

此分類用於記錄吳恩達深度學習課程的學習筆記。
課程相關信息鏈接如下:
- 原課程視頻鏈接:[雙語字幕]吳恩達深度學習deeplearning.ai
- github課程資料,含課件與筆記:吳恩達深度學習教學資料
- 課程配套練習(中英)與答案:吳恩達深度學習課後習題與答案
本篇為第五課第三週的內容,3.7到3.8的內容。
本週為第五課的第三週內容,與 CV 相對應的,這一課所有內容的中心只有一個:自然語言處理(Natural Language Processing,NLP)。
應用在深度學習裏,它是專門用來進行文本與序列信息建模的模型和技術,本質上是在全連接網絡與統計語言模型基礎上的一次“結構化特化”,也是人工智能中最貼近人類思維表達方式的重要研究方向之一。
這一整節課同樣涉及大量需要反覆消化的內容,橫跨機器學習、概率統計、線性代數以及語言學直覺。
語言不像圖像那樣“直觀可見”,更多是抽象符號與上下文關係的組合,因此理解門檻反而更高。
因此,我同樣會儘量補足必要的背景知識,儘可能用比喻和實例降低理解難度。
本週的內容關於序列模型和注意力機制,這裏的序列模型其實是指多對多非等長模型,這類模型往往更加複雜,其應用領域也更加貼近工業和實際,自然也會衍生相關的模型和技術。而注意力機制則讓模型在長序列中學會主動分配信息權重,而不是被動地一路傳遞。二者結合,為 Transformer 等現代架構奠定了基礎。
本篇的內容關於注意力機制,這是如今 NLP 乃至整個深度學習領域的核心技術之一。
1.注意力機制的思想
1.1 傳統編碼解碼框架的侷限
在前面的編碼解碼架構中我們已經瞭解到: 編碼器的任務是將整個輸入序列映射為一個固定長度的向量表示,而解碼器則在此基礎上逐步生成輸出序列。
也就是説,無論編碼器採用的是 RNN、LSTM 還是 GRU,其最終都需要將長度可變的輸入序列壓縮為一個定長表示。
這種設計在形式上簡潔,但在實際使用中很快暴露出一個問題,我們稱之為 信息瓶頸(information bottleneck)。
即當輸入序列較長、結構較複雜時,這種“整體壓縮—再逐步解碼”的方式不可避免地會丟失細節信息,且這種損失會隨着序列長度增長而被放大。
這不難理解,對比來説,就像我們去背課文,編碼就是記憶的過程,而解碼就是背誦的結果。顯然,要背的內容越長,複述起來就越困難。
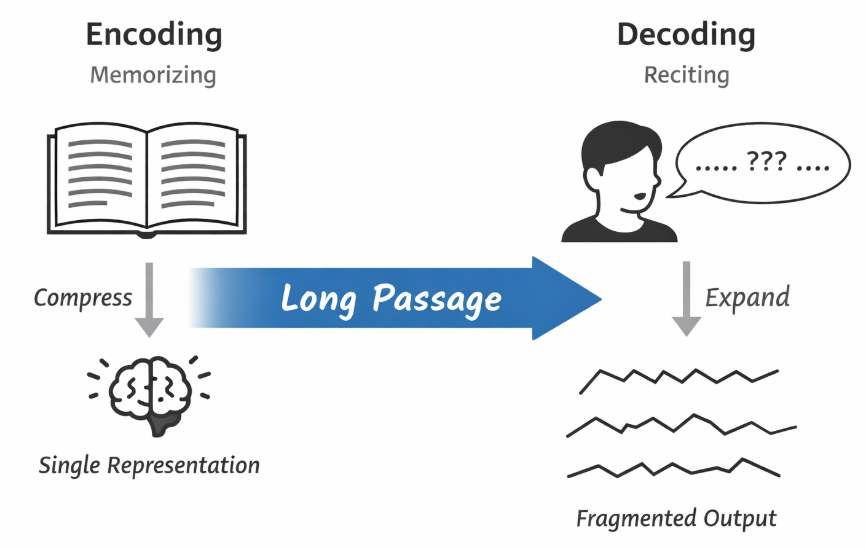
並且,這一框架仍存在我們之前在預測任務中提到過的問題:解碼器在生成每一個輸出詞時,使用的是整句內容,但在機器翻譯這類任務中,不同輸出位置所依賴的輸入信息顯然是不同的。
例如,在生成目標語言中的某個名詞時,真正相關的往往只是源語言中的局部片段,而非整句語義的表示結果。
正是在這一背景下,注意力機制被提出,其開創性工作在 2014 年發表的論文:Neural Machine Translation by Jointly Learning to Align and Translate。論文首次在編碼解碼框架中顯式引入“對齊(alignment)”的概念,使解碼器在每一個時間步都可以動態地從輸入序列中選擇相關信息,而不再依賴單一的全局向量表示。
1.2 注意力機制與 LSTM / GRU
在正式介紹注意力機制之前,有必要先進行一點概念上的澄清。
在剛剛的討論中我們提到,注意力機制的核心作用在於:使解碼器在每一個時間步,都可以動態地從輸入序列中選擇與當前輸出相關的局部信息。
乍一看,這一點似乎與我們此前在門控機制中介紹的 LSTM、GRU 的思想十分相似:它們都針對長序列情況,並同樣強調對信息的保留與遺忘。
但事實上,二者解決的是不同層面的問題。
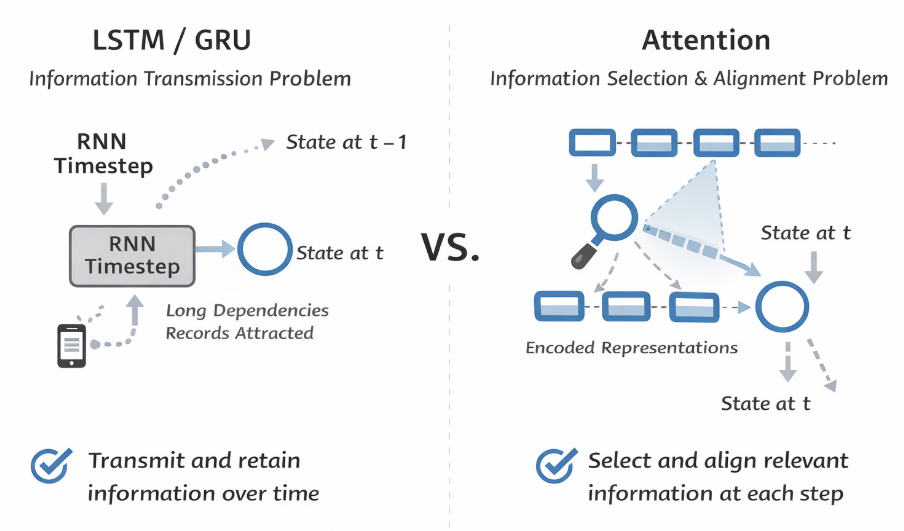
首先,LSTM 與 GRU 關注的是單個序列在時間維度上的狀態傳遞問題:在標準 RNN 中,隱藏狀態需要在時間步之間不斷遞推,長距離依賴往往會在傳播過程中被削弱甚至丟失。
門控機制正是為此而設計的:通過輸入門、遺忘門或更新門,模型可以決定哪些歷史信息應該被保留下來,哪些可以被丟棄。
因此,LSTM / GRU 回答的問題是:“當前時刻的隱藏狀態,應該如何從過去的狀態中更新而來?”
簡單點説,它們的工作是:如何得到更好的信息。
相比之下,注意力機制關注的並不是“狀態如何沿時間傳播”,而是已有信息如何被使用。
在編碼解碼框架中,編碼器已經生成了一整組隱藏狀態,用於刻畫輸入序列在各個位置上的表示。
而注意力機制所做的,是在解碼的每一個時間步,根據當前解碼狀態,在這組表示中顯式建模輸入與輸出之間的關聯關係,並據此對不同位置的信息進行聚合。最終得到”對當前步的輸出,哪些輸入更有用“。
總結一下:
- LSTM / GRU 解決的是信息如何在時間維度上傳遞與保存。
- 注意力機制解決的是在一組已有表示中,如何進行信息選擇與對齊。
也正因如此,在注意力機制最初被提出時,它並不是用來取代 LSTM 或 GRU 的,而是疊加在它們之上使用。
瞭解了注意力機制的原理後,現在就來看看其實現:
2.注意力機制的實現
從整體上看,注意力機制並沒有引入新的遞推結構,也不改變原有的編碼與解碼流程,而是在解碼的每一個時間步,引入了一次“基於當前狀態的信息檢索過程”。
這一過程的核心思想可以概括為三步:
- 度量相關性:計算當前解碼狀態與輸入序列中各個位置之間的匹配程度。
- 分配權重:將這些匹配程度歸一化,得到一組注意力權重。
- 加權匯聚:根據權重,對輸入表示進行加權求和,形成上下文向量。
下面我們依次展開:
2.1 對齊分數:如何度量“相關性”
首先,設編碼器對輸入序列產生了一組隱藏狀態:
其中 \(\mathbf{a}^{<i>}\) 表示輸入序列在第 \(i\) 個位置上的編碼表示。
同樣,對於解碼器,在解碼的第每一個時間步,同樣會產生隱藏狀態:
\(\mathbf{s}^{<t>}\) 表示在解碼的第 \(t\) 個時間步,解碼器當前的隱藏狀態。
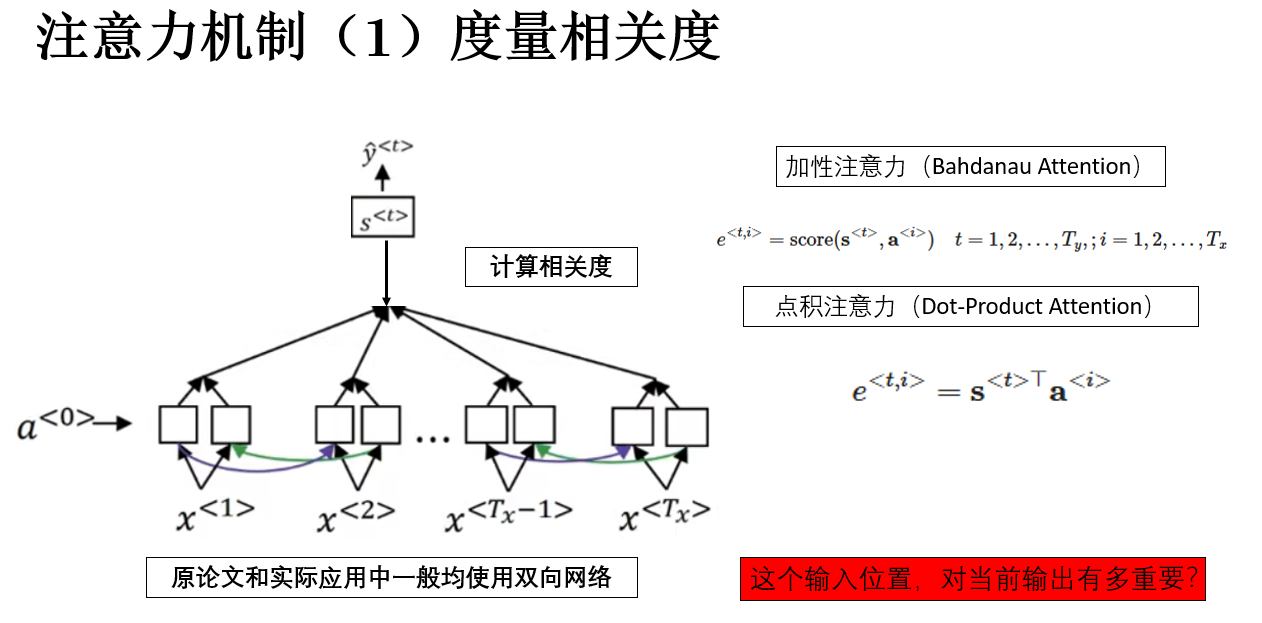
注意力機制的第一步,就是計算每一步解碼與每一步編碼之間的相關性分數,公式表示為:
其中,\(T_y\) 是輸出序列長度、\(T_x\) 是輸入序列長度。
這個 score 函數的具體形式並不是唯一的,它只需要滿足一個基本要求:能夠反映當前輸出狀態與某個輸入位置之間的匹配程度。
在原論文中,使用的是一個簡單的前饋網絡來完成這一部分:
其中 \(\mathbf{W}_s, \mathbf{W}_a, \mathbf{v}\) 為可學習參數,\(\mathbf{v}\) 的作用是通過向量內積將網絡輸出的向量映射為一個標量分數,來量化表示”相關性“。
另一種更簡單、計算效率更高的形式是直接使用向量內積:
當解碼器狀態與某個輸入位置的表示方向越接近,內積越大,對齊分數也就越高。
但無論採用哪一種形式,其語義都是一致的:這個輸入位置,對當前輸出有多重要?
來看一個實例:
假設輸入序列長度 \(T_x=3\),輸出序列長度 \(T_y=2\)。為了簡化,用 二維向量表示隱藏狀態:
- 編碼器隱藏狀態:
- 解碼器第 1 個時間步隱藏狀態:
- 解碼器第 2 個時間步隱藏狀態:
使用 點積注意力 計算對齊分數如下:
- 對 \(t=1\):
- 對 \(t=2\):
繼續下一步:
2.2 轉換注意力權重:從相關性到概率分佈
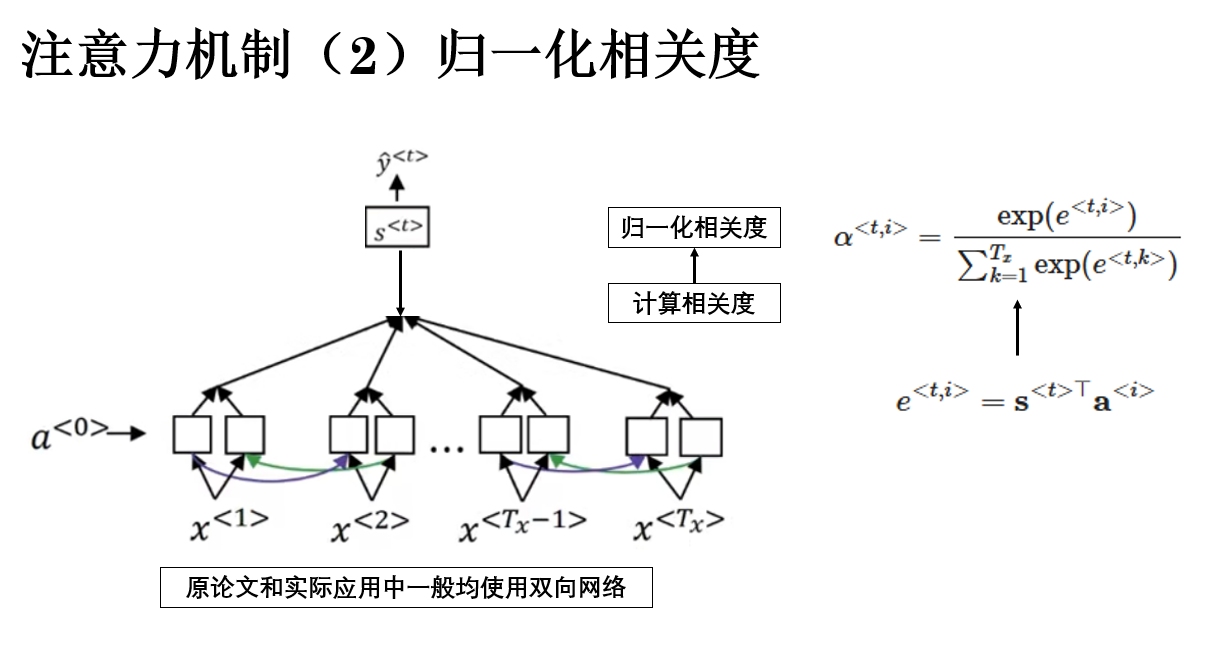
由於相關性分數本身並不具備可比性,下一步需要將其轉換為一組歸一化權重,最常見的做法,是在輸入維度上施加 softmax 操作:
此時,\(\alpha^{<t,i>}\) 可以被解釋為:在解碼第 \(t\) 個輸出時,對輸入位置 \(i\) 的注意力分配程度。
這一步並不複雜,使用 \(\exp\) 的作用是 是確保相關性為整數,並通過指數放大差異。
我們繼續剛剛的例子計算概率分佈如下:
| \(t\) | \(i\) | \(e^{<t,i>}\) | \(\exp(e^{<t,i>})\) | \(\sum_k \exp(e^{<t,k>})\) | \(\alpha^{<t,i>} = \frac{\exp(e^{<t,i>})}{\sum_k \exp(e^{<t,k>})}\) |
|---|---|---|---|---|---|
| 1 | 1 | 0.8 | 2.2255 | 6.1652 | 0.361 |
| 1 | 2 | 0.2 | 1.2214 | 6.1652 | 0.198 |
| 1 | 3 | 1.0 | 2.7183 | 6.1652 | 0.441 |
| 2 | 1 | 0.1 | 1.1052 | 6.2831 | 0.176 |
| 2 | 2 | 0.9 | 2.4596 | 6.2831 | 0.391 |
| 2 | 3 | 1.0 | 2.7183 | 6.2831 | 0.433 |
這樣,每個 \(\alpha^{<t,i>}\) 都是一個 非負數,且行內總和為 1,並且指數函數放大了較大的 \(e^{<t,i>}\),弱化了較小的 \(e^{<t,i>}\),保證注意力更集中在相關位置。
最終,歸一化後得到的 \(\alpha^{<t,i>}\) 就是 解碼器在第 \(t\) 步對輸入第 \(i\) 個位置的關注權重。
下面就是最後一步:
2.3 生成上下文向量
有了注意力權重 \(\alpha^{<t,i>}\) 後,下一步就是根據這些權重對編碼器的隱藏狀態進行加權求和,得到一個上下文向量(context vector),用於輔助解碼器生成當前輸出。
公式如下:
其中:
- \(\mathbf{c}^{<t>}\) 表示解碼器在第 \(t\) 個時間步的上下文向量;
- \(\alpha^{<t,i>}\) 是第 \(t\) 個輸出對第 \(i\) 個輸入位置的注意力權重;
- \(\mathbf{a}^{<i>}\) 是編碼器在第 \(i\) 個輸入位置的隱藏狀態。
通過公式就可以得到上下文向量的語義:解碼器在當前步“關注的輸入信息的加權平均”。 權重越高的輸入位置,對上下文的貢獻越大。
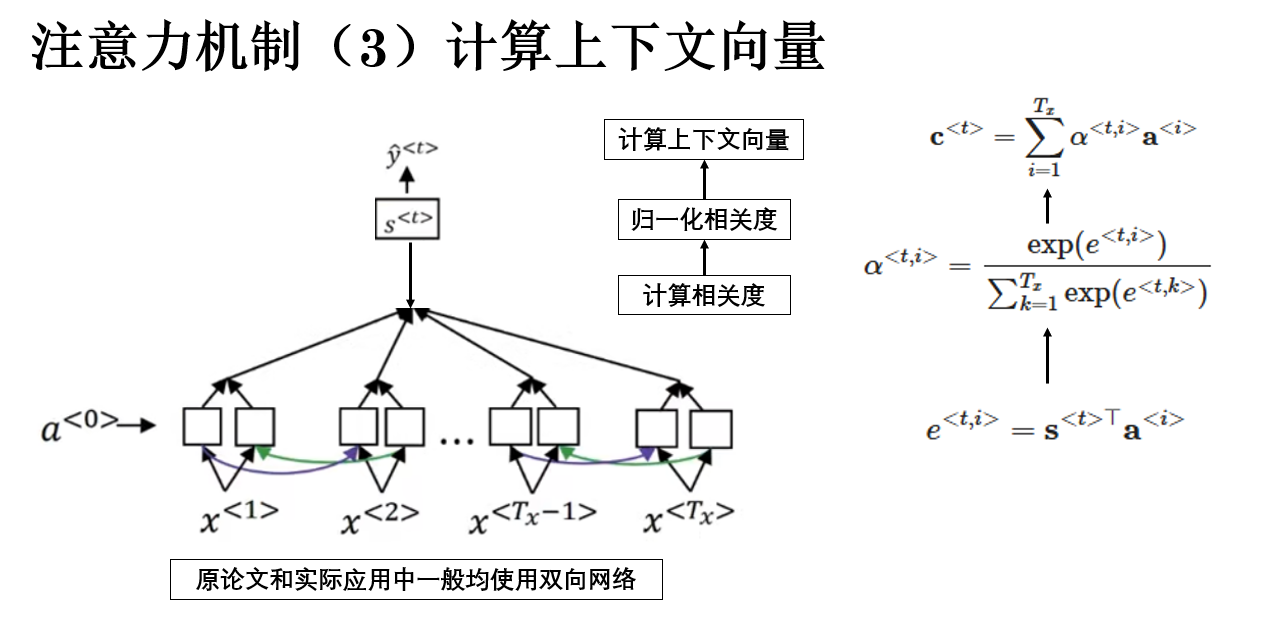
繼續例子:
- 對 \(t=1\):
- 對 \(t=2\):
這兩個上下文向量就可以與解碼器的隱藏狀態 \(\mathbf{s}^{<t>}\) 結合,作為生成最終輸出的依據。
2.4 輸出預測
在實際模型中,解碼器通常會將上下文向量與當前隱藏狀態拼接或通過線性變換融合:
然後再輸入到輸出層預測概率分佈:
最終:
- \(\tilde{\mathbf{s}}^{<t>}\) 是融合後的解碼器狀態。
- \(\mathbf{W}_c, \mathbf{W}_o, \mathbf{b}_o\) 是可學習參數。
- \(\hat{\mathbf{y}}^{<t>}\) 即該步最終輸出概率分佈。
這樣,我們就得到了加入注意力機制的序列模型的完整傳播過程:
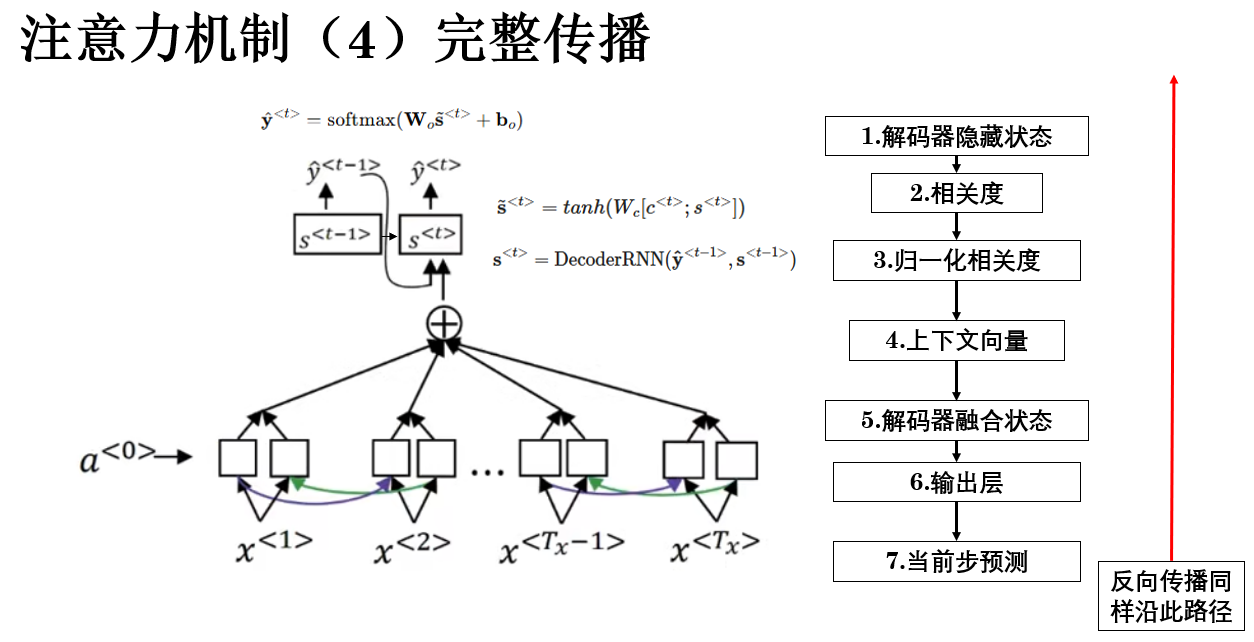
這樣,通過注意力機制,解碼器的參考就不僅僅是單一的整句向量,而是可以在傳播中,動態地學習到,哪些輸入對當前步更重要,從而提高模型性能。
在原始注意力機制之後,注意力的思想迅速發展併成為深度學習序列建模中的核心模塊。注意力機制的核心價值在於:動態分配信息權重,讓模型在處理長序列或複雜結構時,更加高效、可解釋、性能更強。這也是 Transformer 系列及大語言模型成功的基礎之一。
3. 總結
| 概念 | 原理 | 比喻 |
|---|---|---|
| 編碼解碼架構(Encoder-Decoder) | 將整個輸入序列壓縮為一個固定長度向量,解碼器基於該向量逐步生成輸出 | 背課文:記住整篇內容再複述,序列越長越難 |
| 信息瓶頸(Information Bottleneck) | 長序列或複雜結構在壓縮成定長表示時會丟失細節信息,損失隨長度增長被放大 | 背長篇課文容易遺漏細節 |
| 注意力機制(Attention) | 解碼器在每步動態從輸入序列中選擇與當前輸出相關的信息,通過計算相關性、歸一化權重、加權求和生成上下文向量 | 看書時只關注當前要回答的問題所在的段落,而不是整本書 |
| 對齊分數(Alignment Score) | 度量當前解碼狀態與輸入各位置的匹配程度,可用前饋網絡或向量點積實現 | 判斷哪段記憶對當前問題最相關 |
| 注意力權重(Attention Weights) | 將對齊分數通過 softmax 轉換為概率分佈,表示當前輸出對各輸入位置的關注程度 | 分配注意力資源:更重要的部分獲得更多關注 |
| 上下文向量(Context Vector) | 對輸入表示加權求和,得到解碼器當前步參考的綜合信息 | 當前問題的答案依賴的重點信息彙總 |
| 輸出預測 | 將上下文向量與解碼器隱藏狀態融合,輸入輸出層生成最終概率分佈 | 用精選的重點信息結合記憶生成回答 |
| 核心價值 | 動態分配信息權重,提高長序列處理能力和模型可解釋性 | 聚焦關鍵內容,避免整句或整篇平均處理導致效率低和信息丟失 |