

此分類用於記錄吳恩達深度學習課程的學習筆記。
課程相關信息鏈接如下:
- 原課程視頻鏈接:[雙語字幕]吳恩達深度學習deeplearning.ai
- github課程資料,含課件與筆記:吳恩達深度學習教學資料
- 課程配套練習(中英)與答案:吳恩達深度學習課後習題與答案
本篇為第三課的第二週內容,2.9到2.10的內容,也是本篇的理論部分的最後一篇。
本週為第三課的第二週內容,本週的內容關於在上週的基礎上繼續展開,並拓展介紹了幾種“學習方法”,可以簡單分為誤差分析和學習方法兩大部分。
其中,對於後者的的理解可能存在一些難度。同樣,我會更多地補充基礎知識和實例來幫助理解。本篇的內容關於端到端學習,與其説它是一種學習方式,不如説它更像一種學習邏輯,並不難理解,因此本篇的篇幅也較短。
1.什麼是端到端學習?
現在有這樣一道數學題擺在我們面前:
相信你在看到題面的時候就已經得到答案了,但是彆着急,我們來理順一下得出答案的思路。
- 首先,我們要學習阿拉伯數字本身,學習個位數和十位數的區別。
- 然後,我們要學習加法的運算規則,他的表示符號。
- 在之後,我們在加法的基礎上學習乘法和相關表示與計算。
- 最後,我們才得出了計算結果:50
雖然我們一下子就算出了答案,但我們的腦子裏一定會有這樣一步步的過程:理解符號 → 理解運算 → 理解組合 → 得到答案。
而現在,如果你沒有任何數學基礎,我只告訴你:
你解出這道題嗎?答案很顯然,我們最多蒙一蒙。
但是機器能。
在深度學習的世界裏,有一種完全不同的思路。
這種思路不需要我們一層層地把規則寫明,也不需要我們告訴模型“先學數字、再學加法、最後學乘法”。
它允許模型直接從輸入跳到輸出。
不需要人為地拆分中間步驟。
在這種方式下,我們會對模型説:
“這是輸入 \(x\),這是輸出 \(y\)。
中間怎麼處理?你自己學。”
就像只給學生看大量的“題目 → 答案”
卻完全不教任何運算規則。
模型必須自己推理出所有隱含的步驟,並在內部構建出自己的處理流程。
這種方式就是:端到端學習(End-to-End Learning)
我們來看看課程中一些實際應用的例子,看看端對端學習的適用情況和領域。
2. 端對端學習在什麼時候適用?
我們舉兩個例子來説明這個問題。
2.1 門禁系統的面部識別
先來看看非端對端邏輯下的門禁系統要經過什麼樣的步驟:
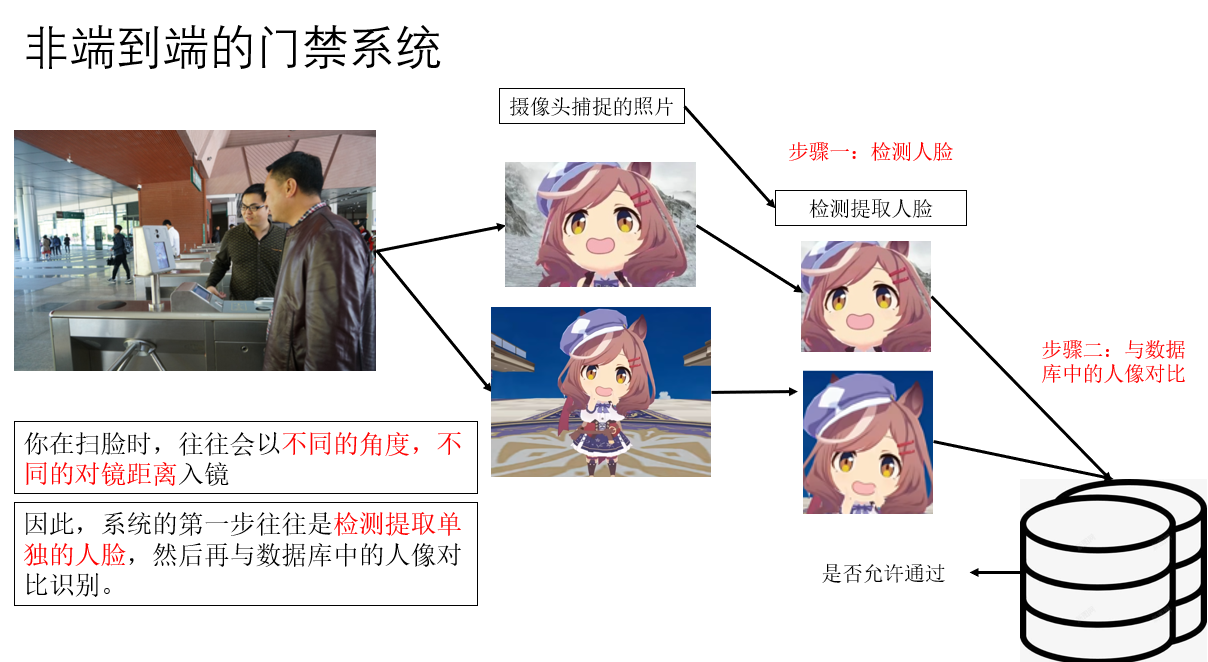
一般來説,我們在這種系統錄入的都是證件照,也就是較為精美的正面照。
但是,很顯然,在真實掃臉中我們不會這麼標準,這就像我們之前常常提到的分佈不同問題,會很大程度影響模型的實用性。
因此,“檢測人臉”這一步是我們根據正常邏輯加入的,是我們為了幫助提高擬合手動設計的步驟。
我們可以訓練兩個模型來實現這個系統:
- 從不同角度、距離的人臉檢測模型。
- 檢測到的人臉與數據庫的對比識別模型。
當然,這只是一個示例,也有其他的方法和技術。
現在,再來看看端對端邏輯下的系統實現:
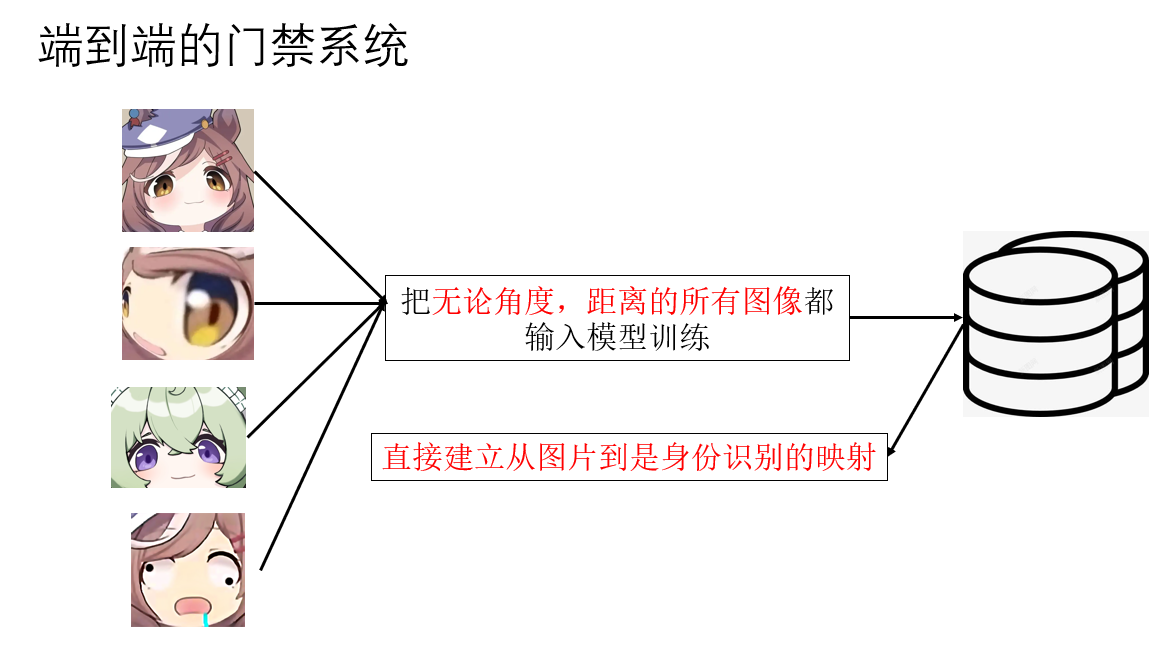
很顯然,要想實現端對端學習,最重要的前提就是極大規模的數據集。
而實際上,在門禁系統中,上面這種非端對端的學習方式反而更好,為什麼?
我們來看看二者的對比,歸根到底,還是數據問題。
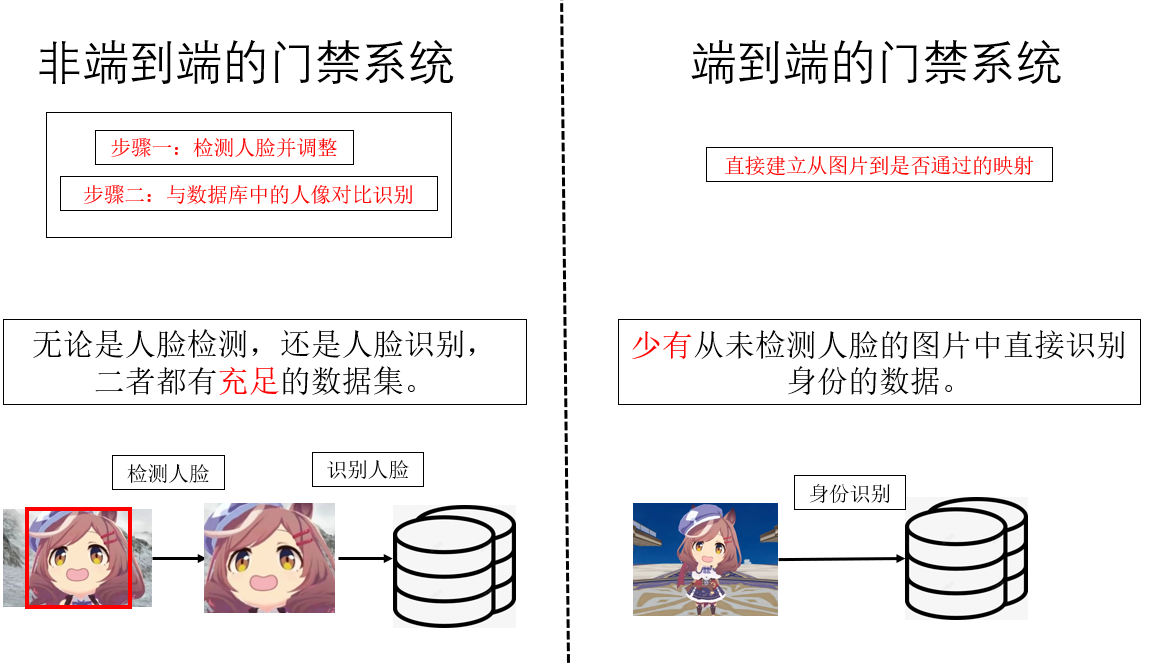
因此,在數據量不足的情況下,傳統非端對端的學習方式反而效果更好。
那端對端有什麼較為突出的應用領域嗎?有的兄弟,有的。
我們繼續下一個例子。
2.2 語言翻譯
如果我們人工把中文翻譯成英文,你在腦海可能會一個個拼出每個字對應的英文單詞再組合。
為什麼説在這個領域端對端學習更好,很簡單,數據容易獲取。
你在翻譯軟件輸入一句中文並翻譯成英文,好了,現在你已經得到一個樣本和其相應的標籤了。
這樣,模型可能不理解單個英文字母是什麼,不理解具體的語言邏輯,但是它就是可以通過自己的學習方式進行翻譯。
顯然,這得益於海量的數據支持。
3. 端對端學習的優缺?
端到端學習聽起來很“酷”,直接輸入 \(x\),直接輸出 \(y\),就像魔法一樣。但任何技術都有兩面,端到端學習也一樣。
最後我們通過對比來看看它的優缺點,也當作是對它的總結。
| 項目 | 端到端學習(End-to-End) | 傳統分步驟方法(Pipeline) |
|---|---|---|
| 設計複雜度 | 結構簡單,不需要人為拆分步驟 | 需要人工劃分多步驟、設計特徵 |
| 對數據的依賴 | 極強,需要海量數據 | 數據需求較少,模塊可分開訓練 |
| 整體性能 | 可達到更好的“全局最優” | 可能受制於每個子模塊的局部最優 |
| 可解釋性 | 差,內部邏輯是黑箱 | 好,每個步驟都可觀察、可調試 |
| 調試難度 | 高,出錯很難定位 | 低,可逐個模塊定位問題 |
| 魯棒性(分佈變化) | 容易受到數據分佈偏差影響 | 更穩,因為每步可強制規則約束 |
| 適用場景 | 翻譯、語音識別等“數據巨大”的任務 | 醫療影像、人臉識別等數據有限任務 |