
如果用公式表示,就是:
換一個角度看,這個過程其實非常像什麼? ——用一個和輸入特徵圖尺寸完全一致的卷積核,在特徵圖上做一次卷積。
因此,當卷積核的尺寸等於輸入特徵圖的空間尺寸時:
- 卷積核只會在輸入上“滑動”一次。
- 卷積輸出自然就是一個 \(1 \times 1\) 的結果。
- 這個結果與全連接層的輸出在數學形式上是完全等價的。
因此可以得到一個直觀的結論:全連接層可以被看作一種特殊形式的卷積層。
現在,我們就瞭解瞭如何修改我們原本一直使用的全連接層作為輸出層的網絡結構,從而適應輸出為帶有空間結構的特徵圖的要求。
現在,就來看看,輸入整幅圖像進入完善後的網絡得到分類輸出的具體過程。
2.2 窗口在網絡中的傳播
我們就用課程裏的例子來演示一下網絡如何一次輸出整幅圖像各個窗口的分類結果:
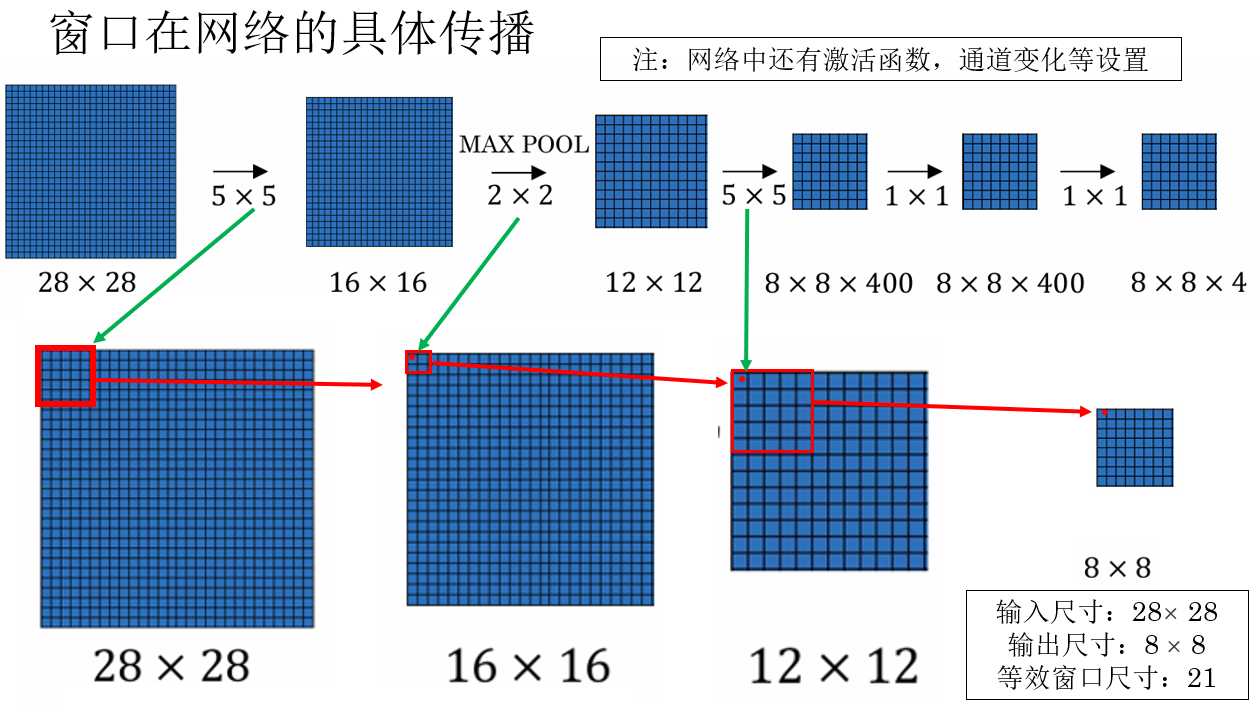
你會發現,得益於卷積操作的特性,輸入圖像的局部特徵本身就在傳播中被一步步集中,第一層特徵圖中的每一個像素,本身就對應着輸入圖像中的一個小窗口。
而隨着網絡不斷加深,卷積層不斷堆疊,每一個特徵點所對應的輸入區域不斷變大。
最終,在靠近輸出層的位置,特徵圖中的一個位置實際上已經“覆蓋”了輸入圖像中的一個較大窗口區域。
只不過現在窗口不再由我們手動裁剪,而是由網絡結構決定。
2.3 拓展:特徵圖輸出的標籤問題
到這裏,我想你可能會有這樣一個問題:我們雖然改變了網絡結構,但是我們這時使用的還是原本分類器的數據,即對一幅圖像的標籤只有一個0或1來表示圖像裏是否存在目標。現在我們修改了輸出格式,是否需要也修改標籤,改為給每個窗口打標籤?
答案是不用。
為什麼?
雖然在訓練階段,網絡接收到的仍然只是圖像級別的分類標籤,但由於輸出已經被展開為一個帶空間結構的特徵圖,這個標籤會被隱式地約束到整張特徵圖上:只要某一個位置對應的窗口能夠正確響應目標類別,這一次預測就被認為是“成功的”。
換句話説,卷積化之後的分類網絡,並不是在學習“這整張圖像是不是目標”,而是在學習:“在這張圖像的哪些位置,存在一個可以被識別為目標的窗口”。
有些抽象,我們可以來看一個具體的例子:
假設訓練集中有一張圖片,內容是一輛汽車,整張圖像的唯一標籤就是「car」。
當這張圖像被送入卷積化後的網絡時,輸出的不再是一個標量,而是一個 \(H' \times W'\) 的分類特徵圖,其中每一個位置都對應輸入圖像中的一個窗口。
在初始訓練階段,這張特徵圖上的絕大多數位置,輸出的分類結果其實都是錯誤的:
- 有的位置覆蓋的是背景
- 有的位置只覆蓋了汽車的一部分
- 還有的位置甚至只包含天空或道路
但這並不會破壞訓練過程。
因為此時網絡的目標並不是要求每一個位置都預測為 car,而是至少存在某一個位置,其對應的窗口能夠對 car 類別產生足夠強的響應。
更準確地説,在訓練階段,並不是直接將整個 \(H' \times W'\) 的輸出特徵圖與圖像級標籤逐位置對齊計算損失。
網絡通常會先在空間維度上進行一次聚合操作(最常見的是取最大響應),將整張特徵圖壓縮為一個標量預測,再與圖像級標籤計算分類損失。
這種訓練方式可以被理解為一種弱監督學習:
只要輸出特徵圖中存在某一個空間位置,對目標類別產生了足夠強的響應,這張圖像就被認為預測正確。
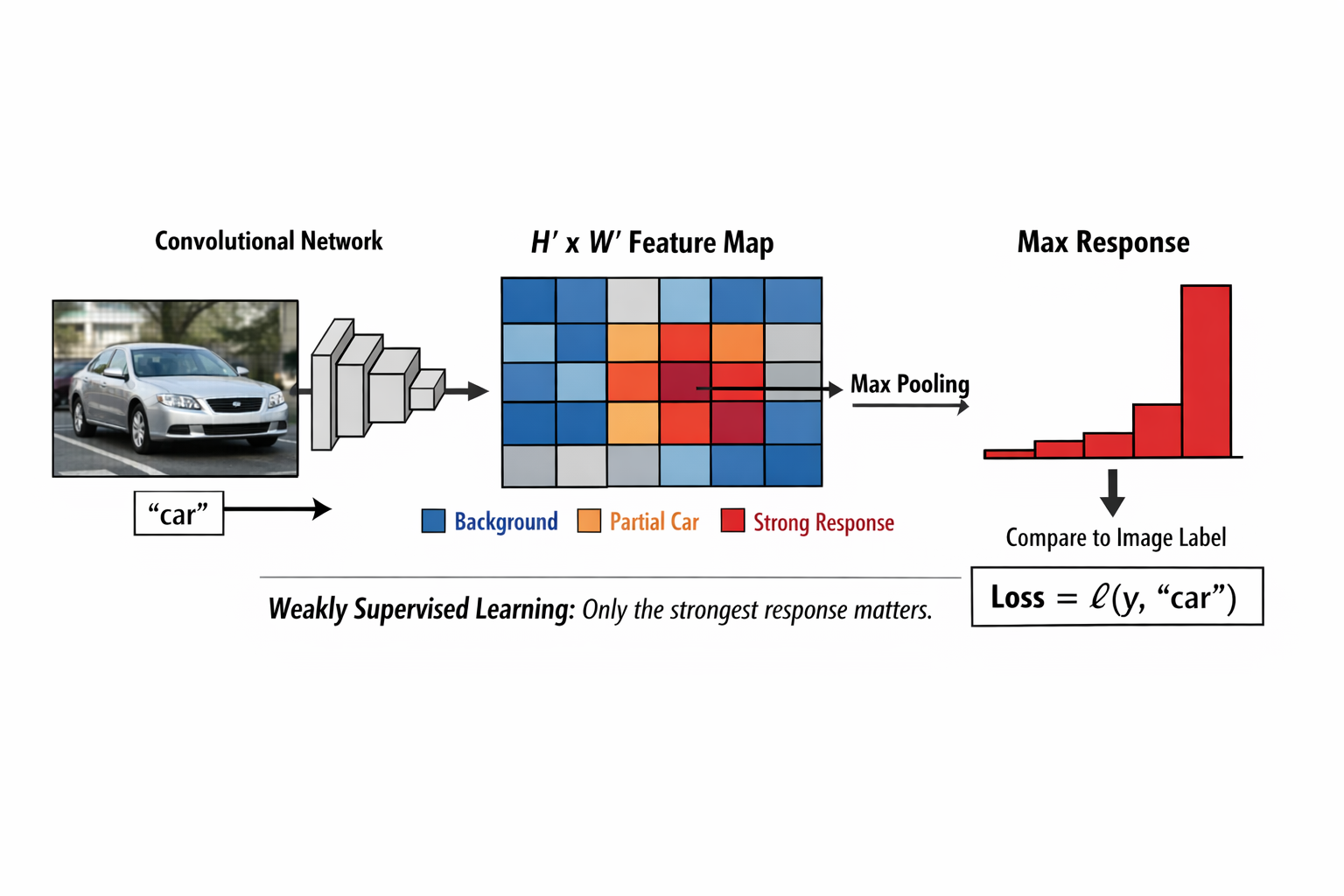
在反向傳播過程中,梯度主要會通過這些高響應位置回傳,從而推動網絡逐漸強化那些確實覆蓋了完整目標或關鍵判別區域的空間位置,而對背景區域的響應自然被壓低。
最終,在輸出特徵圖上,你會看到:只有少數幾個位置對 car 類別產生明顯高響應,而這些位置恰好落在汽車所在的區域附近。
此時,雖然訓練標籤始終只是一個“圖像級標籤”,但網絡已經自動學會了在空間維度上區分“哪裏值得響應”。
於是我們就解決了 1.0 算法導致的極大計算量問題,但是還有一個問題仍然存在,就是固定尺寸的窗口仍無法實現對目標的較精準定位。
怎麼解決?來看看 3.0 算法。
3. 檢測算法3.0:YOLO 算法
YOLO 算法是目前真正主流的算法之一,你可以在目前幾乎目標檢測的所有領域看到它的身影,時至今日,它仍在不斷地更新。
雖然在 2.0 中,窗口已經不再由人手工滑動,而是由網絡結構隱式決定,但本質並沒有變:
網絡輸出的是: “這個窗口裏有沒有目標”,而不是:“目標在哪裏、是什麼、邊界在哪。”
也就是説,2.0 的網絡會告訴你: “這裏大概有個 car”,但不會直接告訴你:“car 的中心在這,寬高是多少。”
它的定位準確度問題仍然存在且不可忽視。
於是,在 2015 年,一篇名為You Only Look Once的論文被髮表,它的核心觀點就是:能不能讓網絡別再糾結“窗口”,而是直接預測目標本身?
論文本身較為複雜,我們來看看 YOLO 相對 1.0、2.0 最關鍵的改變:規範目標檢測任務的標籤。
YOLO 算法本身為目標檢測任務提出了專用的標籤,正是我們在上一篇中介紹的“位置信息”。
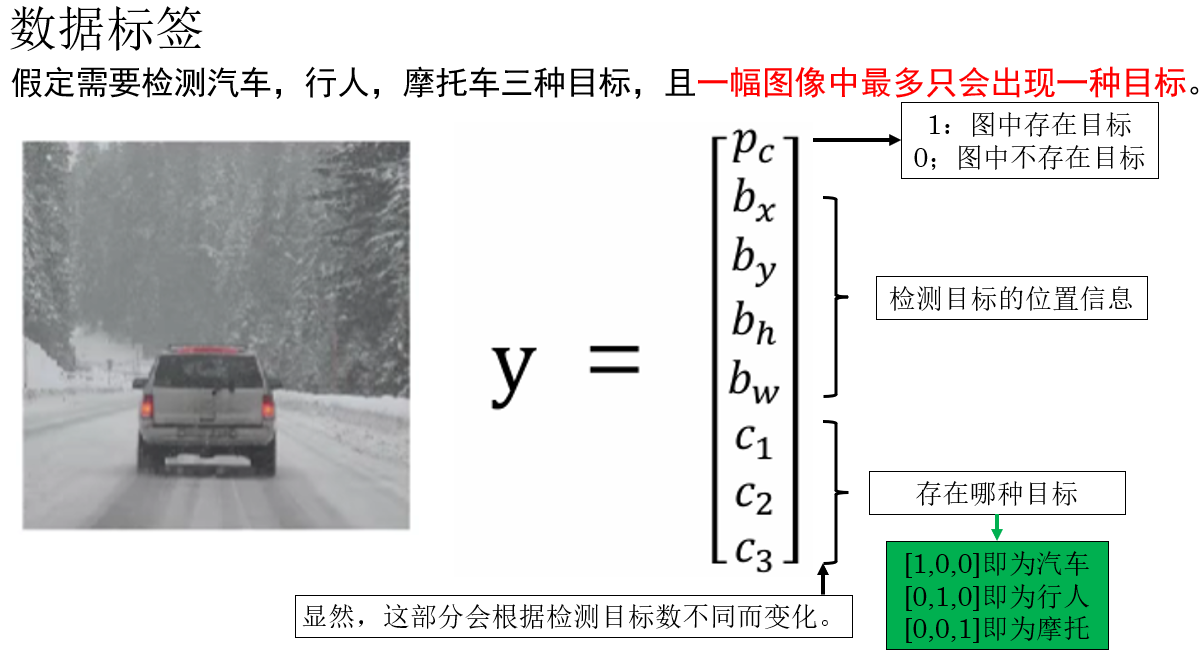
- \(p_c\):表示當前圖像中是否存在需要檢測的目標,這是一個二值變量,通常取值為 \(0\) 或 \(1\)。
當 \(p_c = 1\) 時,表示圖像中確實存在目標,此時後續的位置信息和類別信息才是“有效”的;
當 \(p_c = 0\) 時,表示圖像中不存在目標,其餘參數通常被忽略或置為 0。 - \(b_x,b_y,b_h,b_w\) :表示檢測目標的位置信息。
- \(c_n\):表示目標所屬的類別信息。
在二分類問題中,它可以是一個標量;
在多分類問題中,通常採用 獨熱編碼 的形式,用一個向量來表示目標屬於哪一類。
規範好標籤本身後,我們來看看算法如何使用標籤:
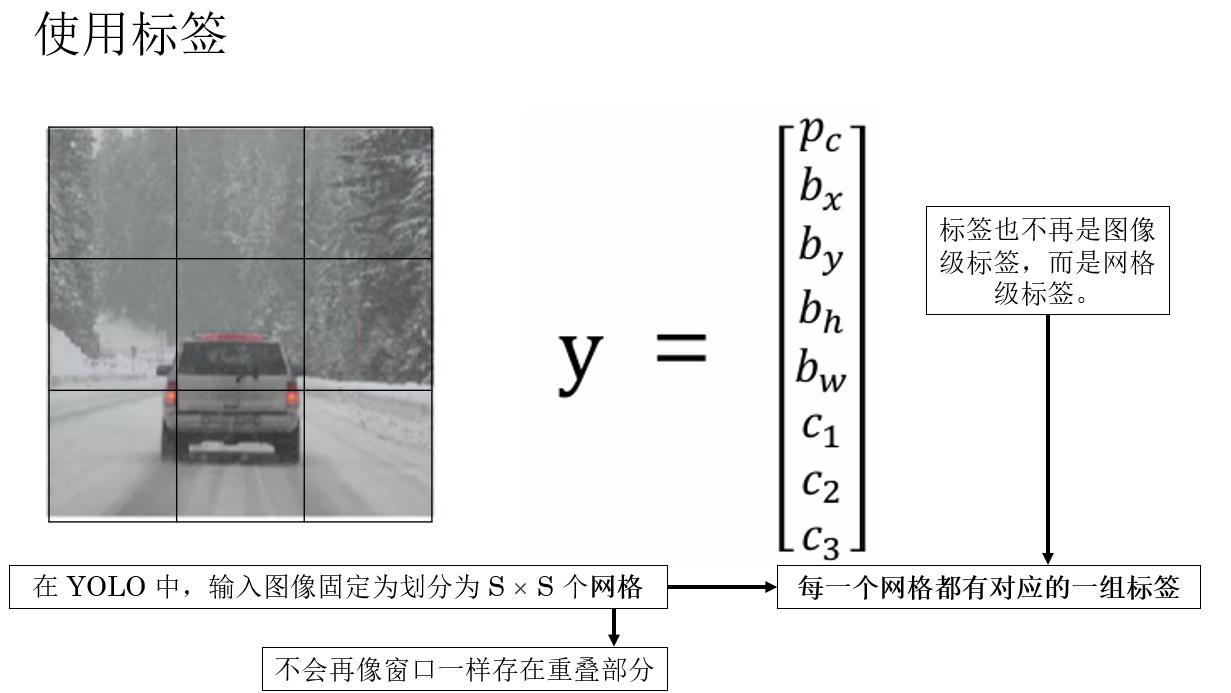
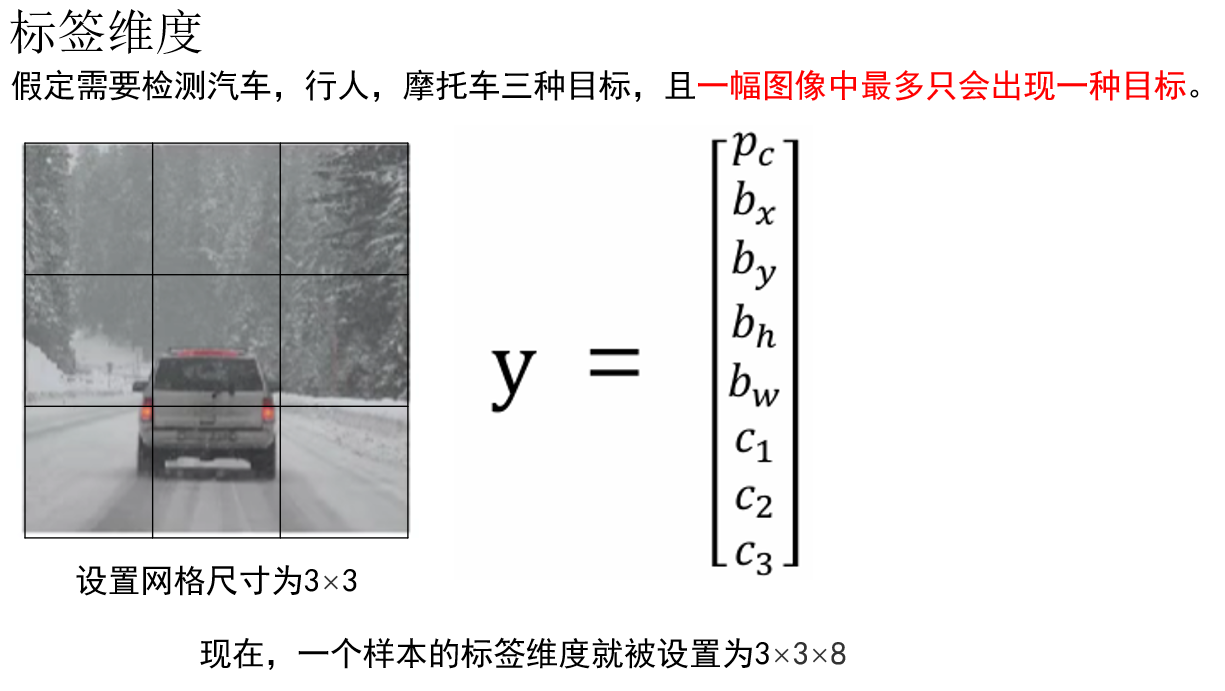
因此,一個樣本在 \(S \times S\) 網格劃分下,其標籤張量維度為:
看到這裏,你可能會疑惑,劃分網格的作用是什麼?我們最開始説 YOLO 避開了窗口又是指什麼?
別急,關鍵點就在於我們剛剛規範的新標籤:\(b_x,b_y,b_h,b_w\) 。
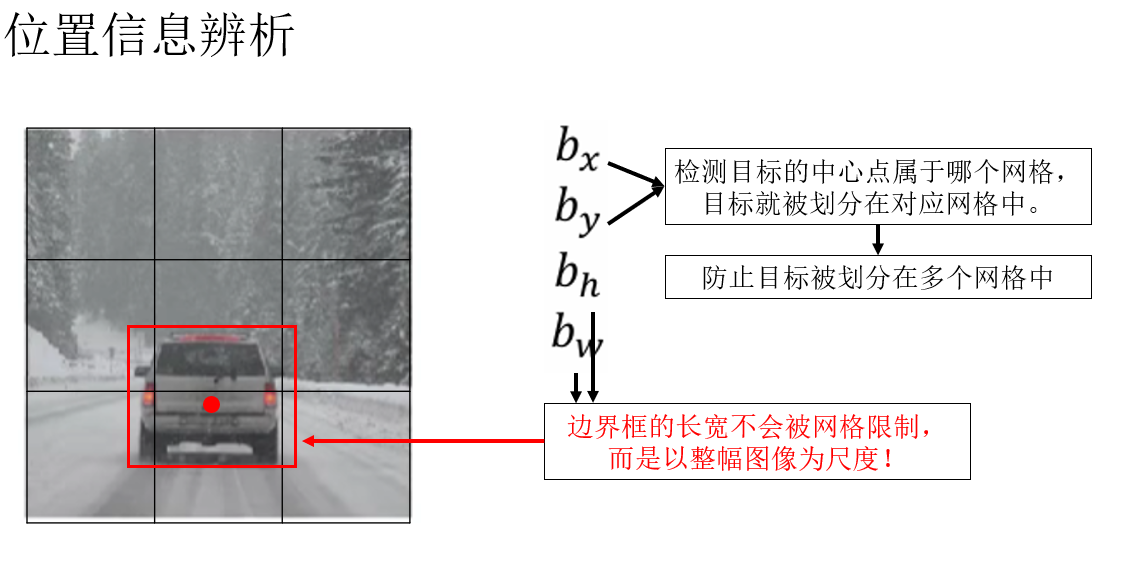
你會發現,通過幾個位置信息參數,我們雖然劃分了網格,但是網格卻不會像窗口的步長一樣限制目標的邊界框,每個網格單元相當於一個預測單元來預測中心點在本單元格里的目標的類別和邊界框。
現在,我們就可以繼續應用 2.0 中的網絡,調整輸出特徵圖為新的標籤維度,即可以此計算損失並反向傳播了。
你會發現,YOLO 的核心優勢是:
- 不再枚舉窗口,不再重複計算。
- 每個網格單元獨立負責預測目標,同時輸出邊界框和類別。
- 訓練時即可端到端優化,預測階段一次前向傳播完成整圖檢測。
可以説,YOLO 的提出讓“檢測”真正從“分類的延伸”脱離出來,成為計算機視覺領域的核心任務之一,它的內容還有很多,我們遇到再慢慢展開。
4.總結
| 概念 | 原理 | 比喻 |
|---|---|---|
| 1.0 滑動窗口檢測 | 使用固定大小窗口在圖像上滑動,將每個窗口送入分類網絡判斷是否包含目標;通過局部分類結果間接拼湊目標位置 | 就像用放大鏡逐塊檢查整張圖,找到目標再標記位置 |
| 問題 | 計算量巨大,每個窗口都要單獨處理;定位精度依賴分類結果拼湊 | 翻閲整本書尋找關鍵詞,每頁都要仔細看一遍 |
| 2.0 卷積化檢測 | 將整幅圖像送入卷積網絡,卷積層自動完成滑動和特徵提取,輸出二維特徵圖表示各位置分類結果;全連接層可被等效卷積替代 | 不用逐頁檢查,而是掃描整本書,自動標記出現關鍵詞的區域 |
| 窗口在特徵圖中傳播 | 隨着卷積層堆疊,每個特徵圖位置對應輸入圖像的一個大窗口區域;訓練階段採用弱監督,只需部分高響應位置預測正確即可 | 小窗口信息逐漸匯聚,像放大鏡自動跟蹤關鍵區域 |
| 標籤設計 | 輸出特徵圖使用圖像級標籤,卷積網絡自動學會空間位置響應,無需對每個窗口手工標註 | 給整本書一個主題標籤,網絡自動找到相關章節 |
| 3.0 YOLO | 網絡直接預測每個網格單元內目標的類別和邊界框;端到端訓練,不再依賴滑動窗口或重複計算 | 每個網格像一個小探員,直接告訴你目標在這裏,並畫出輪廓 |
| YOLO 標籤規範 | 每個網格包含 \(p_c\)(是否有目標)、\(b_x,b_y,b_h,b_w\)(邊界框位置)、\(c_n\)(類別);輸出維度 \(S \times S \times (5 + c_n)\) | 每個小探員攜帶完整信息卡片,報告目標位置和類型 |