

【點擊立刻報名】
8月11日,網易數帆將舉辦“企業級流式湖倉服務 Arctic 開源發佈會”,邀請網易數帆大數據產品線及合作伙伴相關負責人聯袂解讀對數據技術演進及 Arctic 開源的思考,介紹 Arctic 項目進展、未來發展及社區規劃,分享企業湖倉一體實踐成果與心得。

數據基礎設施發展的腳步從未停歇,當前風頭正盛的是湖倉一體(Lakehouse)。
湖倉一體,顧名思義是數據湖和數據倉庫優勢的結合。隨着企業數智化的推進,湖倉一體已不僅僅是開源社區的熱點技術,硅谷頂級風頭投機構A16Z版圖的視野中心,更是眾多大數據商業產品家族的重要成員。

那麼,湖倉一體真的會成為企業大數據基礎設施的標準?我們是否應當關注這一技術?它的未來是什麼?
為什麼需要湖倉一體
借用Databricks的定義,湖倉一體平台能同時提供數據倉庫的可靠性、強大的治理和性能,以及數據湖的開放性、靈活性和機器學習支持。網易數帆湖倉一體項目負責人馬進認為,湖倉一體是接力Apache Hadoop蓬勃生態的新賽道,它的核心特性就是在數據湖上構建事務層,把數據處理和管理高級功能嫁接到低成本數據存儲架構上。這是業務需求驅動的架構演進,畢竟業務數據類型及規模不斷擴大,而對計算實時性的要求又更高。
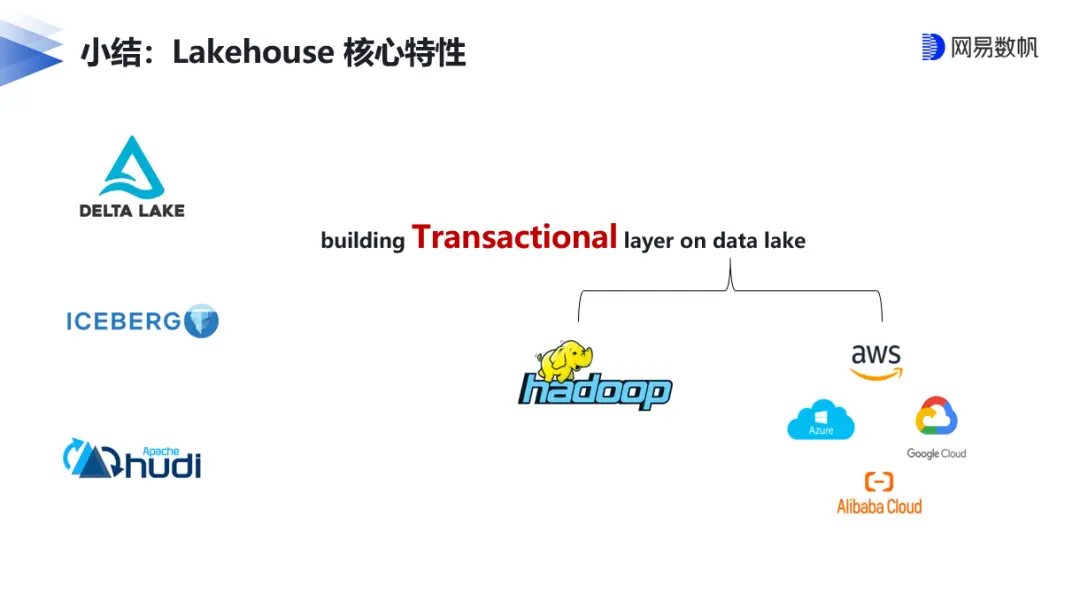
以網易為例,從T+1 離線數據生產,到引入實時化並不斷完善,如引入Apache Kudu解決Hive離線數倉在實時數據更新上的不足,形成了流批分割的Lambda架構(這也是業界大數據架構演進的一個縮影),然後數據孤島、研發體系割裂以及指標和語義的二義性等問題逐漸暴露,這就需要一個更加優雅的統一數據基礎設施架構,也就是湖倉一體來解決。基於數據湖開源三劍客(Delta Lake、Apache Iceberg、Apache Hudi)的實現方案,則成為了熱門的選擇。
網易數帆流式湖倉的創新
儘管在造詞法上Lakehouse確實是Data Lake和Data Warehouse的縫合怪,然而要成為生產級的新技術,湖倉一體畢竟不是數據湖和數據倉庫1+1=2那麼簡單。在馬進看來,目前湖倉一體方案存在兩大不足:一是所讀即所寫,會產生流式攝取導致海量小文件等問題;二是實時能力不足,比如基於湖倉一體的流計算延遲在分鐘級別。
基於此,馬進帶領團隊研發了命名為Arctic的流式湖倉服務,提出了五個設計目標:提供可靠的湖倉一體服務,解決主流湖倉一體的不足,面向更多流批一體的場景,儘可能不要重複造輪子,和尋求代際型解決方案。
技術方案上,Arctic搭建在Iceberg表格式之上,複用Iceberg各種功能,並完全兼容Hive。Arctic面向流場景提供優化的CDC(變更數據獲取)和流式更新能力,也可以開放式地集成 MQ、KV 等中間件,向 Flink、Spark、Trino 等主流計算引擎提供流批統一的表服務,以實現數據湖和數倉的統一,並融入實時的能力,流計算延遲可達毫秒級。
由此,Arctic 可視為一個獨立的實時數倉服務,用户無需關心數據存儲結構、大小和分佈,或是否引入其他中間件。
流式湖倉的未來
三十年前,西方學者面對社會變遷發出“歷史的終結”的感慨,但歷史已經給這一論斷打臉。那麼,流式湖倉又是否會成為現代大數據基礎架構的終點?回顧數據分析領域,先後出現的數據倉庫、OLAP、BI、大數據、數據中台等各種方法論,都已融入企業數據生命週期,而底層的Hadoop體系依然在廣泛使用,我們有理由相信,流式湖倉服務這一源自業務需求的設計,實現方式可能會升級,但這一思想必將長存於數據基礎設施。
從A16Z的全景圖我們也可以看到,企業級數據基礎設施架構的穩定往往伴隨着長時間的沉澱,而Arctic開放的架構及對Hadoop生態的兼容,已經預示着它的生命力。
秉承網易數帆“架構開放,內核開源”的理念,Arctic即將開源!

和我們一起探討湖倉一體落地實踐的關鍵要素,共同促進開放架構數據基礎設施生態完善與發展,歡迎點擊鏈接:i.163yun.com/n1pvp4086報名參加。