

此分類用於記錄吳恩達深度學習課程的學習筆記。
課程相關信息鏈接如下:
- 原課程視頻鏈接:[雙語字幕]吳恩達深度學習deeplearning.ai
- github課程資料,含課件與筆記:吳恩達深度學習教學資料
- 課程配套練習(中英)與答案:吳恩達深度學習課後習題與答案
本篇為第五課第二週的課後習題和代碼實踐部分。
1. 理論習題
【中英】【吳恩達課後測驗】Course 5 -序列模型 - 第二週測驗
本週習題同樣較為簡單,就不再展開了。
2. 代碼實踐
詞向量與Emoji生成器-CSDN博客
在本週的編程作業裏,鏈接裏的博主除了編碼演示關於詞向量的一些基本應用外,主要是實現了一個表情生成器。
其原理是通過文本和相應的表情標籤進行監督學習,構建分類模型,在完成訓練後,通過對模型輸出的下游加工,可以實現“輸入文本,輸出配有表情的文本”的效果。感興趣可以進入瞭解。
同樣,我們還是使用成熟框架來演示本週的內容,得益於 PyTorch 對基礎模塊的封裝非常完善,我們可以較簡潔地完成本週內容的演示,主要內容列舉如下:
- 如何在代碼中使用詞嵌入?
- 使用詞向量取代獨熱編碼對命名實體識別模型性能的影響。
- 使用詞向量進行情緒分類。
2.1 在PyTorch 中使用詞嵌入
在 PyTorch 調用詞嵌入的方法被封裝在模型模塊中,就像我們調用方法創建全連接層和卷積層一樣,現在,我們要做的就是創建嵌入層。
先來單獨看看創建嵌入層的方法本身:
self.embedding = nn.Embedding(
num_embeddings=vocab_size, # 詞典大小
embedding_dim=embed_dim, # 詞向量維度,既一個詞用多少維的向量表示。
# 上面這兩個參數就劃定好了詞嵌入矩陣的大小。
padding_idx=word_vocab["<PAD>"] # 獲取填充符索引,固定其向量為 0 ,並屏蔽梯度計算。
)
這裏有一點需要強調,如果你對我們上週的實踐內容還有印象,會發現我們其實已經在前面的代碼了顯式定義了 <PAD> 的索引:
word_vocab["<PAD>"] = 0
也就是説,在方法的參數裏,我們可以直接寫成:
padding_idx= 0
但是,我們基本不會這麼做。
這其實是代碼規範裏一個老生常談的問題:避免硬編碼。
在這裏,一旦詞表構建策略發生調整(例如交換 <PAD> 與 <UNK> 的索引),參數就會被錯誤使用,卻不會觸發任何報錯,最終導致模型在訓練過程中學到錯誤的表示。
因此,我們在實踐中更傾向使用統一的變量,來顯式表達語義依賴,避免在調整時引入隱蔽錯誤。
回到正題,瞭解了嵌入層方法本身後,現在就來看看如何將其應用在模型中,先看看我們上週使用獨熱編碼的模型代碼:
class RNNTagger(nn.Module):
def __init__(self, vocab_size, hidden_dim, num_classes,
rnn_type='RNN', bidirectional=False, num_layers=1):
super().__init__()
self.vocab_size = vocab_size
self.bidirectional = bidirectional
self.rnn_type = rnn_type.upper()
input_size = vocab_size # 獨熱編碼輸入維度 = 詞表大小
if self.rnn_type == 'RNN':
self.rnn = nn.RNN(input_size, hidden_dim, batch_first=True,
bidirectional=bidirectional, num_layers=num_layers)
......其他模型選擇
self.fc = nn.Linear(hidden_dim * (2 if bidirectional else 1), num_classes)
def forward(self, x):
x_onehot = torch.nn.functional.one_hot(x, num_classes=self.vocab_size).float() # 傳播第一步,將輸入從索引轉換為獨熱編碼。
out, _ = self.rnn(x_onehot)
out = self.fc(out)
return out
而把使用獨熱編碼改為使用詞向量的工作量也並不大,我們需要:
- 新增參數定義詞向量維度。
- 創建嵌入層。
- 在傳播的第一步將索引從轉換為獨熱編碼改為輸入嵌入層提取詞向量。
更改完的代碼如下:
class RNNTagger(nn.Module):
def __init__(self, vocab_size, hidden_dim, num_classes,
rnn_type='RNN', bidirectional=False, num_layers=1,
embed_dim=300): # ← 新增一個嵌入維度參數
super().__init__()
self.bidirectional = bidirectional
self.rnn_type = rnn_type.upper()
# 新增:詞嵌入層
self.embedding = nn.Embedding(
num_embeddings=vocab_size,
embedding_dim=embed_dim,
padding_idx=word_vocab["<PAD>"]
)
input_size = embed_dim # ← RNN 輸入改為 embedding 維度
if self.rnn_type == 'RNN':
self.rnn = nn.RNN(input_size, hidden_dim, batch_first=True,
bidirectional=bidirectional, num_layers=num_layers)
elif self.rnn_type == 'LSTM':
self.rnn = nn.LSTM(input_size, hidden_dim, batch_first=True,
bidirectional=bidirectional, num_layers=num_layers)
elif self.rnn_type == 'GRU':
self.rnn = nn.GRU(input_size, hidden_dim, batch_first=True,
bidirectional=bidirectional, num_layers=num_layers)
else:
raise ValueError("rnn_type must be 'RNN','LSTM','GRU'")
self.fc = nn.Linear(hidden_dim * (2 if bidirectional else 1), num_classes)
def forward(self, x):
x_embed = self.embedding(x) #在傳播中首先輸入嵌入層提取詞向量。
out, _ = self.rnn(x_embed)
out = self.fc(out)
return out
這樣,只需要在模型部分完成改動,我們便可以直接應用上週的代碼框架直接進行訓練。
下面就來看看效果:
2.2 使用詞嵌入進行命名實體識別
我們先使用普通的雙向 RNN 來看看效果,多次實驗部分結果如下:

可以看出,相比獨熱編碼,雖然在指標上並沒有明顯的提升,但是使用 300 維的詞向量完成相同的訓練,只需要獨熱編碼訓練用時的約 65% ,這種優勢會隨着詞表規模增加而更明顯。
顯然,詞向量避免了獨熱編碼向量的極高維度且極其稀疏缺陷,這是在計算性能上的極大提升。
簡單打印一些訓練後的詞向量如下:(只截取了前 20 維)

然後,我們再試試上週綜合表現最好的 GRU ,結果如下:
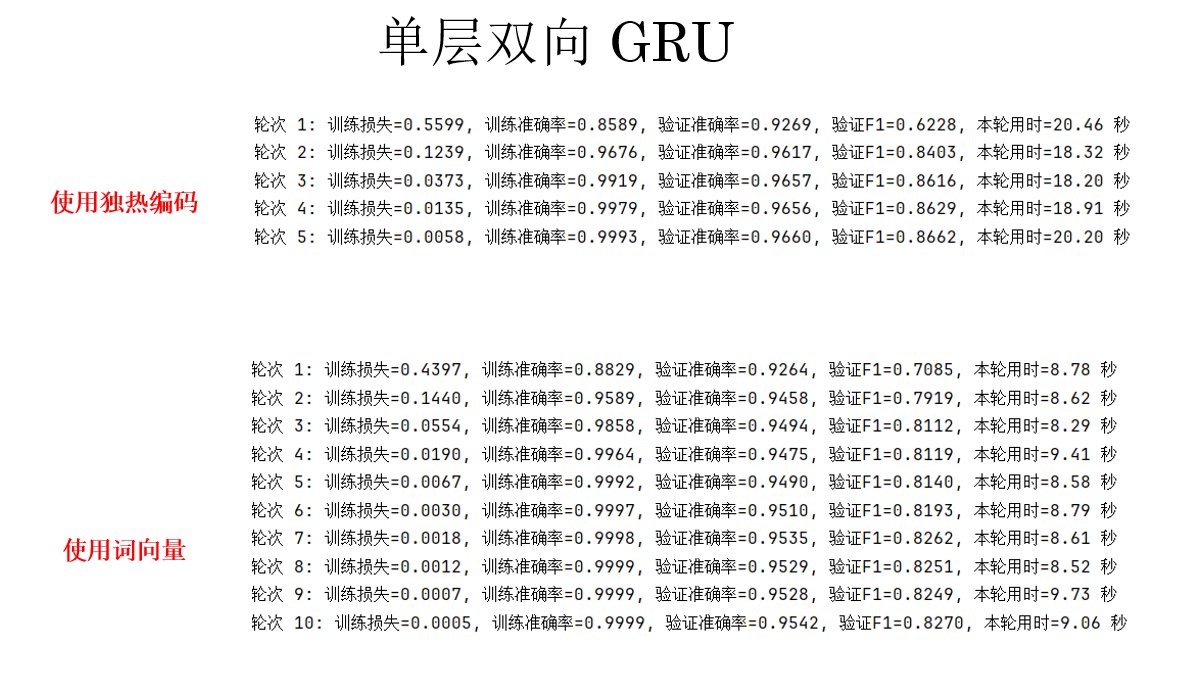
訓練用時同樣得到了極大提升,但是,好像出現問題了:
在使用了詞嵌入後,明明還增加了訓練輪次,但指標反而不如使用獨熱編碼高,這是為什麼?
實際上,詞嵌入並不天然適用於所有 NLP 任務。對於實體命名識別這類以詞和標籤強對齊為主的任務,one-hot 表示由於其完全區分詞身份的特性,反而可能取得更好的效果。
説簡單些,由於命名實體識別任務更關注“這個詞是什麼”,而不是“詞之間的關係”,使用完全正交的獨熱編碼反而讓界限更明顯。
來簡單看個例子:
假設在訓練語料中,Apple 大量以 B-ORG(組織)標籤出現,而 Google、Microsoft 等詞在詞嵌入空間中與 Apple 距離很近,這是因為它們共享了“公司”“科技”“產品”等相似上下文。但在具體句子中:
Apple released a new product.→Apple是ORG(蘋果公司)I ate an apple after lunch.→apple是O(食物蘋果)
對於 NER 來説,關鍵不是“這個詞在語義上像什麼”,而是在當前任務標註體系下,它在這個位置對應什麼標籤。
而詞嵌入會引入一種強烈的歸納偏置:語義相近的詞,其表示也應當相近。當模型的上下文建模能力有限時,這種相似性結構可能被過度利用,使模型傾向於根據詞向量的鄰近關係做出判斷,而不是嚴格依賴監督信號本身,從而在某些語境下產生錯誤的實體類型預測。
比如詞嵌入會天然鼓勵模型將 Apple 與其他科技公司詞拉近,從而放大“公司語義”的共性,而如果模型設計對大小寫不敏感,另外的部分語料裏又讓水果間的距離更近,就可能導致 “香蕉公司”,“菠蘿公司” 等錯誤識別。
而在 one-hot 表示下,Apple 的表示與任何其他詞完全獨立,模型只能依賴監督信號本身去學習它在不同上下文中與標籤之間的對應關係,反而避免了這種誤解。
總結來説,在不進行進一步上下文建模或結構化約束的情況下,詞嵌入由於為多義詞提供了共享的連續表示,可能在某些任務中引入語義混淆,從而影響模型對具體標籤的判別。
而 one-hot 表示通過其完全正交的設計,顯式區分了不同詞項的身份,在詞—標籤強對齊的任務中反而在一定程度上緩解這一問題。
現在,我們在詞嵌入的強項:情緒分類上再來看看其效果:
2.3 使用詞向量進行情緒分類
要進行新的任務,自然首先要引入新的數據集,這裏我們使用情緒分類中的經典數據集:IMDb
IMDb 數據集是一個經典的二分類情緒分析任務數據集,它的輸入是電影評論文本,輸出是情緒標籤,0 表示負面(negative),1 表示正面(positive)。
訓練集和測試集各包含 25,000 條評論,評論長度不固定,從幾十詞到幾百詞不等,文本中包含標點、大小寫、數字等元素。數據類別平衡。比較適合我們的演示。
同樣,我們使用之前介紹過的 HuggingFace Datasets 來下載,完整代碼附在最後,這裏展示幾條樣本數據:

現在,同樣使用 單層雙向 GRU 來進行實驗,設置詞表大小為 20000,批次大小為 32,部分訓練結果如下:
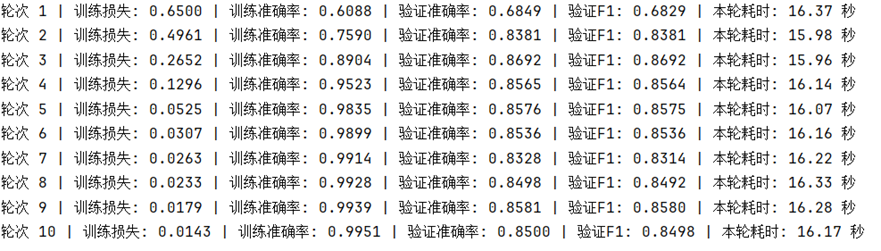
可以在較少的輪次中,實現較好的擬合。
而在同等參數下使用獨熱編碼則會爆內存,以我的電腦配置需要將詞表縮小到 5000 以下,並將批次大小降至 6,才勉強可以運行且單輪時間較長,這樣的配置並不適配一般的使用場景,因此就不再展示獨熱編碼的效果了。
詞向量在計算效率與大詞表適應性上擁有極大優勢,可以在保持模型性能的同時,大幅降低顯存消耗與訓練時間。
如果你的資源足夠,可以進行更多的嘗試看看效果。
3. 附錄
3.1 使用詞嵌入進行情緒分類 PyTorch版
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torch.nn.utils.rnn import pad_sequence
from datasets import load_dataset
from collections import Counter
from sklearn.metrics import accuracy_score, f1_score
import time
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
dataset = load_dataset("mteb/imdb")
train_data = dataset['train']
test_data = dataset['test']
def build_vocab(dataset, max_vocab_size=5000):
counter = Counter()
for item in dataset:
counter.update(item['text'].split())
most_common = counter.most_common(max_vocab_size)
word_vocab = {w:i+2 for i,(w,_) in enumerate(most_common)}
word_vocab["<PAD>"] = 0
word_vocab["<UNK>"] = 1
return word_vocab
word_vocab = build_vocab(train_data)
vocab_size = len(word_vocab)
def encode(item):
x = torch.tensor([word_vocab.get(w,1) for w in item['text'].split()], dtype=torch.long)
y = torch.tensor(item['label'], dtype=torch.long)
return x, y
train_dataset = [encode(item) for item in train_data]
test_dataset = [encode(item) for item in test_data]
def collate_fn(batch):
xs, ys = zip(*batch)
xs_pad = pad_sequence(xs, batch_first=True, padding_value=word_vocab["<PAD>"])
ys = torch.tensor(ys, dtype=torch.long)
return xs_pad.to(device), ys.to(device)
train_loader = DataLoader(train_dataset, batch_size=6, shuffle=True, collate_fn=collate_fn)
test_loader = DataLoader(test_dataset, batch_size=6, shuffle=False, collate_fn=collate_fn)
class GRUSentiment(nn.Module):
def __init__(self, vocab_size, hidden_dim, num_classes,
bidirectional=True, embed_dim=300):
super().__init__()
self.bidirectional = bidirectional
self.embedding = nn.Embedding(vocab_size, embed_dim, padding_idx=0)
self.rnn = nn.RNN(embed_dim, hidden_dim, batch_first=True,
bidirectional=bidirectional, num_layers=1)
self.fc = nn.Linear(hidden_dim * (2 if bidirectional else 1), num_classes)
def forward(self, x):
x = self.embedding(x)
out, _ = self.rnn(x)
if self.bidirectional:
out = torch.cat([out[:, -1, :self.rnn.hidden_size],
out[:, 0, self.rnn.hidden_size:]], dim=1)
else:
out = out[:, -1, :]
out = self.fc(out)
return out
def train_validate(model, train_loader, test_loader, epochs=3, lr=0.001):
model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
for epoch in range(epochs):
model.train()
total_loss = 0
total_correct = 0
total_tokens = 0
start_time = time.time()
for x_batch, y_batch in train_loader:
optimizer.zero_grad()
outputs = model(x_batch)
loss = criterion(outputs, y_batch)
loss.backward()
optimizer.step()
total_loss += loss.item()
preds = outputs.argmax(dim=-1)
total_correct += (preds == y_batch).sum().item()
total_tokens += y_batch.numel()
train_acc = total_correct / total_tokens
avg_loss = total_loss / len(train_loader)
# 驗證
model.eval()
all_preds, all_labels = [], []
val_total_correct = 0
val_total_tokens = 0
with torch.no_grad():
for x_batch, y_batch in test_loader:
outputs = model(x_batch)
preds = outputs.argmax(dim=-1)
all_preds.extend(preds.cpu().tolist())
all_labels.extend(y_batch.cpu().tolist())
val_total_correct += (preds == y_batch).sum().item()
val_total_tokens += y_batch.numel()
val_acc = val_total_correct / val_total_tokens
val_f1 = f1_score(all_labels, all_preds, average='macro')
epoch_time = time.time() - start_time
print(
f"輪次 {epoch+1} | " f"訓練損失: {avg_loss:.4f} | " f"訓練準確率: {train_acc:.4f} | " f"驗證準確率: {val_acc:.4f} | " f"驗證F1: {val_f1:.4f} | " f"本輪耗時: {epoch_time:.2f} 秒"
)
print("\n訓練完成!")
print(f"最終驗證準確率: {val_acc:.4f}, F1-macro: {val_f1:.4f}")
return model
if __name__ == "__main__":
model = GRUSentiment(
vocab_size=vocab_size,
hidden_dim=128,
num_classes=2,
bidirectional=True,
embed_dim=300
)
model = train_validate(model, train_loader, test_loader, epochs=10, lr=0.001)
3.2 使用詞嵌入進行情緒分類 TF版
import tensorflow as tf
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.utils import to_categorical
from datasets import load_dataset
from collections import Counter
import numpy as np
import time
device = "GPU" if tf.config.list_physical_devices('GPU') else "CPU"
dataset = load_dataset("mteb/imdb")
train_data = dataset['train']
test_data = dataset['test']
def build_vocab(dataset, max_vocab_size=5000):
counter = Counter()
for item in dataset:
counter.update(item['text'].split())
most_common = counter.most_common(max_vocab_size)
word_vocab = {w:i+2 for i,(w,_) in enumerate(most_common)}
word_vocab["<PAD>"] = 0
word_vocab["<UNK>"] = 1
return word_vocab
word_vocab = build_vocab(train_data, max_vocab_size=20000)
vocab_size = len(word_vocab)
print("詞表大小:", vocab_size)
def encode(item):
x = [word_vocab.get(w, 1) for w in item['text'].split()]
y = item['label']
return x, y
train_encoded = [encode(item) for item in train_data]
test_encoded = [encode(item) for item in test_data]
max_len = 200 X_train = pad_sequences([x for x, _ in train_encoded], maxlen=max_len, padding='post', truncating='post')
y_train = np.array([y for _, y in train_encoded])
X_test = pad_sequences([x for x, _ in test_encoded], maxlen=max_len, padding='post', truncating='post')
y_test = np.array([y for _, y in test_encoded])
def build_model(vocab_size, embed_dim=300, hidden_dim=128, bidirectional=True, num_classes=2):
inputs = tf.keras.Input(shape=(max_len,), dtype=tf.int32)
x = tf.keras.layers.Embedding(input_dim=vocab_size, output_dim=embed_dim, mask_zero=True)(inputs)
if bidirectional:
x = tf.keras.layers.Bidirectional(tf.keras.layers.GRU(hidden_dim))(x)
else:
x = tf.keras.layers.GRU(hidden_dim)(x)
outputs = tf.keras.layers.Dense(num_classes, activation='softmax')(x)
model = tf.keras.Model(inputs, outputs)
return model
model = build_model(vocab_size=vocab_size, embed_dim=300, hidden_dim=128, bidirectional=True, num_classes=2)
model.compile(optimizer=tf.keras.optimizers.Adam(0.001),
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.summary()
start_time = time.time()
history = model.fit(X_train, y_train, validation_data=(X_test, y_test),
epochs=10, batch_size=32)
total_time = time.time() - start_time
print(f"訓練完成,用時 {total_time:.2f} 秒")
y_pred = np.argmax(model.predict(X_test), axis=1)
from sklearn.metrics import f1_score
f1 = f1_score(y_test, y_pred, average='macro')
acc = np.mean(y_pred == y_test)
print(f"驗證準確率: {acc:.4f}, F1-macro: {f1:.4f}")