
前言
在當今技術迭代日新月異的背景下,項目引入且靈活調配多個AI模型已成為常態。然而,這種多模型策略也帶來了顯著的工程挑戰:開發團隊不得不為OpenAI、DeepSeek、Claude、Qwen等每一個平台重複進行獨立的賬户註冊、API密鑰申請、SDK學習與接口適配。不僅引入了鉅額的集成與維護成本,更使得開發者在頻繁的模型切換與比對測試中,陷入了效率低下的泥潭。構建一個統一、標準化且可擴展的模型調度層,已成為提升全棧AI應用開發效能的關鍵。
在此背景下,GMI Cloud推理引擎以其前瞻性的架構設計,提供了卓有成效的解決方案。該平台通過打造全域統一的OpenAI兼容API,實現了“單一端點,通聯百模”的願景,讓開發者僅憑一套憑證與代碼規範,即可無縫調用涵蓋文本、圖像、視頻在內的數十個頂尖模型。在為期兩週的深度集成與壓力測試中,其卓越表現令人印象深刻:在基礎設施層面,它基於高性能H200芯片構建,目前已聚合36個主流大語言模型(如DeepSeek、GPT系列、Qwen、Kimi)及31個前沿視頻生成模型(如Sora 2、Veo 3.1、Kling V2.5);在接口層面,模型間的切換被簡化為一個參數的修改,極大提升了研發敏捷性;此外,其透明、細粒度的Token級計費機制,為項目成本控制與資源管理提供了前所未有的精準洞察。
一.GMI Cloud
GMI Cloud 依託高穩定性技術架構與強大的GPU供應鏈,為企業AI應用提供安全高效的計算支持。通過自研 Cluster Engine 與 Inference Engine 兩大核心平台,實現從算力原子化(支持0.1 GPU粒度動態分配)到業務級智算服務的全棧升級。具體表現為以下三大核心能力:
高性能GPU產品矩陣 平台集成包括H200、B200等新一代高性能芯片,為不同AI場景提供精準算力支持。
| 芯片型號 | 峯值算力 | 關鍵優勢 | 典型應用場景 |
|---|---|---|---|
| H200 | 15.8 TFLOPS | 推理能效提升約40% | 大規模模型推理、視頻生成 |
| B200 | 20.1 PFLOPS | 訓練吞吐量顯著優化 | 大模型預訓練、科學計算 |
全球模型統一接入平台 作為AGI基礎設施的重要推動者,GMI Cloud構建了支持ONNX/TensorRT等7種標準協議的高性能推理平台。截至2024年第三季度,平台已集成包括 Veo 3.1、Sora 2、Wan 2.5、Kimi K2 Thinking、DeepSeek V3.2、GLM-4.6、GPT OSS 及 Qwen 3 等97個主流模型,為企業提供行業領先的模型服務響應速度。
可驗證的落地效能 在典型應用場景中,平台已成功助力某自動駕駛企業將模型推理延遲從150ms 優化至 23ms,端到端推理效率提升超過80%,顯著降低了企業AI應用的落地門檻與推理成本。
二.註冊體驗GMI Cloud
1️⃣.GMI Cloud註冊登錄
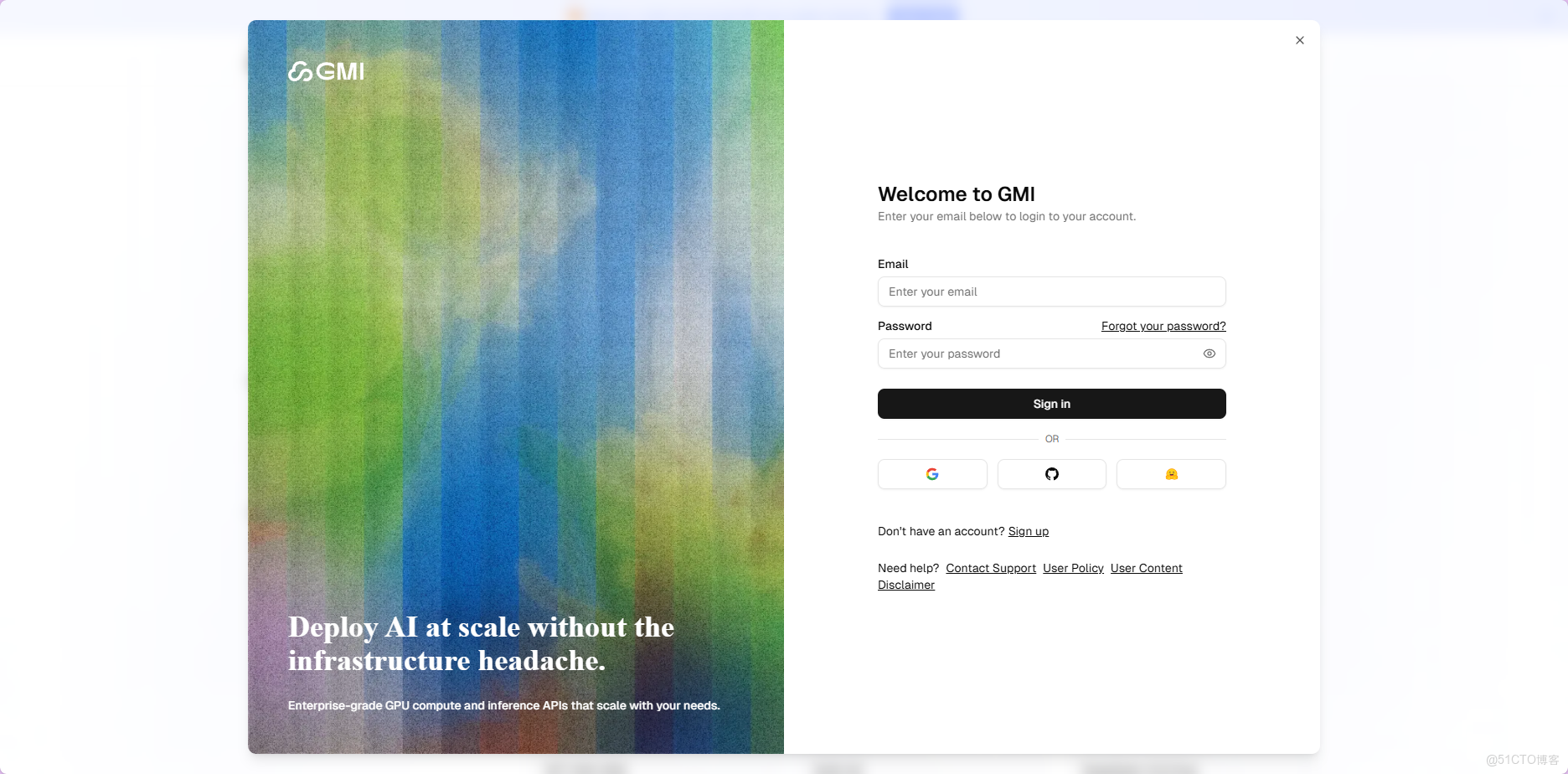
首先打開**GMI Cloud註冊網址**,首頁右上角點擊註冊Sign in按鈕;進入註冊/登錄頁面,支持郵箱註冊登錄以及Google,GitHub和Hugging Face授權登錄。我使用的Google授權登錄,Google授權登錄到填寫組織名稱,可以説是非常流暢絲滑。
GMI Cloud註冊網址:https://sourl.co/QLc9ci 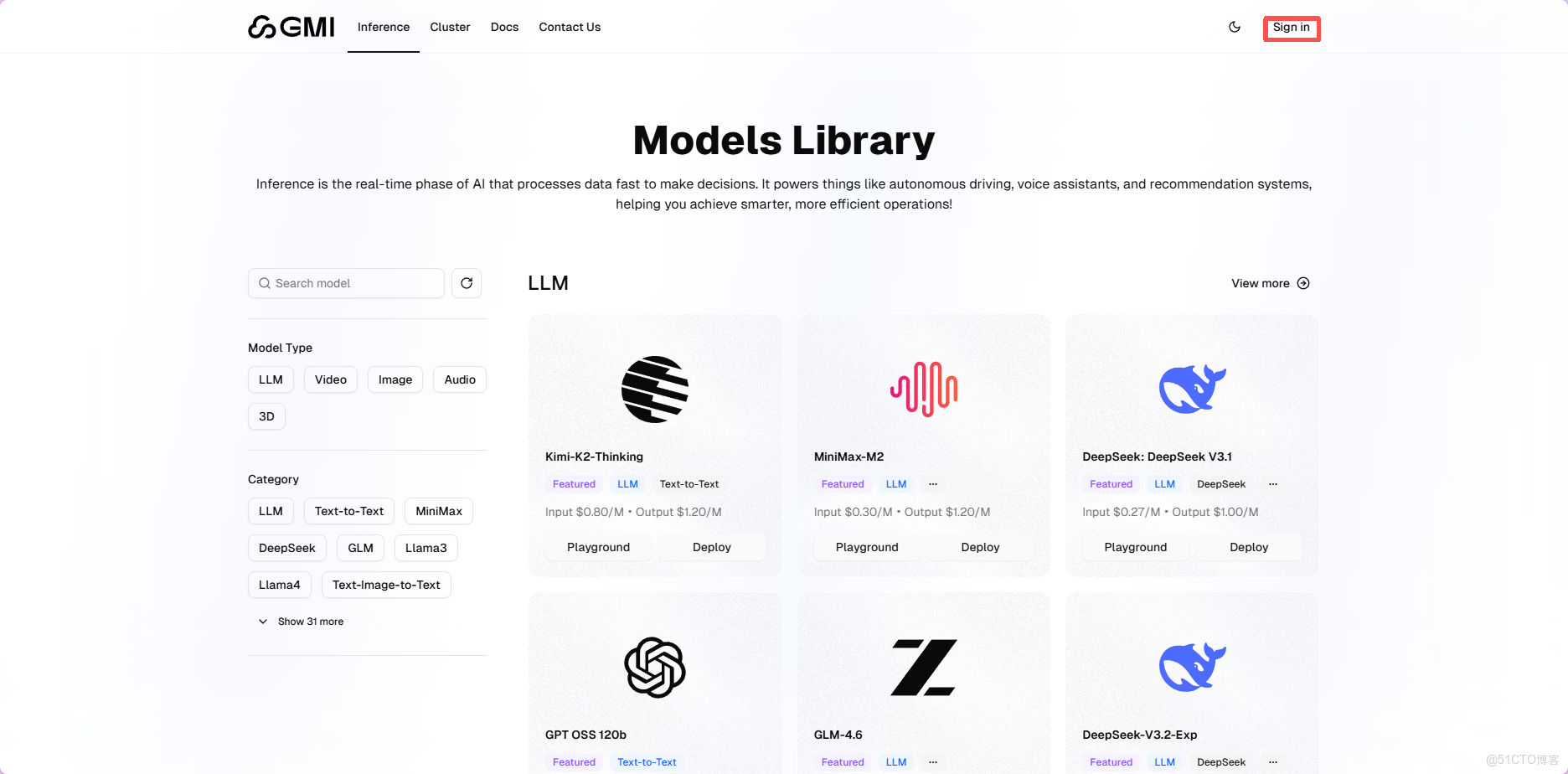
2️⃣.領取兑換體驗額度
新註冊用户即贈優惠碼,可兑換免費體驗額度,足以滿足測試與小規模應用需求。
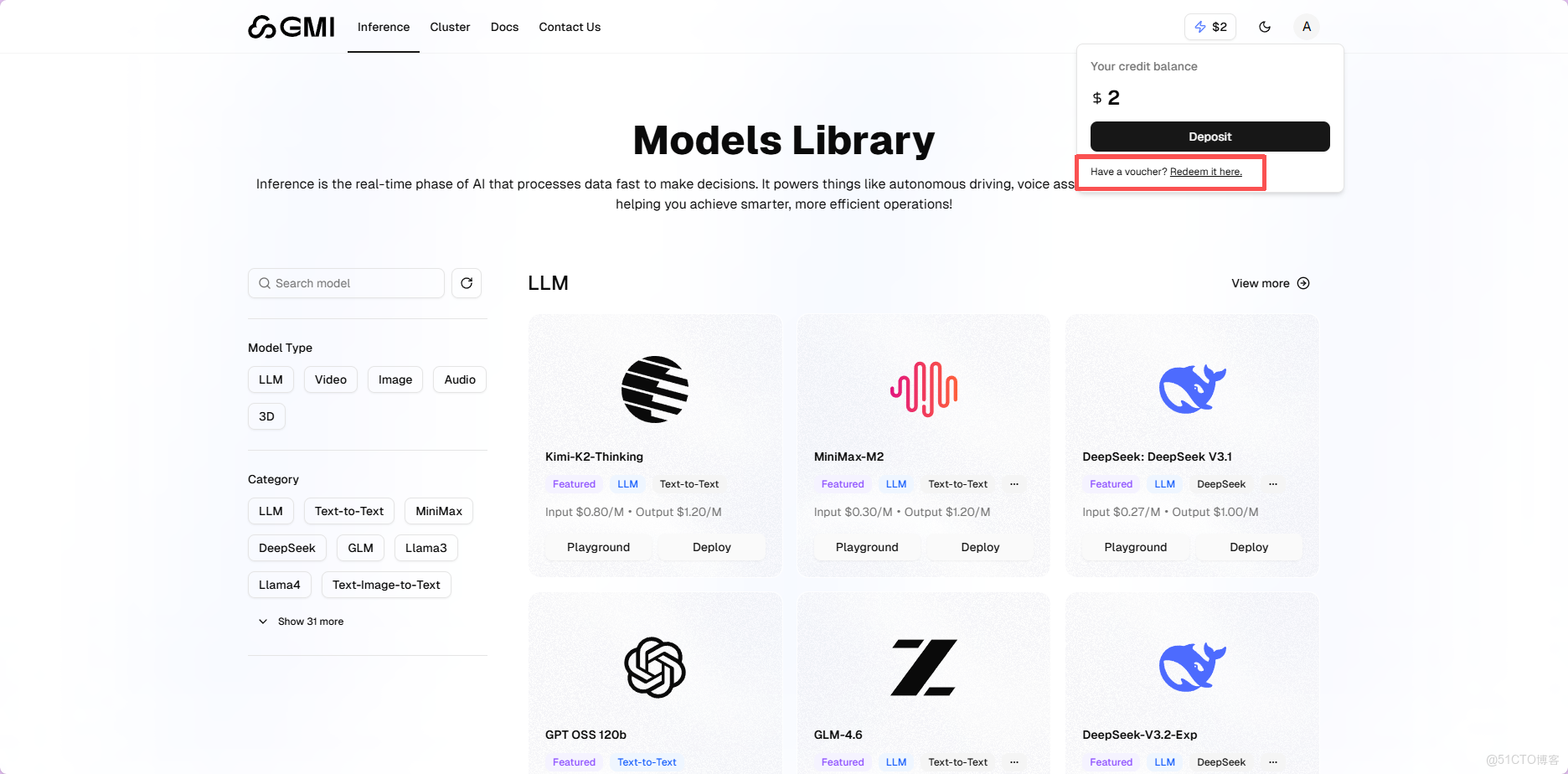
登錄後先看左側菜單,確認選中了Mass這個選項。這是主控制枱的默認視圖。然後點擊右上角顯示"0 USD"的餘額區域,會彈出一個賬户信息窗口。在彈出的窗口裏找到"Redeem it here"這個鏈接,點進去。輸入優惠碼:ACC2025BJ點擊"Apply"按鈕完成兑換。刷新頁面後,餘額就會變成 2.00 USD。這個錢可以用在所有集成的模型上,沒有限制。
三.GMI Cloud優勢
1️⃣.模型豐富,一站式滿足所有創作需求
本平台匯聚了海量前沿AI模型,讓您無需在多個應用間切換,即可在一個界面中便捷調用和對比各類頂尖模型,極大提升了創意工作的效率與體驗;而且劃分為了LLM,Video,Image,Audio,3D五個類型分組,讓用户更加方便使用。僅大語言模型(LLM)就提供36款,覆蓋從國產的DeepSeek、Qwen、GLM,到國外的GPT、Claude、Gemini,乃至最新的Kimi-K2-Thinking等主流與前沿模型。每個模型均清晰標註上下文長度、功能支持(如函數調用)及價格信息,用户無需跨平台查閲即可高效對比選擇,極大提升使用便捷性。
在視頻生成方面,平台集成31款模型,除Sora 2、Veo 3.1等國際模型外,也包括Kling V2.5、Wan 2.5、Minimax-Hailuo 2.3等優秀國產模型,並明確標註其支持類型(如文生視頻、圖生視頻),方便用户直觀選用。圖像生成模型數量雖相對精簡,但質量出眾,Flux系列、Seedream系列、Seededit系列全面覆蓋從零生成到圖像編輯等多種場景,滿足不同創作需求。
大語言模型(LLM)
-
數量豐富:提供36款主流與前沿大語言模型。
-
覆蓋全面:囊括國內外知名模型,包括國產的DeepSeek、Qwen、GLM,國外的GPT、Claude、Gemini,以及最新的Kimi-K2-Thinking等。
-
信息清晰:每個模型均標註上下文長度、功能支持(如函數調用)及價格信息,方便用户快速對比,無需跨平台查閲。
視頻生成模型
-
陣容強大:共集成32款視頻生成模型,涵蓋Sora 2、Veo 3.1等國際模型,以及Kling V2.5、Wan 2.5、Minimax-Hailuo 2.3等優秀國產模型。
-
功能明確:支持文生視頻、圖生視頻及複合功能型等多種生成方式,界面分類清晰,便於快速定位。
圖像生成模型
-
精選優質:雖總數相對精簡,但品質出眾,涵蓋Flux系列、Seedream系列、Seededit系列等。
-
功能齊全:覆蓋從零生成、圖像編輯與優化等多種創作場景,滿足多樣化需求。
2️⃣.技術領先,一站式賦能高效開發
1. 技術根基紮實,集成度高 平台底層基於H100/H200芯片構建,集成近百個前沿模型,全面覆蓋視頻生成、大語言模型、圖像生成等主流類別。所有模型採用統一API體系,無需因切換模型而重複註冊、申請密鑰或編寫適配代碼,顯著提升開發效率與代碼複用率,極大降低了維護成本。
2. 模型更新迅速,緊跟前沿 平台模型更新速度令人驚喜,如Minimax Hailuo 2.3、Kimi-K2-Thinking等新模型常在發佈數日內上線,確保技術型項目能及時用上最新能力,無需漫長等待。
3. 成本透明可控,管理便捷 支持按Token計費,後台可查看每次調用的詳細消耗記錄,並支持設置預算提醒功能,有效幫助團隊控制成本,避免意外超支。
4. 團隊背景可靠,服務穩定 平台由Google X AI專家與硅谷團隊創立,並作為NVIDIA全球六大參考平台雲合作伙伴,享有優先GPU資源支持。配合全球分佈式數據中心,API響應速度穩定在1–3秒,視頻生成僅需1–3分鐘,服務穩定性與性能表現符合預期。
四.在線使用模型
GMI Cloud 提供了 Playground 功能,可以直接在瀏覽器裏測試模型,不用寫一行代碼。這個功能特別適合快速體驗和對比不同模型的效果。
1️⃣.生成 Keys密鑰
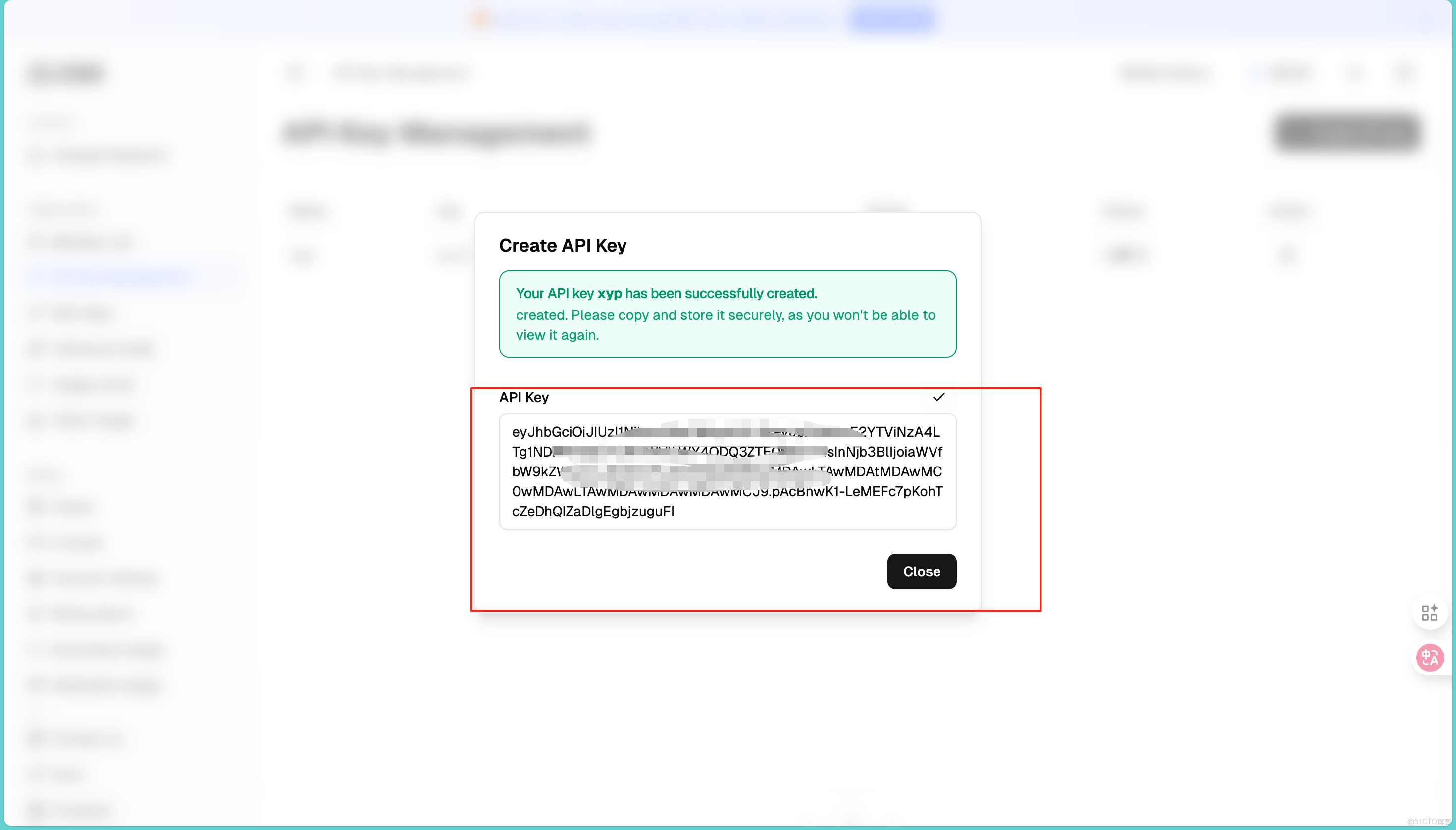
在使用模型之前首先需要我們生成自己的API,進入控制枱,找到左側菜單的Keys:
點擊"Create New API Key"按鈕。給密鑰起個名字,同時可以設置權限範圍,比如只允許調用文本模型,或者只讀不寫。點擊生成後,密鑰會顯示在頁面上,這裏要注意這個密鑰只顯示一次,一定要立刻複製保存,不要問我為什麼,因為我就因為沒記住又回來重新操作了一遍!
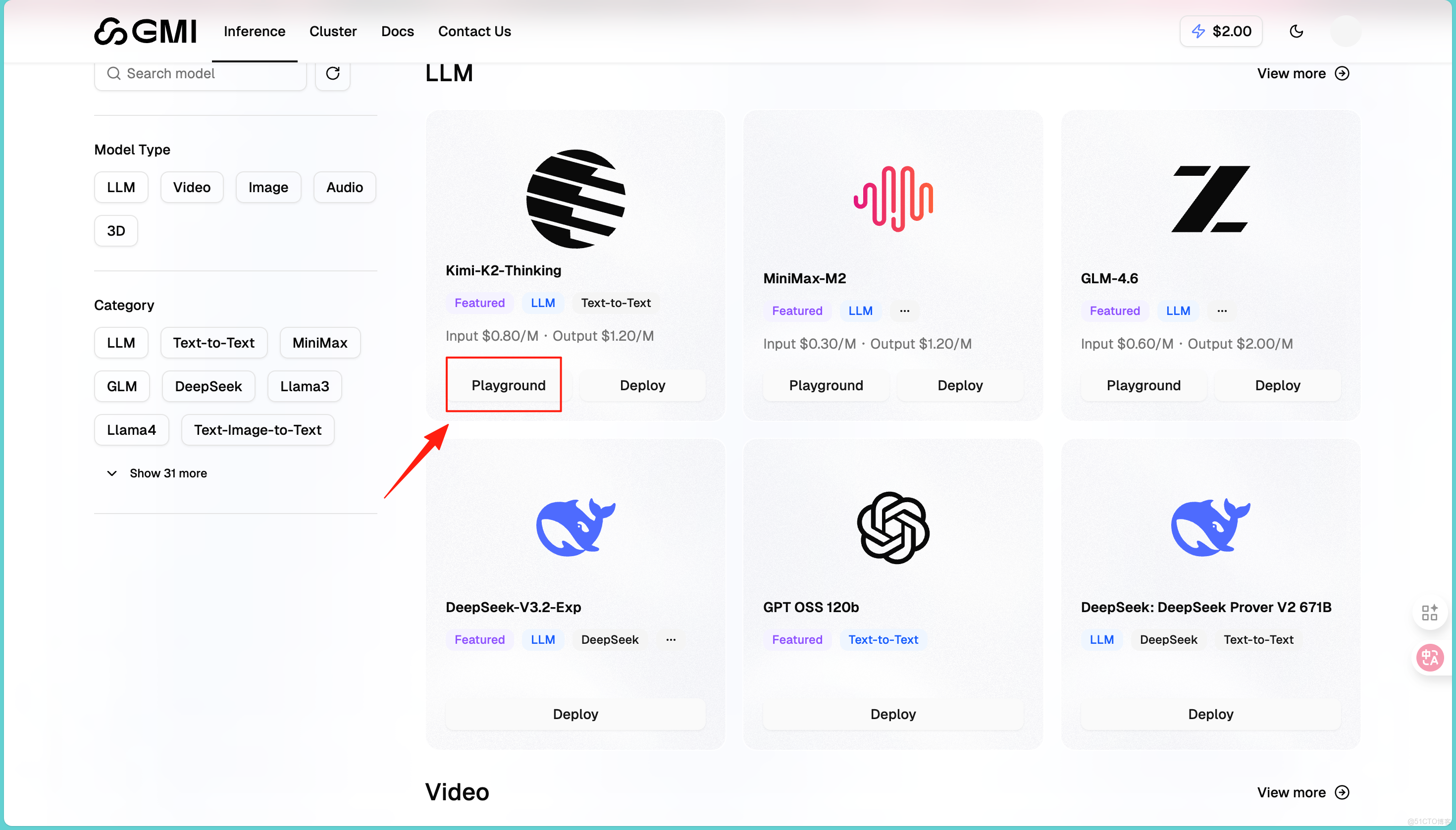
2️⃣.測試大語言模型
在左側菜單選擇"LLM"分類,找到想測試的模型,比如Kimi-K2-Thinking:
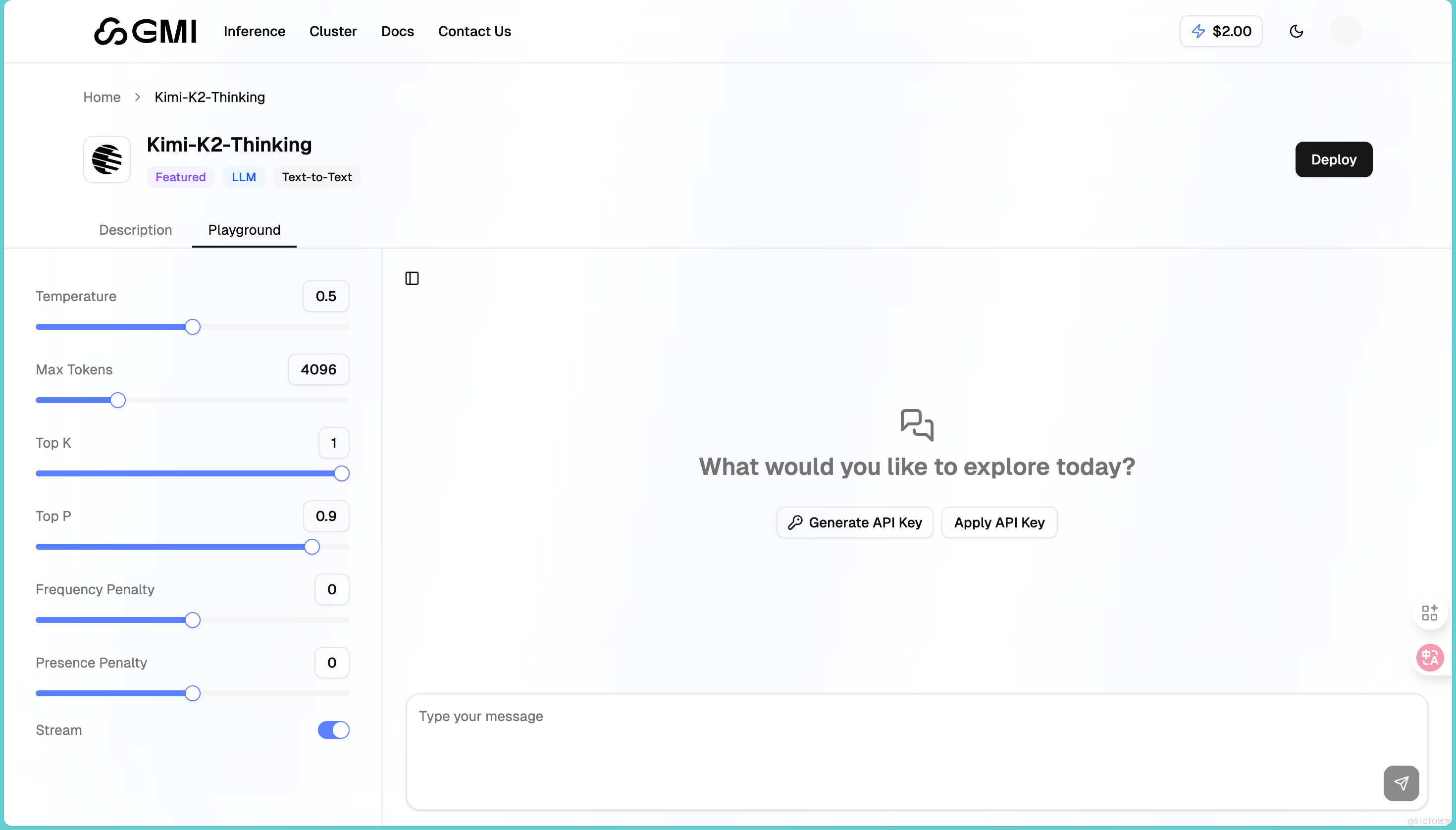
進入之後我們會發現頁面分為左右兩部分。左邊是參數設置區,右邊是對話區:
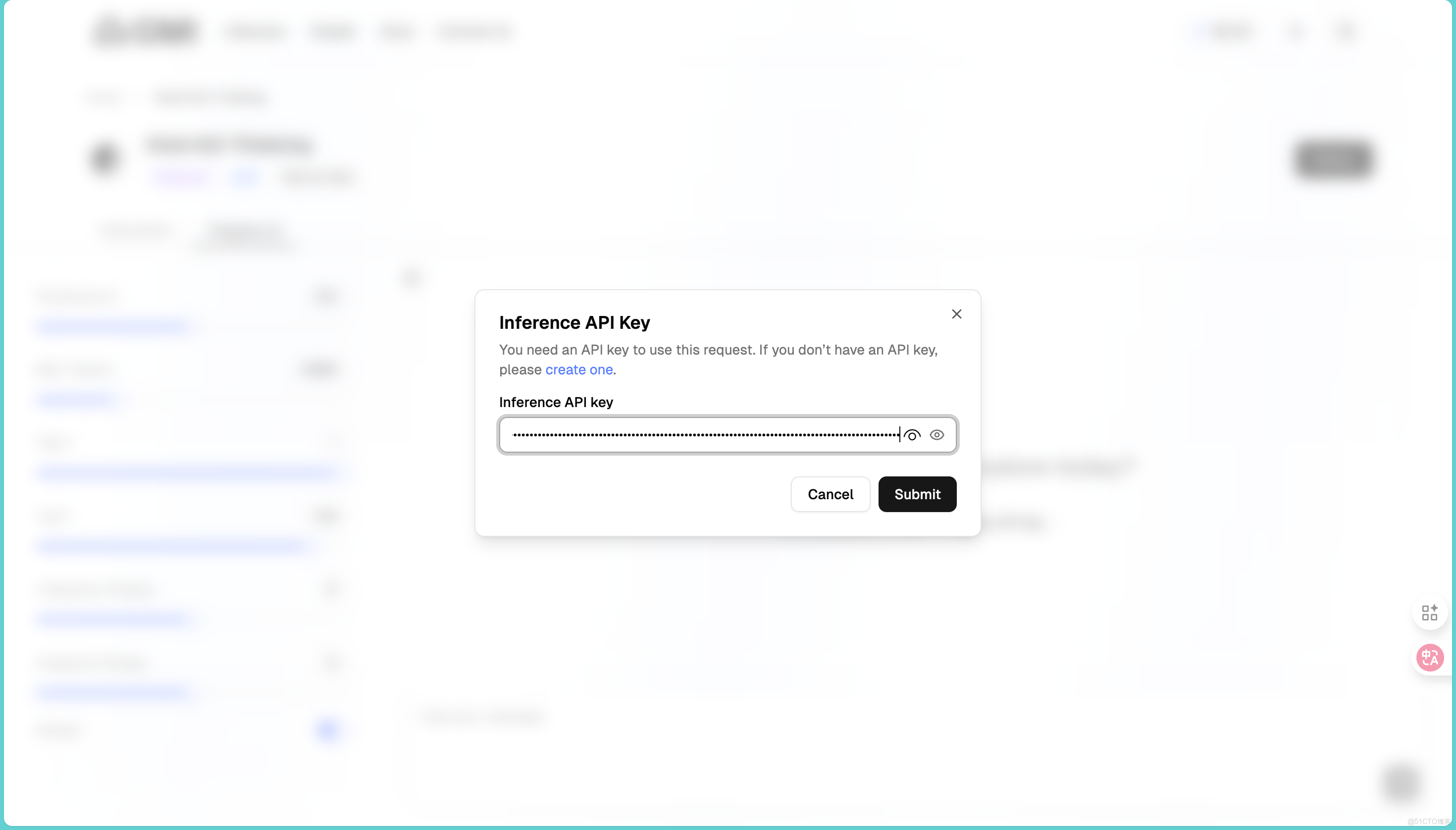
然後在右側的地方點擊Apply API,將我們剛才複製的API輸入進去,然後就可以使用模型了:
在對話框輸入我們的問題,比如"請用 Python 寫一個快速排序算法"。點擊發送按鈕或按 Enter 鍵,等幾秒鐘就能看到回覆:
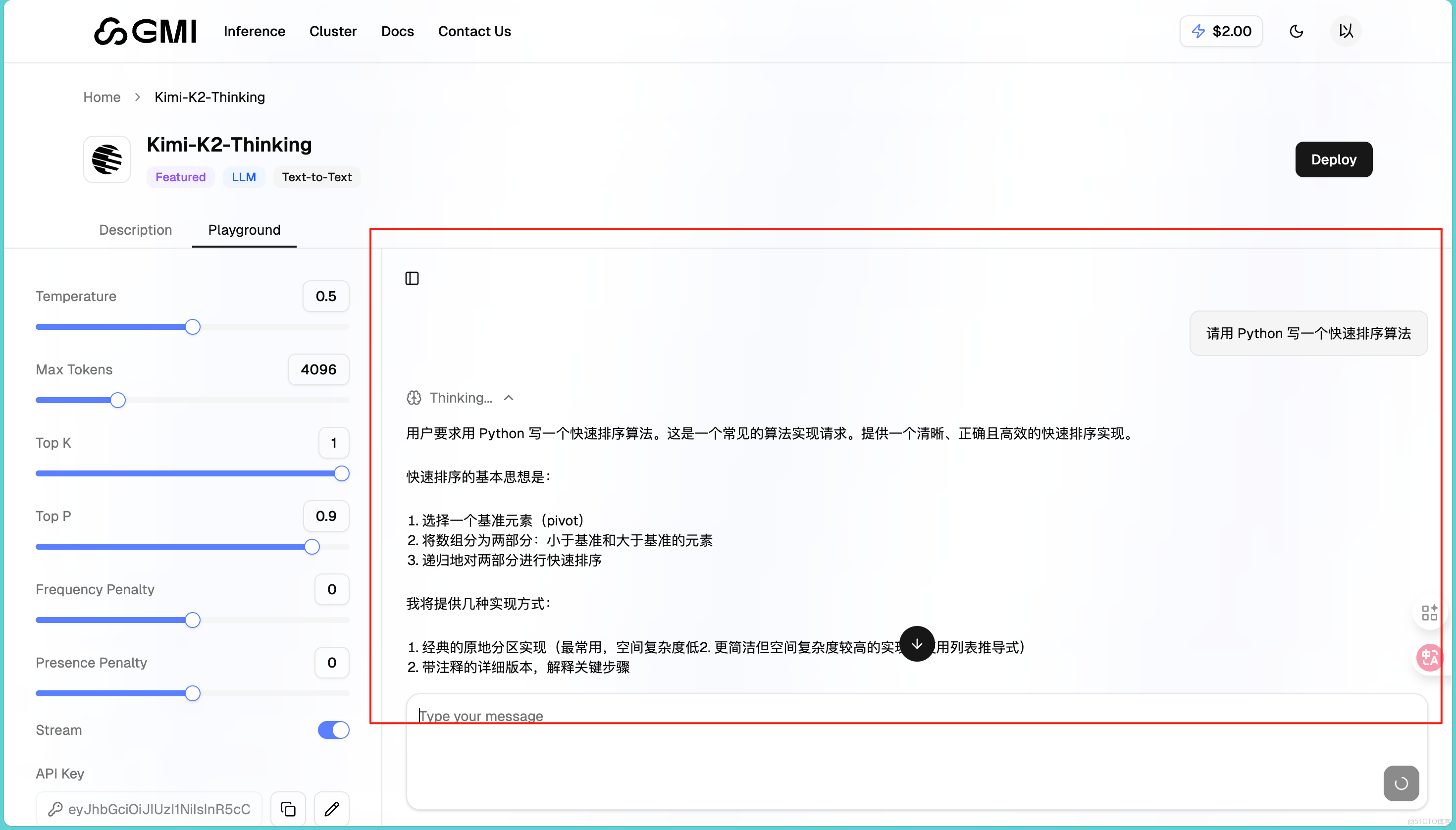
回覆的非常準確,同時左側有幾個重要參數可以調整,可以控制回覆的隨機性以及限制回覆長度等。同Playground 最大的好處是可以快速切換模型對比。同樣的問題,分別用 DeepSeek、Kimi、Qwen 測試,看哪個回答更好。通過我的大量測試,我發現DeepSeek 性價比高,適合大量調用;Kimi-K2 推理能力強,適合複雜問題;GLM-4.6 中文理解好,適合中文內容生成。
3️⃣.生成 AI 視頻
在左側菜單選擇"Video"分類,能看到 31 個模型。每個模型都標註了價格。我一般會先用便宜的模型測試,效果滿意後再用高端模型生成最終版本。這裏我們首先選擇的是:Minimax-Hailuo-2.3。
點擊進入模型頁面,我們可以根據描述你想生成的視頻內容。提示詞寫得越詳細,效果越好,也可以上傳一張圖片作為首幀或參考,如果想讓視頻從特定畫面開始,可以用這個功能。同時其提供了Duration和Resolution供我們選擇,也就是説我們可以自主選擇時長和分辨率。
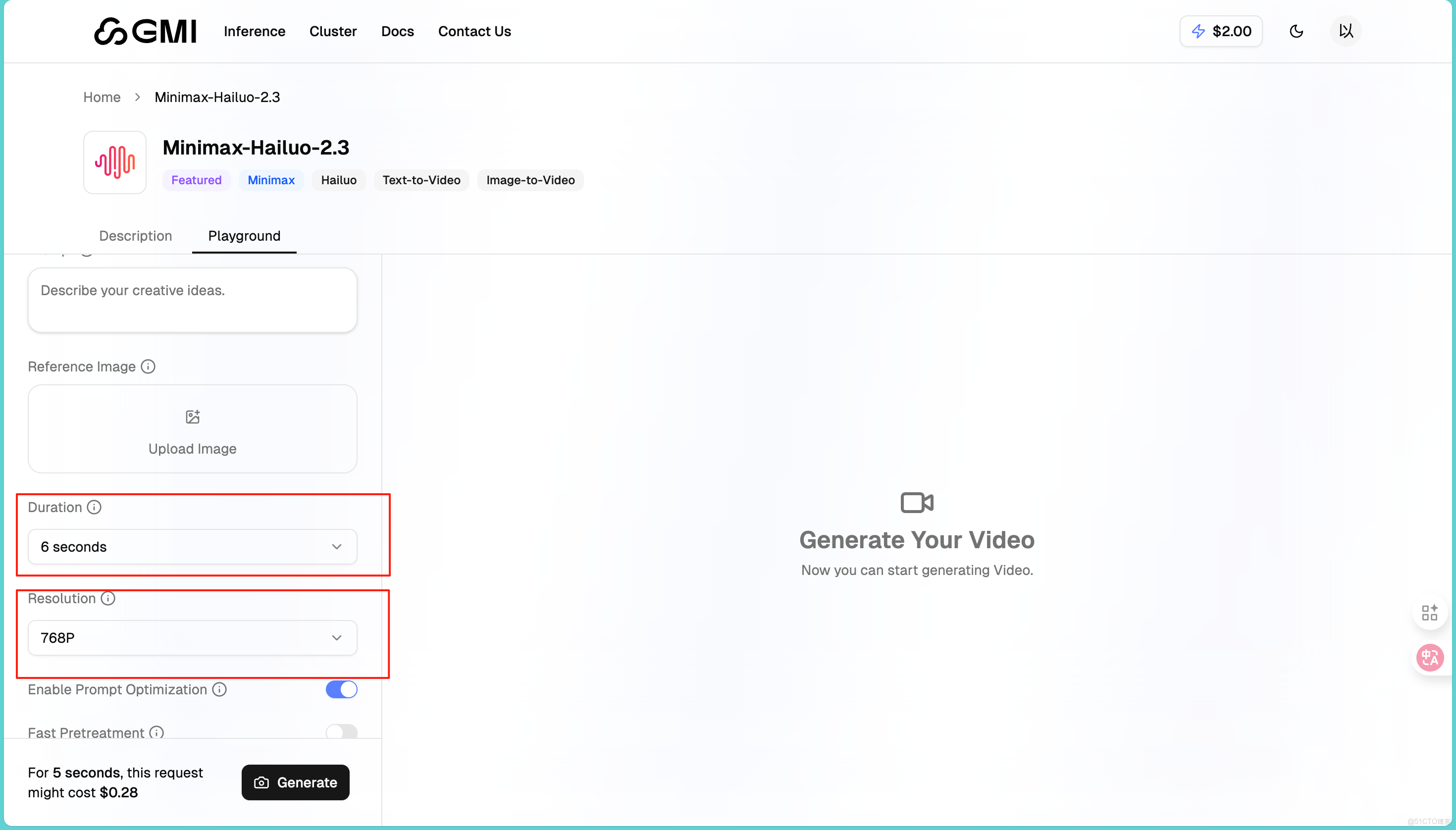
參數設置好後,點擊"Generate"按鈕,視頻生成時間大概一分鐘就好了。這裏我上傳了一張我家貓貓的照片:

我輸入的提示詞是“讓這隻小貓可愛的笑起來”,看看效果咋樣:

我們可以看到生成的十分好,簡直跟真的一模一樣,生成速度快,畫面流暢,適合日常使用。生成的視頻會保存在你的賬户裏,但建議下載到本地,平台可能會定期清理舊文件。其餘的模型我就不再詳細介紹了,大家感興趣就自己來體驗呀。
五.一鍵調用API 模型
1️⃣.如何調用
首先我們打開之前用過的Kimi-K2-Thinking模型,點擊Description,這裏為我們提供了很多然後我們可以選擇使用終端Shell或者Python去調用:
這裏我們選擇用Python去調用,首先輸入其給我們提供的代碼:
import requests
import json
url = "https://api.gmi-serving.com/v1/chat/completions"
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer *************"
}
payload = {
"model": "moonshotai/Kimi-K2-Thinking",
"messages": [
{"role": "system", "content": "You are a helpful AI assistant"},
{"role": "user", "content": "List 3 countries and their capitals."}
],
"temperature": 0,
"max_tokens": 500
}
response = requests.post(url, headers=headers, json=payload)
print(json.dumps(response.json(), indent=2))
這裏要注意Bearer *************後面的內容是需要我們輸入自己的Key,輸入完畢之後點擊運行,我們會看到返回的JSON輸出內容,結構清晰、通用性強,能夠輕鬆被各種編程語言和系統解析處理。這就代表我們已經調用API成功了:
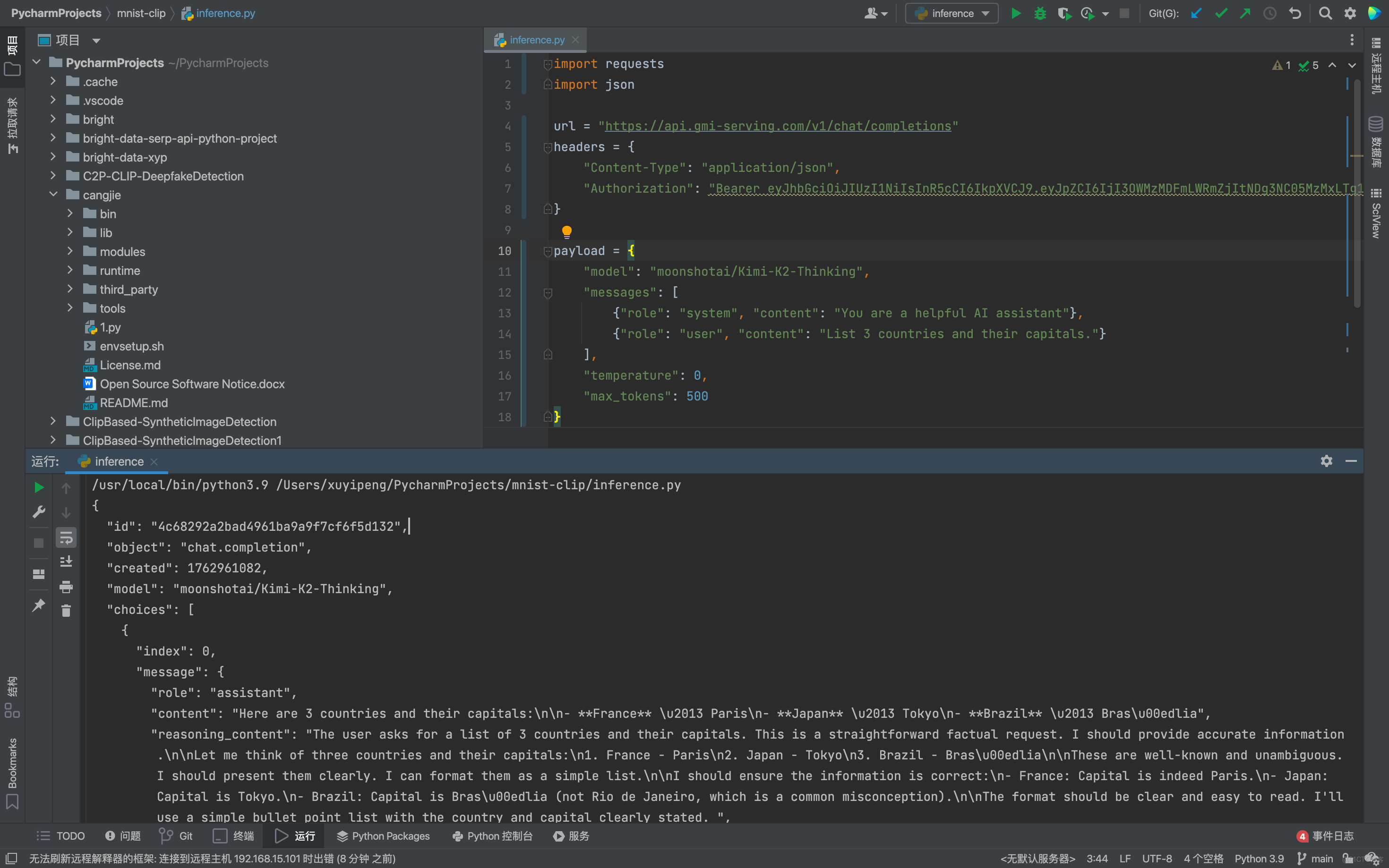
僅需要一步就能完成接入,直接沒有技術門檻,任何人都可以很快的開發。
2️⃣.本地部署LLM模型
為了後續能方便地引用自己的提問,也避免每次修改問題都要在複雜的我先把原本直接寫在 messages 中的提問內容單獨抽離出來。我定義了一個 user_question 變量,這樣一來,後續要更換提問時,只需要修改 user_question 這一行代碼,不用改動整個 結構,代碼的靈活性和可維護性都提升了不少。
原來的代碼只會打印 API 返回的完整 JSON 數據,看起來雜亂且看不到自己的原始提問,輸出結果不夠直觀。我們可以先從響應數據中提取出 AI 的核心回答, 通過回覆定位到 AI 回覆的內容並存儲在變量中。接着用格式化輸出的方式,先明確打印出 “你的問題:” 和對應的提問內容,再換行打印 “AI 的回答:” 以及提取出的回覆,讓提問和回答一一對應,整個輸出結果清晰明瞭,也更符合我查看結果的需求,具體代碼如下:
import requests
import json
url = "https://api.gmi-serving.com/v1/chat/completions"
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer ........"
}
# 提問內容
user_question = "怎麼去寫作"
payload = {
"model": "moonshotai/Kimi-K2-Thinking",
"messages": [
{"role": "system", "content": "You are a helpful AI assistant"},
{"role": "user", "content": user_question} # 引用提問內容
],
"temperature": 0,
"max_tokens": 500
}
response = requests.post(url, headers=headers, json=payload)
response_data = response.json()
# 提取 AI 的回答
ai_answer = response_data['choices'][0]['message']['content']
# 同時打印問題和回答
print(f"你的問題:{user_question}")
print("\nAI 的回答:")
print(ai_answer)
這裏我的問題是怎麼去寫作,我們可以看到Kimi-K2-Thinking模型回答的十分快速也非常詳細: 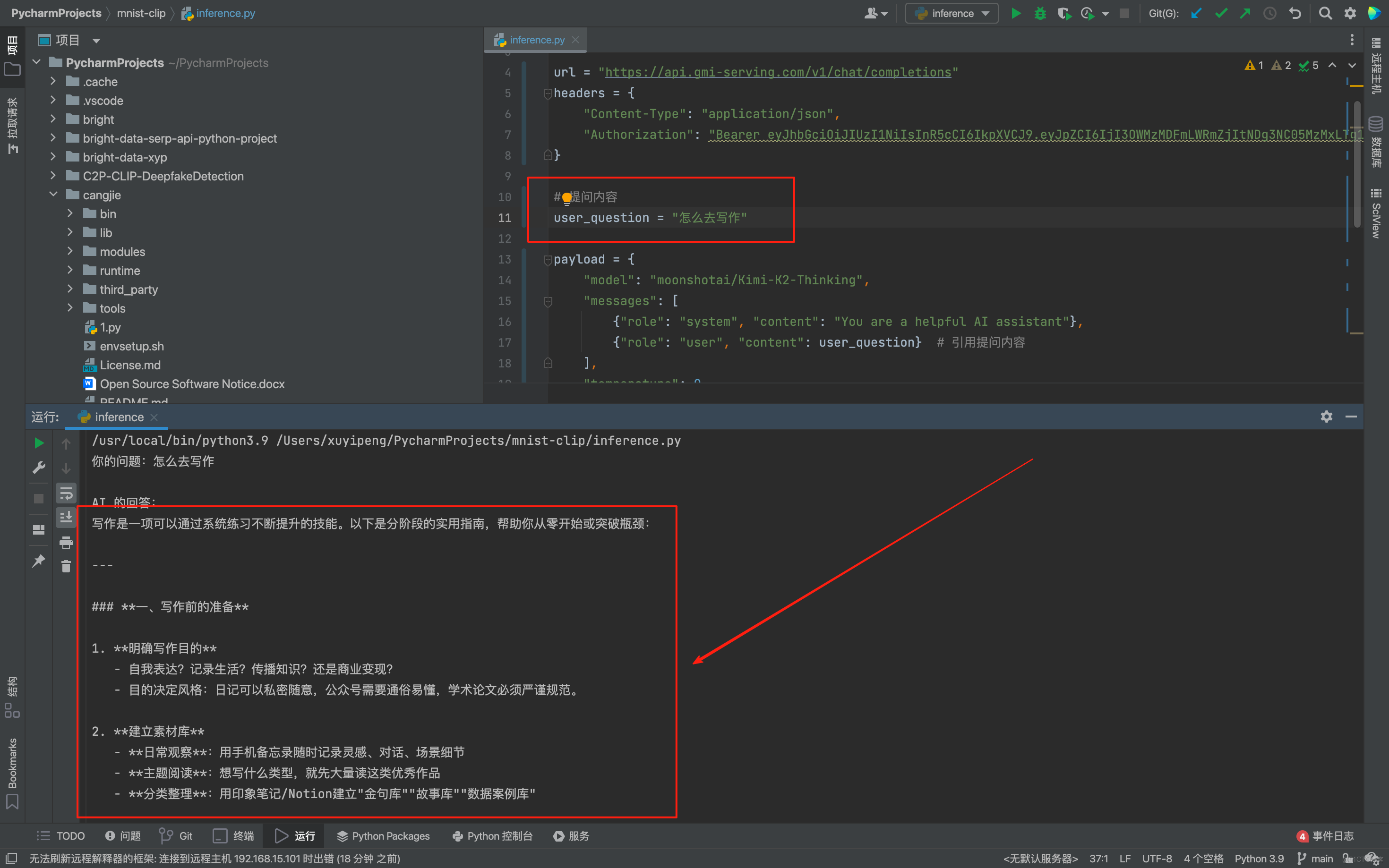
3️⃣.本地部署視頻模型
與 LLM 模型類似,我們可以將視頻生成的 API 調用邏輯進行封裝,使其更易於在本地項目中複用和維護。我寫了一個更結構化的封裝示例,大家可以直接在本地項目中使用,這裏我選擇調用的模型是Minimax-Hailuo-2.3-Fast:
import requests
import json
import os
API_KEY = os.getenv("GMI_API_KEY", "。。。。。。")
# 視頻生成 API 的基礎 URL 和 Endpoint
BASE_URL = "https://console.gmicloud.ai"
ENDPOINT = "/api/v1/ie/requestqueue/apikey/requests"
FULL_URL = f"{BASE_URL}{ENDPOINT}"
HEADERS = {
"Content-Type": "application/json",
"Authorization": f"Bearer {API_KEY}"
}
VIDEO_MODEL_NAME = "Minimax-Hailuo-2.3-Fast"
PROMPT = "A serene ocean scene with waves under a pink sunset"
DURATION = 6 # 視頻時長(秒)
RESOLUTION = "768P" # 分辨率,可選值如 "768P", "1080P" 等
PROMPT_OPTIMIZER = True # 是否開啓提示詞優化
FAST_PRETRATMENT = False # 是否開啓快速預處理
payload = {
"model": VIDEO_MODEL_NAME,
"payload": {
"prompt": PROMPT,
"duration": DURATION,
"resolution": RESOLUTION,
"prompt_optimizer": PROMPT_OPTIMIZER,
"fast_pretreatment": FAST_PRETRATMENT
}
}
def main():
print(f"--- 開始調用視頻模型: {VIDEO_MODEL_NAME} ---")
print(f"提示詞: {PROMPT}")
try:
# 發送 POST 請求
response = requests.post(FULL_URL, headers=HEADERS, json=payload)
# 檢查響應狀態碼
response.raise_for_status()
# 解析 JSON 響應
response_data = response.json()
print("\n請求成功!")
print("完整響應:")
print(json.dumps(response_data, indent=2))
if "data" in response_data and "task_id" in response_data["data"]:
task_id = response_data["data"]["task_id"]
print(f"\n任務 ID: {task_id}")
print("請保存此 Task ID,用於後續查詢視頻生成狀態。")
except requests.exceptions.RequestException as e:
print(f"\n調用 API 時發生錯誤: {e}")
if response:
print("錯誤響應內容:")
print(response.text)
if __name__ == "__main__":
if API_KEY == "你的API" and not os.getenv("GMI_API_KEY"):
print("警告: 請設置 GMI_API_KEY 環境變量或在代碼中替換 '你的API密鑰'。")
main()
這裏我使用的提示詞是:A serene ocean scene with waves under a pink sunset。英文是會更加準確的,建議大家在後期使用的時候也要多使用英文的提示詞,點擊run會發現其已經在我們本地成功運行:
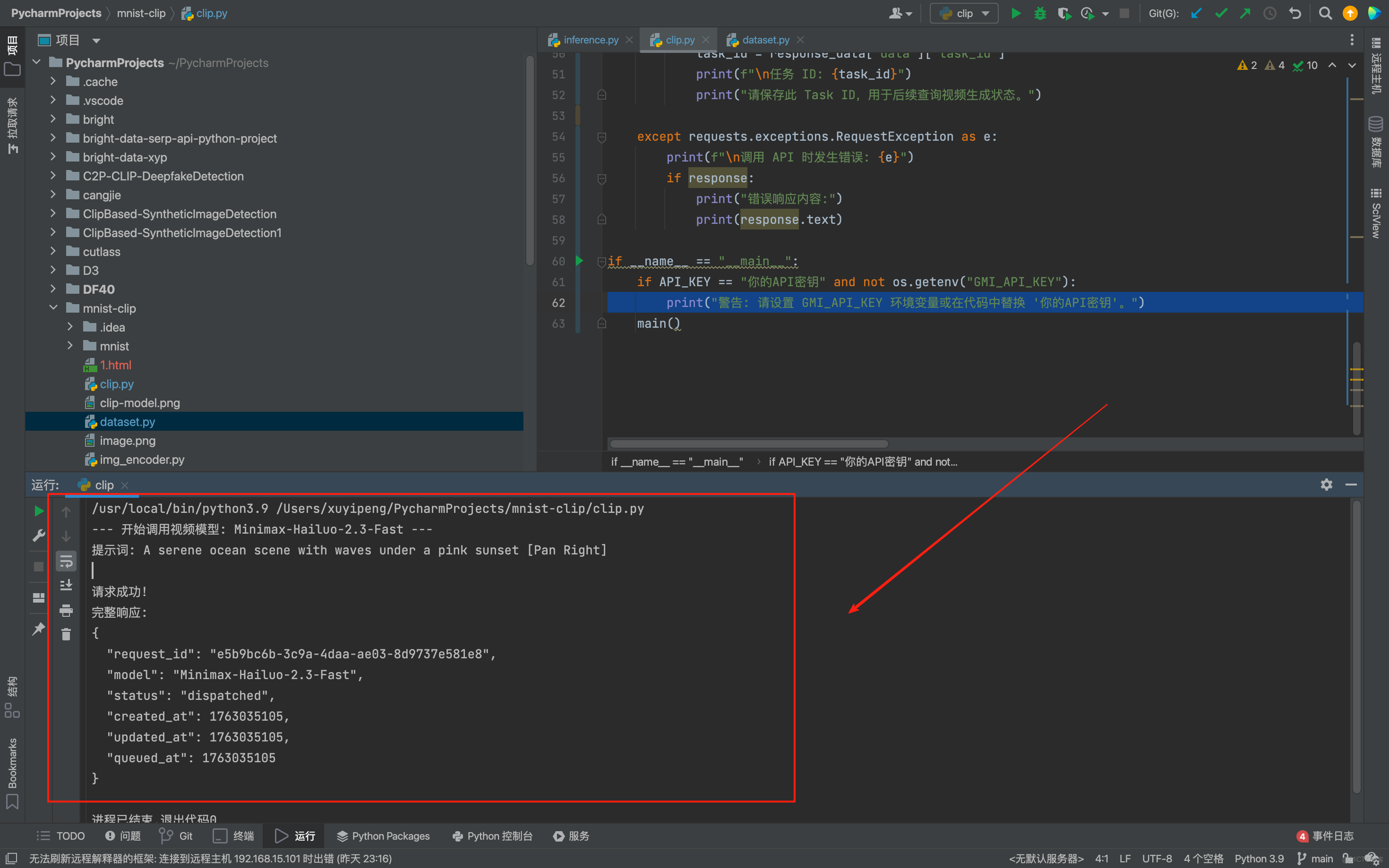
同時我們會看到在後端輸出了我們的視頻,非常的逼真:
六.模型對比與 Agent 集成
在實際開發中,我們經常會遇到兩個核心痛點:一是多模型效果對比繁瑣(尤其是 LLM 代碼能力這種需要反覆測試的場景),二是Agent 集成多模態模型時配置混亂。而 GMI Cloud 的統一 API 體系,恰好完美解決了這兩個問題。
1️⃣.傳統LLM廠家需要單獨調用
現在各家 LLM 都在卷代碼生成、調試、優化能力,但如果想對比不同模型的表現,傳統方式簡直是 “折磨”:要給 OpenAI、DeepSeek、Anthropic、Qwen 等每家平台單獨註冊賬號、充值、申請 API 密鑰。
除此之外每家的 SDK 和接口格式都不同,OpenAI 用openai.ChatCompletion.create,DeepSeek 要改model參數和請求地址,Anthropic 的max_tokens命名可能都有差異;測試時要寫多套適配代碼,切換模型時還要改密鑰、調參數,效率極低。
2️⃣.GMI Cloud一秒調用所有模型
但用 GMI Cloud,這一切都簡化到 “改一個參數”:因為所有模型都遵循統一的 OpenAI 兼容接口,你只需要寫一套代碼,想測試哪個模型,直接修改model字段即可,其他邏輯完全不變。
這裏我想直接對比DeepSeek-V3.1、Kimi-K2-Thinking、gpt-oss-120b的代碼生成能力,讓其用 Python 寫一個斐波那契數列生成器,如果按照傳統方式的話
傳統方式需要:配置 OpenAI 的 API 密鑰和 SDK,寫調用代碼;切換到 DeepSeek 的平台,改 SDK 和密鑰,調整代碼;再切換到 Anthropic,重複適配工作,最後再去測試,非常的麻煩不方便。
但是用了GMI Cloud,代碼只需要寫一次,就可以完成我們所有任務啦,這裏我們將 API_KEY、HEADERS、MODEL_NAMES 等配置項集中放在代碼開頭,把要測試的模型名稱放在 MODEL_NAMES 列表中,想要去修改模型只需修改這個列表,具體代碼如下:
import requests
import json
import os
from typing import List, Dict
API_KEY = os.getenv("GMI_API_KEY", "。。。。。。。"
HEADERS = {
"Content-Type": "application/json",
"Authorization": f"Bearer {API_KEY}"
}
# 定義你想要測試的模型列表
MODEL_NAMES = [
"deepseek-ai/DeepSeek-V3.1",
"moonshotai/Kimi-K2-Thinking",
"openai/gpt-oss-120b",
]
# 定義統一的請求參數
PROMPT = "用 Python 寫一個帶緩存的斐波那契數列生成器"
SYSTEM_PROMPT = "You are a helpful AI assistant."
TEMPERATURE = 0
MAX_TOKENS = 500
def call_single_model(model_name: str, prompt: str) -> Dict:
payload = {
"model": model_name,
"messages": [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": prompt}
],
"temperature": TEMPERATURE,
"max_tokens": MAX_TOKENS
}
try:
response = requests.post(BASE_URL, headers=HEADERS, json=payload)
response.raise_for_status()
return response.json()
except requests.exceptions.RequestException as e:
print(f"調用模型 {model_name} 時發生錯誤: {e}")
return None
def main():
print(f"問題: {PROMPT}\n")
print("--- 開始批量調用模型 ---")
for model in MODEL_NAMES:
print(f"\n===== 正在調用模型: {model} =====")
# 調用模型
response_data = call_single_model(model, PROMPT)
if response_data and "choices" in response_data:
# 提取並打印回答
answer = response_data['choices'][0]['message']['content'].strip()
print(f"回答:\n{answer}")
else:
print("未能獲取有效響應。")
if __name__ == "__main__":
if API_KEY == "你的API密鑰" and not os.getenv("GMI_API_KEY"):
print("警告: 請設置 GMI_API_KEY 環境變量或在代碼中替換 '你的API密鑰'。")
main()
結果如下: 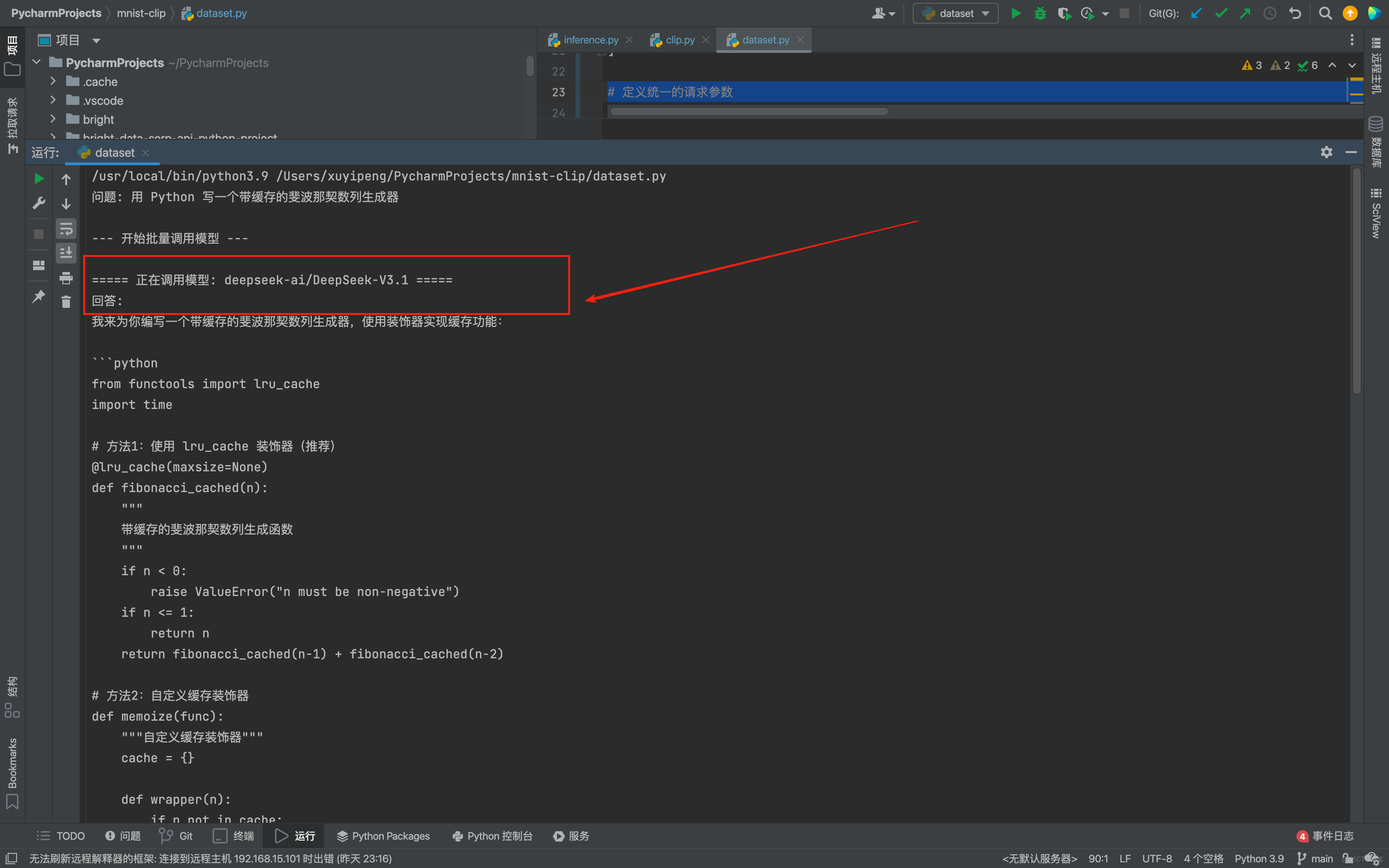
這樣一來,我不需要給任何一家單獨充值,也不用學不同的 SDK,1s即可已完成3 個主流模型的代碼能力對比 ,而且測試結果直觀,能快速判斷哪個模型更適合我的代碼場景,這裏我發現DeepSeek 對中文註釋更友好,Kimi 的緩存邏輯更嚴謹,GPT-4o 的代碼更簡潔。
七、總結
深度使用了兩週 GMI Cloud後,GMI Cloud 的整體體驗還是很滿意。核心優勢在於是顯著提升了開發效率與使用便捷性。 以前接入一個新模型,要註冊平台、看文檔、寫適配代碼,折騰半天。現在一個賬號、一個密鑰,所有模型都能調。代碼寫一次,換模型只需要改個模型名稱。
36 個文本模型、31 個視頻模型,基本覆蓋了所有主流選擇。而且更新很快,新模型發佈後很快就能在平台上用到。同時 按 Token 計費,每次消耗都能看到。不同模型價格有差異,但都在合理範圍。歡迎大家前去使用體驗:
1. 操作統一,極大簡化工作流 平台通過單賬號、單密鑰實現對全部模型的調用管理,徹底改變了以往為每個模型重複註冊、查閲文檔與編寫適配代碼的繁瑣流程。現在,僅需編寫一次基礎代碼,切換模型時僅調整名稱即可,大幅降低了開發與維護成本。
2. 模型豐富,更新及時 平台提供包括36款文本模型與31款視頻模型在內的廣泛選擇,全面覆蓋當前主流需求。同時,新模型上線速度極快,確保用户能第一時間用上前沿技術。
3. 計費透明,成本可控 嚴格採用按Token計費模式,所有調用消耗均清晰可查。不同模型價格結構雖有差異,但均處於合理區間,配合詳細的用量記錄,有效輔助項目成本管理。
