東北大學“小牛翻譯”團隊最近提出了以中文和英文為雙中心的多語言翻譯模型 LMT (Large-scale Multilingual Translation)。LMT覆蓋60種語言、234個方向,包括英↔59語種及中↔58語種方向,覆蓋了全球主要語言家族與廣泛使用語言。
支持語言:
|
語言資源 |
語言列表 |
|
高資源13種 |
阿拉伯語(ar)、英語(en)、西班牙語(es)、德語(de)、法語(fr)、意大利語(it)、日語(ja)、荷蘭語(nl)、波蘭語(pl)、葡萄牙語(pt)、俄語(ru)、土耳其語(tr)、中文(zh) |
|
中資源18種 |
保加利亞語(bg)、孟加拉語(bn)、捷克語(cs)、丹麥語(da)、現代希臘語(el)、波斯語(fa)、芬蘭語(fi)、印地語(hi)、匈牙利語(hu)、印度尼西亞語(id)、韓語(ko)、挪威語(no)、羅馬尼亞語(ro)、斯洛伐克語(sk)、瑞典語(sv)、泰語(th)、烏克蘭語(uk)、越南語(vi) |
|
低資源29種 |
阿姆哈拉語(am)、阿塞拜疆語(az)、藏語(bo)、希伯來語(he)、克羅地亞語(hr)、亞美尼亞語(hy)、冰島語(is)、爪哇語(jv)、格魯吉亞語(ka)、哈薩克語(kk)、高棉語(km)、柯爾克孜語(ky)、老撾語(lo)、中國蒙古語(mn_cn)、馬拉地語(mr)、馬來語(ms)、緬甸語(my)、尼泊爾語(ne)、普什圖語(ps)、僧伽羅語(si)、斯瓦希里語(sw)、泰米爾語(ta)、泰盧固語(te)、塔吉克語(tg)、他加祿語(tl)、維吾爾語(ug)、烏爾都語(ur)、烏茲別克語(uz)、粵語(yue) |
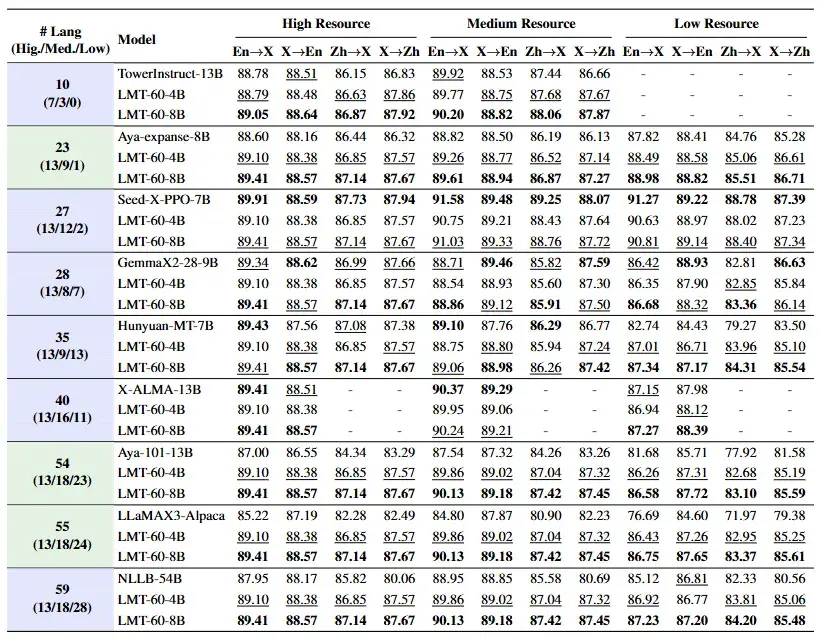
在 FLORES-200 基準上,LMT 在同等語言覆蓋規模的模型中取得了SOTA性能,實現了較廣泛的語言覆蓋度和全面的翻譯能力。
LMT基於Qwen3系列模型構建,採用主流的兩階段訓練流程:
-
繼續預訓練(Continued Pre-training, CPT):在混合單語與雙語的大規模語料上繼續預訓練,廣泛提升模型的多語言翻譯能力。
-
有監督微調(Supervised Fine-tuning, SFT):利用高質量的人工標註平行數據進行指令微調,進一步增強模型翻譯性能。
其中,CPT的規模約 90B tokens,每個語言方向按照1:1:1 比例混合單語、中文中心雙語與英文中心雙語。
SFT使用公開的高質量人工標準數據集,包括FLORES-200 Dev, NTREX-128, SMol, WMT14-23,IWSLT17-24測試集共計約 567K 條,覆蓋 117 個翻譯方向,每個翻譯方向大約 3K–20K條樣本。
LMT現已開源,共包含四種規模:0.6B/1.7B/4B/8B。
GitHub:https://github.com/NiuTrans/LMT
Huggingface:
- https://huggingface.co/NiuTrans/LMT-60-0.6B
- https://huggingface.co/NiuTrans/LMT-60-1.7B
- https://huggingface.co/NiuTrans/LMT-60-4B
- https://huggingface.co/NiuTrans/LMT-60-8B
