

此分類用於記錄吳恩達深度學習課程的學習筆記。
課程相關信息鏈接如下:
- 原課程視頻鏈接:[雙語字幕]吳恩達深度學習deeplearning.ai
- github課程資料,含課件與筆記:吳恩達深度學習教學資料
- 課程配套練習(中英)與答案:吳恩達深度學習課後習題與答案
本篇為第四課的第二週內容,2.8到2.11的內容,同時也是本週理論部分的最後一篇。
本週為第四課的第二週內容,這一課所有內容的中心只有一個:計算機視覺。應用在深度學習裏,就是專門用來進行圖學習的模型和技術,是在之前全連接基礎上的“特化”,也是相關專業裏的一個重要研究大類。
這一整節課都存在大量需要反覆理解的內容和機器學習、數學基礎。 因此我會盡可能的補足基礎,用比喻和實例來演示每個部分,從而幫助理解。
第二週的內容是對一些經典網絡模型結構和原理的介紹,自然會涉及到相應的文獻論文。因此,我也會在相應的模型下附上提出該模型的論文鏈接。
這周的難點部分已經過去了,最後這部分是關於如何更好地使用本週以及之前瞭解過的模型的方法,即幾條方法論。
1. 尋找論文作者的開源項目代碼
在深度學習領域,尤其是 CV 和 NLP 方向,許多論文作者都會將實驗代碼開源,最常見的發佈平台就是 GitHub。
GitHub是目前世界上最大的代碼託管,交流平台。如果你不太瞭解它,站內站外都有大量的關於GitHub 的新手教學,這是相關專業裏幾乎所有人都要用到的一個平台。
我之前在介紹圖牀也使用了它來存儲圖片。
作者的源碼通常包含論文中使用的模型結構與訓練流程,但在具體細節方面可能因人而異,質量差異較大,需要結合論文與代碼共同理解。
顯然,站在巨人的肩膀上,要比我們自己一點點造輪子要快很多,當然,後者也是必要的能力。
通過閲讀作者源碼,我們可以理解很多論文中一筆帶過、但對性能影響巨大的工程細節和設計取捨,比如某個不起眼的參數設置。
實際操作時,一個常見流程是:
- 先在論文首頁或 arXiv 頁面查找是否附帶 GitHub 鏈接;
- 如果沒有,可以直接用「論文標題 + GitHub」進行搜索;
- 或查看作者個人主頁、實驗室主頁,很多都會集中維護代碼倉庫。
需要注意的是,搜索結果中也可能出現第三方復現代碼,這類代碼在工程上可能更規範,但不一定完全等價於論文原始實驗設置,使用時需要區分“作者官方實現”和“社區復現”。
以 ResNet 為例,其原論文作者及後續社區已經維護了多套高質量實現,目前常用版本也被集成進了 PyTorch / TensorFlow 官方模型庫中。
這是我的搜索的結果之一,是Deep Residual Learning for Image Recognition 的第一作者何愷明和其團隊對殘差網絡的的開源代碼,你可以點擊綠色的 Code 間選擇不同的方式把項目下載到本身。
相關教程有很多,具體操作流程這裏不再展開,以後如果有機會,我也希望能單獨出一個這方面的教程。
需要額外強調的一點是:雖然 GitHub 上目前已經有了大量的中文項目,但終究還是以英文為主,如果希望找到一些經典的出處,還是要掌握一定的英文能力。
而且GitHub 對國內的連接時常不穩定,有時需要“魔法”才能穩定進入。
因此,如果你平時有興趣瀏覽一些項目或者博客,但又受限於英文水平,GitHub中文社區也是一個不錯的選擇。不過在查找論文原始出處或權威實現時,仍建議以英文 GitHub 倉庫和作者主頁為準。
2. 應用遷移學習
實際上,我們在上一課的理論部分已經詳細展開過遷移學習了,並且在代碼實踐部分演示了ResNet-18 在我們一直使用的貓狗二分類數據集上的良好效果。
這裏我們再簡單展開一下:
在實際任務中,從零開始訓練一個模型,往往既慢又不穩定。
相比之下,使用已經訓練好的模型參數作為初始化,是目前更主流、也更現實的選擇。
在 CV 領域,許多模型已經在 ImageNet 等大規模數據集上完成了充分訓練,這些模型學到的底層特徵(邊緣、紋理、形狀)具有很強的通用性。
因此,即便你的任務和原始數據集並不完全一致,這些預訓練權重依然能作為一個很好的起點。
在演示部分我們也偶看到了,PyTorch 和 TF 都內置了可以調用預訓練模型的模塊與相應方法。
CV 領域已經形成了一批相對成熟、活躍的數據集平台與社區,因此,我們這裏補充幾個可以尋找數據集的平台,與遷移學習強強聯合達到更好的效果。(需要魔法)
(1)Kaggle Datasets
Kaggle 是目前最知名的機器學習競賽與社區平台之一,其 Datasets 板塊彙集了大量公開數據集,覆蓋圖像分類、目標檢測、醫學影像、遙感圖像等多個方向。
(2)Hugging Face Datasets
雖然 Hugging Face 最早以 NLP 聞名,但近年來其 Datasets 庫已經逐步覆蓋視覺領域。
(3)學術機構與官方數據集網站
對於一些經典任務,數據集往往直接由學術機構或研究團隊維護,例如:
- ImageNet
- CIFAR
- COCO
- Pascal VOC
3. 使用數據增強
同樣,對於數據增強,我們之前已經進行過理論介紹和實踐演示。
這裏再簡單補充一下:
數據增強並不是“造新數據”,而是通過對原始樣本進行合理擾動,迫使模型學習更穩健、更具泛化性的特徵。
常見的數據增強方式包括:
- 空間變換:隨機裁剪、翻轉、旋轉;
- 顏色變換:亮度、對比度、飽和度擾動;
這些操作的共同點在於:
它們不會改變樣本的語義標籤,但會打破模型對某些“表面規律”的依賴。
例如:
- 不再依賴固定位置;
- 不再依賴固定光照;
- 不再依賴單一顏色分佈。
在很多任務中,合理的數據增強帶來的收益,甚至不亞於更換模型結構,而且相比設計新網絡,它的實現成本往往更低。
在 PyTorch 中,數據增強通常作為 數據預處理流水線的一部分,通過 torchvision.transforms 在 訓練階段 作用於樣本,我們也不止一次演示過,相信你也並不陌生了。
4. 競賽策略
最後一點,更偏向方法論層面的提醒。
在學術競賽或榜單任務中,目標往往只有一個:性能最大化。
因此,我們簡單介紹兩個之前沒提到過的策略:多模型集成與多裁剪測試。
4.1 多模型集成(Ensemble)
多模型集成指的是: 在推理階段同時使用多個已經訓練完成的模型,對同一個輸入樣本進行預測,再對輸出結果進行融合(如取平均、加權平均或投票)。
就像這樣:
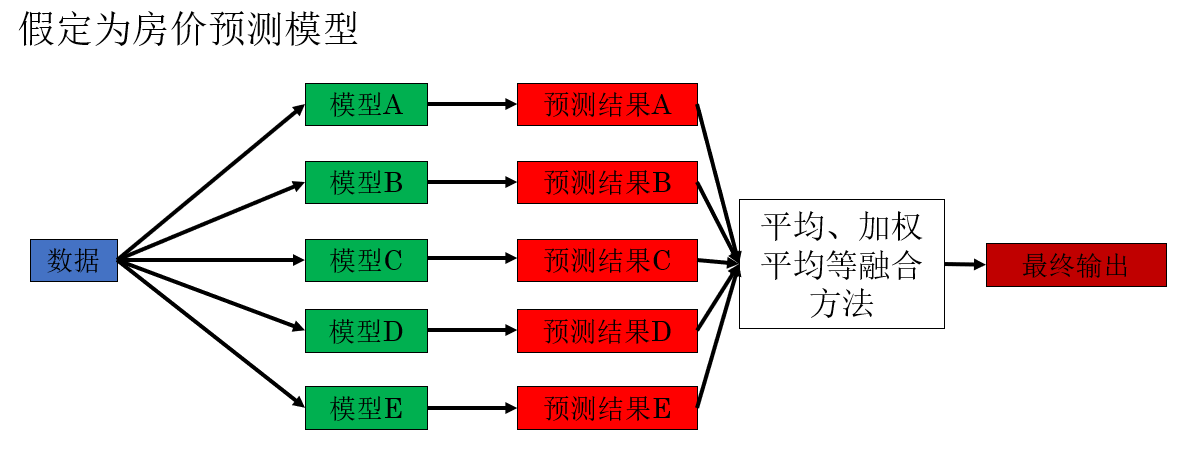
直觀理解很簡單: 不把決策權交給單一模型,而是讓多個模型共同“表決”。
具體來説,不同模型即使結構相同,只要訓練過程存在差異(初始化、數據順序、正則化方式等),其犯錯模式也往往不同,集成後,這些不一致的錯誤會被相互抵消,整體預測更加穩定。
從統計角度看,ensemble 的作用類似於降低模型預測的方差。
常見的集成方式有很多:
- 不同結構的模型集成;
- 同一結構、不同隨機種子的模型集成;
- 不同訓練輪次的模型集成。
4.2 多裁剪測試(Multi-crop)
多裁剪測試指的是: 在驗證或測試階段,對同一輸入圖像生成多個裁剪版本,分別送入模型預測,再對結果取平均。
以常見的 10-crop 為例:
- 對原圖進行中心裁剪和四角裁剪;
- 再對每個裁剪做一次水平翻轉;
- 共得到 10 個輸入視角。
就像這樣:

我們把一幅測試圖像裁剪成十份,再對它們取平均。
理論上講:單次裁剪可能恰好丟失關鍵信息,而多裁剪可以降低這種偶然性,不同裁剪在特徵層面的響應不同,取平均後結果更穩定。
而且這種方式不需要重新訓練模型,只在評估階段增加相應邏輯即可獲得收益。
4.3 競賽與實際部署
上面提到的方法在競賽環境下完全合理,這是因為在競賽環境中:響應時間往往不敏感,資源成本也不是首要約束,我們只關心最終指標。
但在真實部署場景中,情況往往完全不同:
- 響應延遲、顯存佔用、電力消耗都是硬約束;
- 模型需要穩定、可維護、可擴展;
- 很多競賽技巧在工程上並不划算,甚至不可用。
因此,一個非常重要的認知是: 競賽解法 ≠ 工業解法。
5.總結
| 概念 | 原理 | 比喻 |
|---|---|---|
| 查找論文作者的開源代碼 | 直接使用或參考作者官方實現,獲取完整模型結構、訓練流程與關鍵工程細節,避免僅憑論文文字復現造成偏差 | 看菜譜不如進後廚,看別人怎麼真正下鍋 |
| 官方實現 vs 社區復現 | 官方代碼最貼近論文實驗設置;社區復現可能更工程化,但不一定嚴格等價 | 原廠零件 vs 第三方兼容件 |
| 預訓練模型 | 底層卷積學到的邊緣、紋理、形狀具有跨任務泛化能力 | 已經練過基本功的運動員,換項目也更快上手 |
| 數據集平台 | Kaggle、Hugging Face、官方數據集網站集中提供標準化、可複用的數據資源 | 公共食材市場,不必自己從頭種菜 |
| 數據增強 | 對樣本做不改變語義的擾動,打破模型對錶面規律的依賴,提高泛化能力 | 讓學生在不同光線、角度下反覆看同一道題 |
| 多模型集成(Ensemble) | 多個模型共同預測,融合結果以抵消單模型的偶然錯誤,降低方差 | 多個評委投票,而不是一個人拍板 |
| 多裁剪測試(Multi-crop) | 對同一圖像從多個視角預測並取平均,降低單次裁剪信息缺失的風險 | 多看幾眼同一張照片再下結論 |
| 競賽策略 | 用計算資源換性能上限,推理成本不是首要約束 | 用錢和時間堆出最高分 |
| 工業部署 | 在延遲、顯存、功耗等約束下做整體權衡,強調穩定與可維護 | 在有限預算下裝修房子 |