由清華大學THUNLP實驗室、東北大學NEUIR實驗室、OpenBMB與AI9Stars聯合開發的 UltraRAG2.1 已正式發佈,成為全球首個基於Model Context Protocol(MCP)架構的開源RAG框架。該版本徹底簡化多模態智能檢索系統的構建流程——研究人員僅需編寫幾行YAML配置文件,即可實現多階段推理、生成與評估,無需一行代碼,大幅降低技術門檻。
UltraRAG2.1內置Retriever-Generation-Evaluation一體化流水線,不僅支持文本,還能處理圖像、PDF等多模態數據。其創新性VisRAG Pipeline可直接解析本地PDF文檔,自動提取文字與圖表,構建跨模態索引,實現“問圖答文、以文搜圖”的混合檢索,適用於科研論文分析、技術手冊問答等高價值場景。
框架支持Word、PDF、Markdown等多種格式的智能解析與語義分塊,並無縫集成開源文檔處理工具MinerU,可一鍵構建企業級私有知識庫。用户無需手動清洗或標註數據,系統自動完成結構化處理,讓知識管理效率提升數倍。
UltraRAG2.1提供全鏈路可視化RAG工作流,兼容多種檢索引擎(如Elasticsearch、FAISS)與生成模型(Llama、Qwen、Kimi等),並引入標準化評估體系,從相關性、忠實度、流暢性等維度量化結果質量。開發者可直觀定位瓶頸,快速迭代優化。
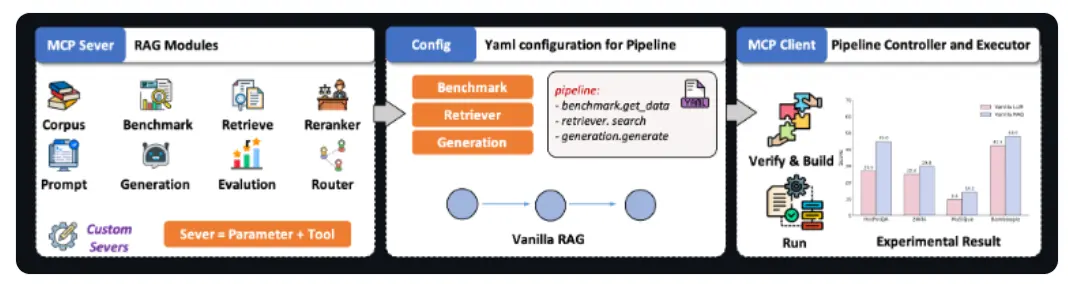
區別於傳統RAG的硬編碼模式,UltraRAG2.1基於模型上下文協議(MCP),將檢索、推理、生成等模塊解耦為標準化“智能體”,通過YAML聲明式配置即可靈活組裝複雜任務流。例如,僅需幾行配置,即可實現“先檢索技術文檔→再調用代碼生成模型→最後用評估模塊校驗輸出”的三階段工作流。
