通義大模型微信公眾號發文宣佈,推出新一代端到端語音交互模型 Fun-Audio-Chat。“不是簡單的“能聊天”,而是聽得懂你的話、感知你的情緒、還能幫你真正幹活的AI語音搭子。”
目前開源了 Fun-Audio-Chat 8B,包括模型權重、推理代碼、Function Call 接入示例。
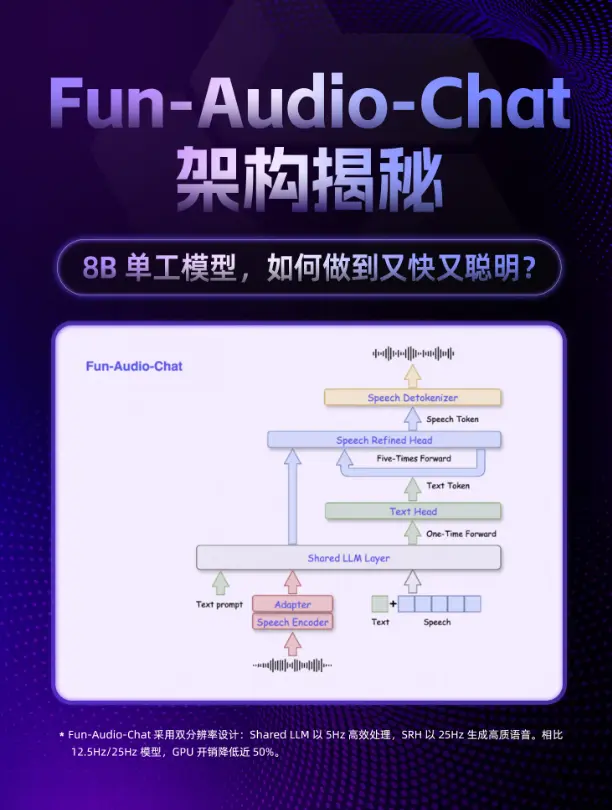
技術表現:
- 端到端 S2S 架構:從語音輸入直接生成語音輸出,無需 ASR + LLM + TTS 多模塊拼接,效率更高、延遲更低。
- 雙分辨率設計:Shared LLM 層以 5Hz 幀率 高效處理,SRH 以 25Hz 幀率 生成高質量語音,GPU 計算開銷降低近 50%。
- 百萬小時多任務數據訓練:覆蓋音頻理解、語音問答、情感識別、工具調用等真實場景,讓模型更“接地氣”。
高情商:像朋友一樣的對話體驗
- 你生氣時,它會安慰你;你焦慮時,它會陪你深呼吸;你開心時,它會跟着你一起嗨。
- 哪怕你沒直接説情緒,它也能從你的語氣、語速、停頓裏,猜出你的心情,然後給出恰到好處的迴應。
易落地:它不僅能聊,還能“幹實事”
- Speech Function Call:你只需用自然語音下達指令,它就能自動調用函數,完成複雜任務。
測評結果顯示,Fun-Audio-Chat 8B 在 OpenAudioBench、MMAU、Speech-ACEBench、VStyle 等多個權威榜單上,同尺寸模型排名第一,綜合性能遠超 GLM4-Voice、Kimi-Audio、Baichuan-Omni。
