

PageAttention原理分析
Page Attention也是一種優化方法(區別於MLA,page attention是對內存進行分配管理)。參考論文[1]中描述,對於KV-cache存在3個問題:

1、預留浪費 (Reserved):為將來可能的 token 預留的空間,這些空間被保留但暫未使用,其他請求無法使用這些預留空間;
2、內部內存碎片化問題(internal memory fragmentation):系統會為每個請求預先分配一塊連續的內存空間,大小基於最大可能長度(比如2048個token),但實際請求長度往往遠小於最大長度,這導致預分配的內存有大量空間被浪費。
3、外部內存碎片化問題(external memory fragmentation):不同內存塊之間的零散空閒空間,雖然總空閒空間足夠,但因不連續而難以使用。
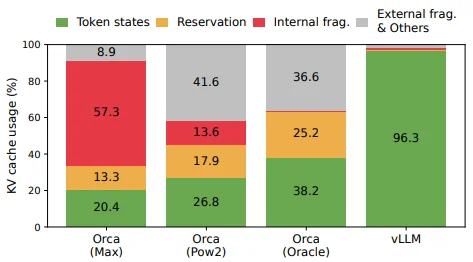
只有 20.4%-38.2% 的token是被使用的,大部分都被浪費掉了。Page Attention允許在非連續的內存空間中存儲連續的 key 和 value 。具體來説,Page Attention將每個序列的 KV-cache 劃分為塊,每個塊包含固定數量 token 的鍵和值。在注意力計算期間,Page Attention內核可以有效地識別和獲取這些塊。如何理解上面描述呢?還是借用論文中的描述:
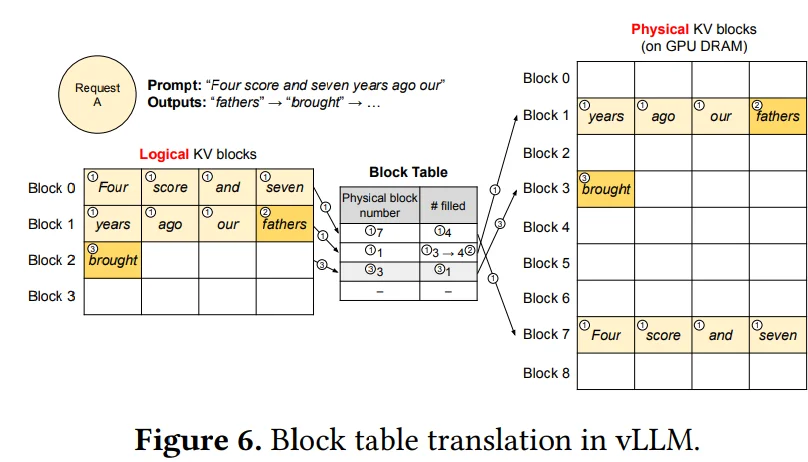
比如説按照上面Prompt要輸出(假設只輸出這些內容):“fathers brought a car”,一般的套路可能是:比如説:“Four score and seven years ago our xxxxx”(xxx代表預留空間)因為實際不知道到底要輸出多少文本,因此會提前預留很長的一部分空間(但是如果只輸出4個字符,這預留空間就被浪費了),因此在page attention裏面就到用一種“分塊”的思想處理,以上圖為例,分為8個Block每個Block只能存儲4個內容,因此就可以通過一個Block Table來建立一個表格告訴那些Block存儲了多少,存儲滿了就去其他Blobk繼續存儲。整個過程如下:
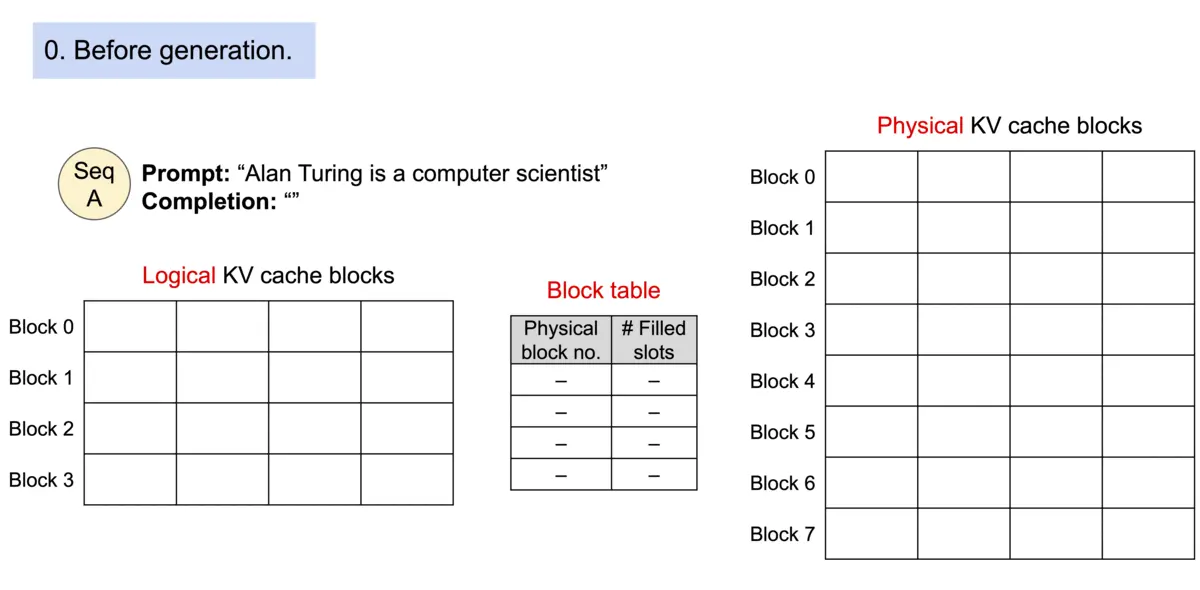
上述過程描述如下:具體而言,Page Attention 首先將 Key/Value 的連續顯存空間劃分為固定大小的 Block(頁),每個 Block 作為最小的內存分配與調度單元。隨後,引入一個 Block Table(頁表) 來維護邏輯序列位置與物理 Block 之間的映射關係,用於記錄每個 Block 當前的存儲狀態與可用容量。
一個小問題:分塊之後注意力計算過程,因為我的KV被存儲在不同的block中,由於Block table存在可以直接去索引不同Blcok中KV值,這樣一來對於Q、K、V三者計算不成問題,不過關鍵問題就是:Softmax 的分母需要全局信息,Block (不管是Flash Attn還是Page Attn都需要面對這個問題)是分開的,怎麼辦?
在softmax計算過程中:\(\sigma= \frac{e^{z_i}}{\sum_{j=1}^K e^{z_j}}\) 由於分塊可能導致值過小進而導致數值溢出問題,除此之外計算需要所有token的分數一起歸一化,因此首先會對上面的公式改進為:\(\sigma= \frac{e^{z_i-m}}{\sum_{j=1}^K e^{z_j-m}}\)也就是將每塊都去減去當前的最大值(避免溢出問題)。在處理全局問題上:只需要考慮兩個值的更新:1、當前最大值;2、歸一化因子(\(\sum_{j=1}^K e^{z_j-m}\))因此這個過程就可以處理為:
這樣一來就可以轉化為:\(l_{t+1}=l_t e^{m_t-m_{t+1}}+ \sum_{i\in B_{t+1}}e^{z_j- m_{t+1}}\)
基本使用方式
在使用vllm上有兩種方式:1、離線使用;2、在線使用(直接將使用過程轉化為調用API方式):
from vllm import LLM, SamplingParams
prompts = ["Hello, my name is",
"The president of the United States is",
"The capital of France is",
"The future of AI is",]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
llm = LLM(model="facebook/opt-125m")
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
vllm整體框架分析
基於:
Version: 0.11.0
在vllm中主要是兩種調用方式:1、離線調用;2、在線調用(這個就類似在本地啓動一個服務,而後其他及其直接訪問ip端口等進行訪問處理)
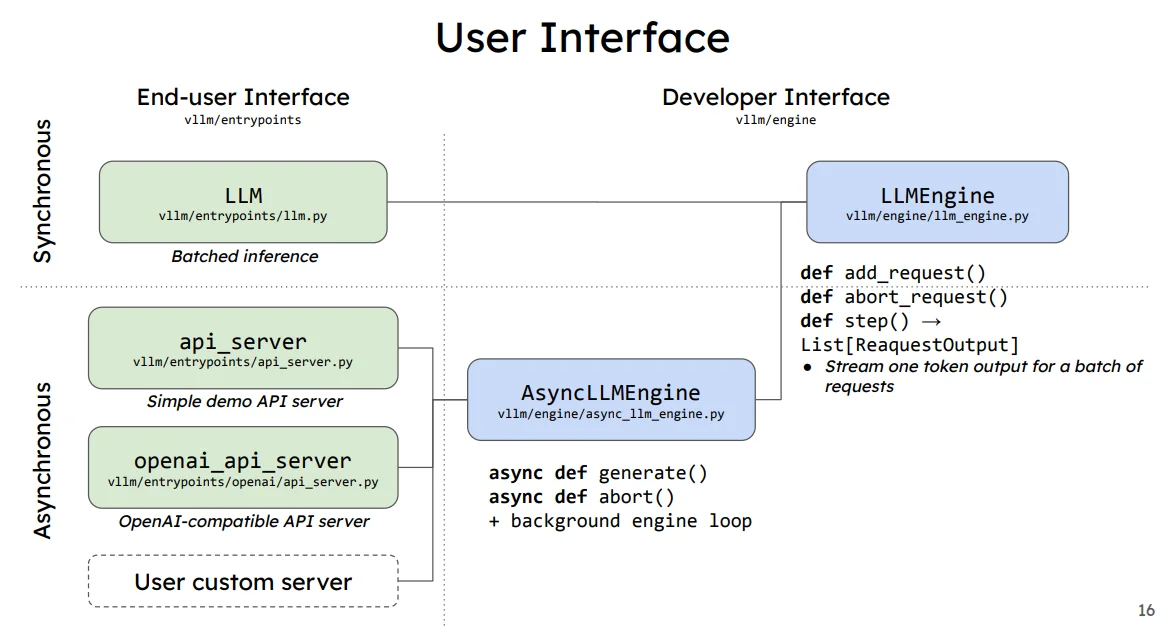
上圖中在線調用方式(Asy)和離線調用(Syn)
對於具體的
LLMEngine的結構描述見後面的描述
以離線調用方式進行解釋,直接使用官方代碼為例:
from vllm import LLM, SamplingParams
prompts = ["Hello, my name is",
"The president of the United States is",
"The capital of France is",
"The future of AI is",]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
llm = LLM(model="facebook/opt-125m")
outputs = llm.generate(prompts, sampling_params)
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
從上面代碼分析發現感覺和平時使用Transformer框架和相似:加載模型-->編碼輸入-->輸入模型-->模型輸出並且解碼。差異在於使用vllm首先會使用一個LLM去處理你的模型,而後你其他的方式都是在這個LLM中,因此瞭解一下在模型接受到我的prompt之前模型都在做什麼。
vllm初始化過程
按照PPT[2]中對於模型加載的描述:
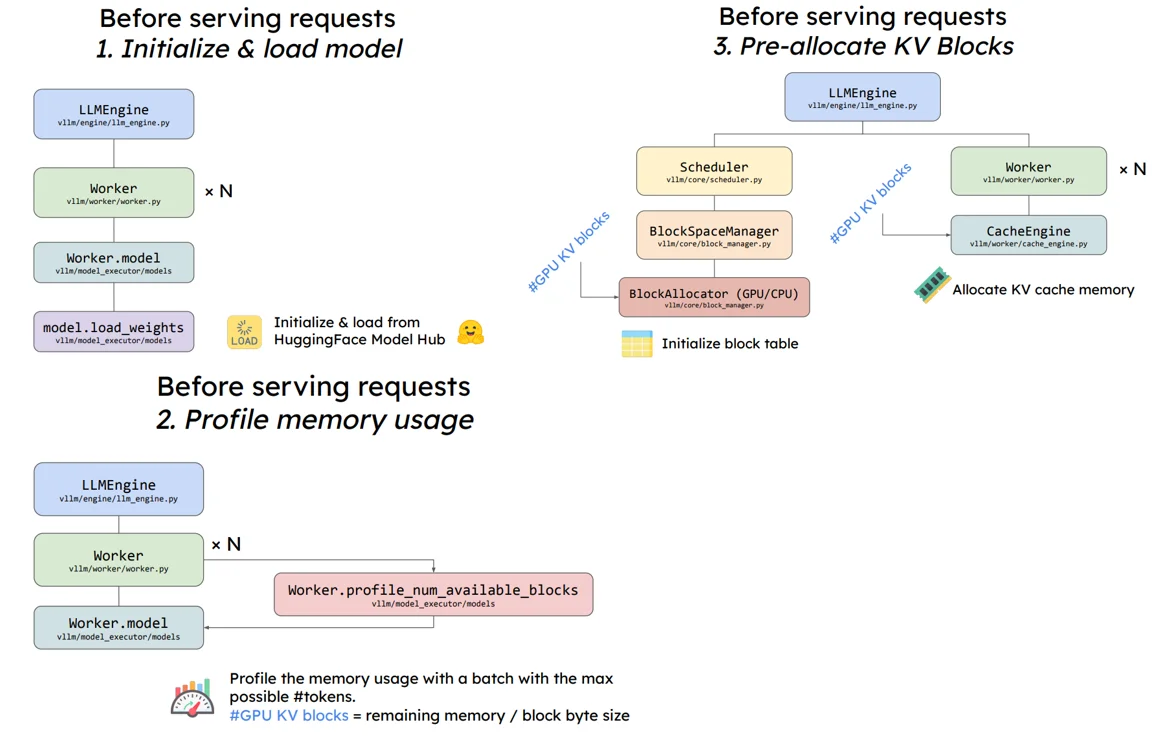
在模型進行輸出之前主要是進行3步:1、初始化並且加載模型;2、預分配顯存過程;3、將預分配的KV Cache加載到gpu上。
模型初始化過程
在vllm中定義一個llm過程為:
# vllm/entrypoints/llm.py
class LLM:
...
self.llm_engine = LLMEngine.from_engine_args(...)
# vllm/v1/engine/llm_engine.py
class LLMEngine:
def __init__(...):
self.engine_core = EngineCoreClient.make_client(...)
def generate(...):
...
def add_request(...):
...
# /vllm/v1/engine/core_client.py 中 EngineCoreClient通過多種(異步/多進程,這也就意味這在linux有些可能需要使用`multiprocessing.set_start_method('spawn', force=True)`)方式進行加載模型
在LLMEngine代碼中定義了基本所有函數功能,如生成等(後續解釋具體過程)。
預分配顯存過程
這個給過程的的話首先是去計算預分配的KV Cache大小,而後將預分配的KV Cache加載(一般就是初始化為0的向量)到gpu上
- 計算預分配的KV Cache
計算預分配的KV Cache[3]:可用顯存大小×預分配vllm比率- 非kv cache佔用大小得到kv cache的可用(字節)大小,而後通過總共可用大小計算可用分多少個block:可分配大小//KV cache block 的字節大小//所有 kv_cache_groups中層數的最大值
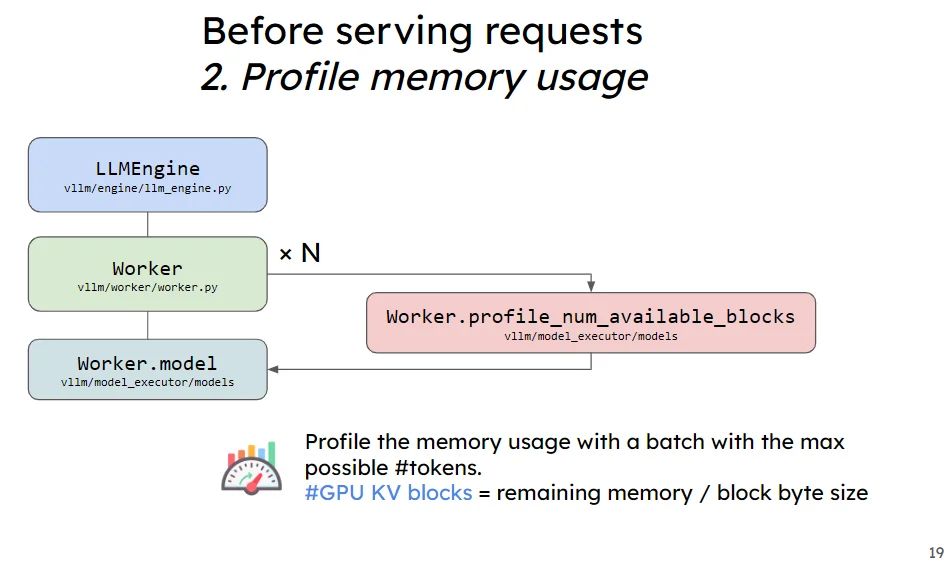
在調用代碼LLM(model="facebook/opt-125m")實際過程中會使用load_model進行模型加載(代碼:vllm/v1/worker/gpu_model_runner.py)在加載模型之後,模型會進行一個顯存的預分配處理,這個過程(代碼:vllm/v1/core/kv_cache_utils.py)描述如下:
1、計算需要分配多少顯存給vllm:可用顯存大小*初始化分配大小(self.requested_memory=self.init_snapshot.total_memory * self.cache_config.gpu_memory_utilization,比説24G(實際可能比24G要小,因為還有模型佔用)顯卡那麼的第一項結果就是:24*1024^3,後面一下就是最開始的參數)
2、計算分配給kv cache的顯存佔用字節大小:可以顯存大小-除去KV cache顯存外其他大小(self.available_kv_cache_memory_bytes = self.requested_memory - profile_result.non_kv_cache_memory)
在計算完畢之後(以上面模型加載為例,得到KV cache大小為:20.44GiB)接下來就是計算GPU上 KV Cache 內總token數量:num_tokens = num_blocks // len(kv_cache_groups) * min_block_size
1、num_blocks計算過程:int(available_memory // page_size // num_layers),其中page_size代表是一個 KV cache block 的字節大小(page_size = 2(K+V) * 16(block_size) * 12(num_kv_heads) * 64(head_size) * 2(dtype_bytes 其中fp16對應2)=49152,裏面num_kv_heads對應你的模型結構使用數量);num_layers:所有 kv_cache_groups中層數的最大值,比如説在模型facebook/opt-125m中總共有12層decode(即 12 層進行注意力計算)並且這些attn計算方式完全相同那麼就是1個group分組(如果還有其他attn那麼可能就是多個group但是最後還是取最大值:group_size = max(len(group.layer_names) for group in kv_cache_groups)。最後計算得到結果為:num_blocks = 21946158284//49152// 12=37207
2、min_block_size = min([group.kv_cache_spec.block_size for group in kv_cache_groups]) 計算得到:16。
實際調試過程中(直接在需要調試位置使用
logger.info),輸出kv_cache_groups看到的比如(其實這個參數也就是記錄cache需要發生位置,一般就是attn計算,不過可能對於不同的attn存在差異,有些是常規有些有可能是window-attn等):[KVCacheGroupSpec(layer_names=['model.decoder.layers.0.self_attn.attn', ..., 'model.decoder.layers.11.self_attn.attn'], kv_cache_spec=FullAttentionSpec(block_size=16, num_kv_heads=12, head_size=64, dtype=torch.float16, sliding_window=None, attention_chunk_size=None))]除此之外這部分結果會直接存入KVCacheConfig中。在後續代碼(vllm/v1/worker/gpu_model_runner.py)中對於initialize_kv_cache(具體解釋見下面)還會為每一塊model.decoder.layers.0.self_attn.attn取分配一個初始化(具體函數:initialize_kv_cache_tensors)為0的向量大小為:[2, num_blocks, block_size, num_kv_heads, head_size]
因此最後就可以直接得到:num_tokens = 37207// 1*16 = 595,312。
- 將預分配的KV Cache加載到gpu上
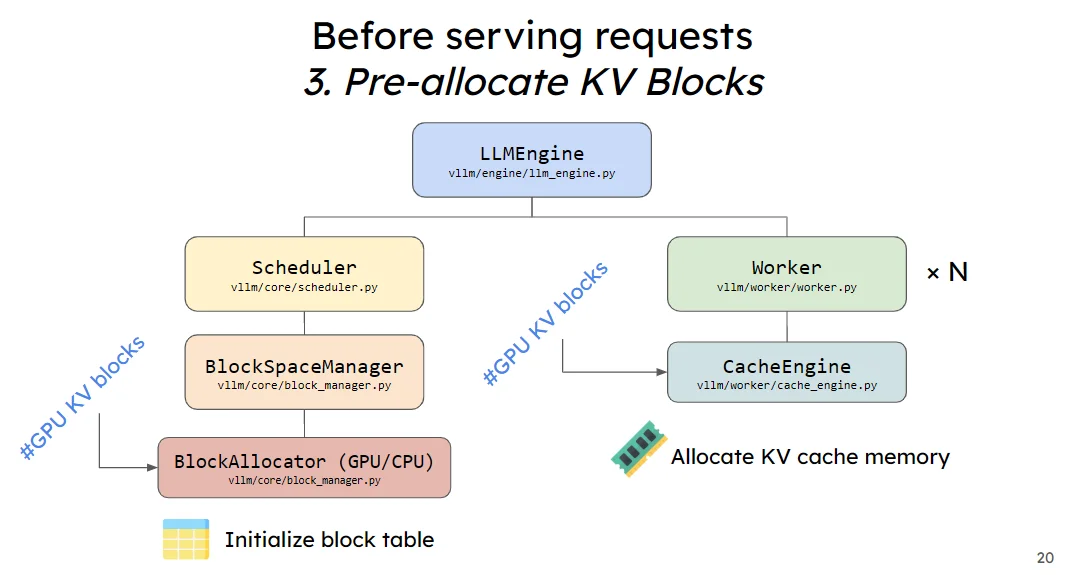
在上述步驟中計算得到了預分配的KV cache大小以及num blocks,接下來就是直接將其先放置到gpu上,實現顯存的預分配,以後這塊顯存就是專門用來做KV Cache。具體過程中還是使用上面得到的kv_cache_groups這個參數
# vllm/v1/worker/gpu_model_runner.py
def initialize_kv_cache_tensors(self, kv_cache_config: KVCacheConfig):
# Initialize the memory buffer for KV cache
kv_cache_raw_tensors = self._allocate_kv_cache_tensors(kv_cache_config)
# Change the memory buffer to the desired shape
kv_caches = self._reshape_kv_cache_tensors(kv_cache_config, kv_cache_raw_tensors)
...
num_attn_module = 2 if self.model_config.hf_config.model_type == "longcat_flash" else 1
bind_kv_cache(kv_caches,
self.compilation_config.static_forward_context,
self.kv_caches, num_attn_module)
return kv_caches
def _allocate_kv_cache_tensors(self, kv_cache_config: KVCacheConfig):
kv_cache_raw_tensors: dict[str, torch.Tensor] = {}
logger.info(kv_cache_config)
for kv_cache_tensor in kv_cache_config.kv_cache_tensors:
tensor = torch.zeros(kv_cache_tensor.size,
dtype=torch.int8,
device=self.device)
for layer_name in kv_cache_tensor.shared_by:
kv_cache_raw_tensors[layer_name] = tensor
...
return kv_cache_raw_tensors
對於參數
KVCacheConfig就是上面的kv_cache_groups結果,只不過還會取計算每層的大小也就是會更新為:KVCacheConfig(num_blocks=37207, kv_cache_tensors=[KVCacheTensor(size=1828798464, shared_by=['model.decoder.layers.0.self_attn.attn']), ..., KVCacheTensor(size=1828798464, shared_by=['model.decoder.layers.11.self_attn.attn'])], kv_cache_groups=[KVCacheGroupSpec(layer_names=['model.decoder.layers.0.self_attn.attn', ...,'model.decoder.layers.10.self_attn.attn', 'model.decoder.layers.11.self_attn.attn'], kv_cache_spec=FullAttentionSpec(block_size=16, num_kv_heads=12, head_size=64, dtype=torch.float16, sliding_window=None, attention_chunk_size=None))])
在函數self._allocate_kv_cache_tensors中很容易理解直接初始化一個全部為0的張量,而後再去通過函數_reshape_kv_cache_tensors將張量的形狀改為[num_blocks, block_size, num_kv_heads, head_size]
總結
本文主要是簡單介紹了一些vllm的顯存分配過程中,預分配顯存比較簡單:可用顯存大小×預分配vllm比率- 非kv cache佔用大小,而後就是直接去計算KV Cache中總token數量這部分計算過程是:num_tokens = num_blocks // len(kv_cache_groups) * min_block_size。
參考
-
https://dl.acm.org/doi/pdf/10.1145/3600006.3613165 ↩︎
-
vllm-ppt ↩︎
-
https://zhuanlan.zhihu.com/p/691045737 ↩︎