斯坦福大學教授、World Labs 聯合創始人李飛飛近日發表了一篇名為《From Words to Worlds: Spatial Intelligence is AI’s Next Frontier》(從語言到世界:空間智能是AI的下一個前沿)的長文。
她表示,真正的智能,從來不只是“會説話”——而是理解並駕馭物理世界的能力,即“空間智能”(Spatial Intelligence)。若AI無法掌握空間推理、物體關係與動態預測,所謂的“通用人工智能”終將是空中樓閣。
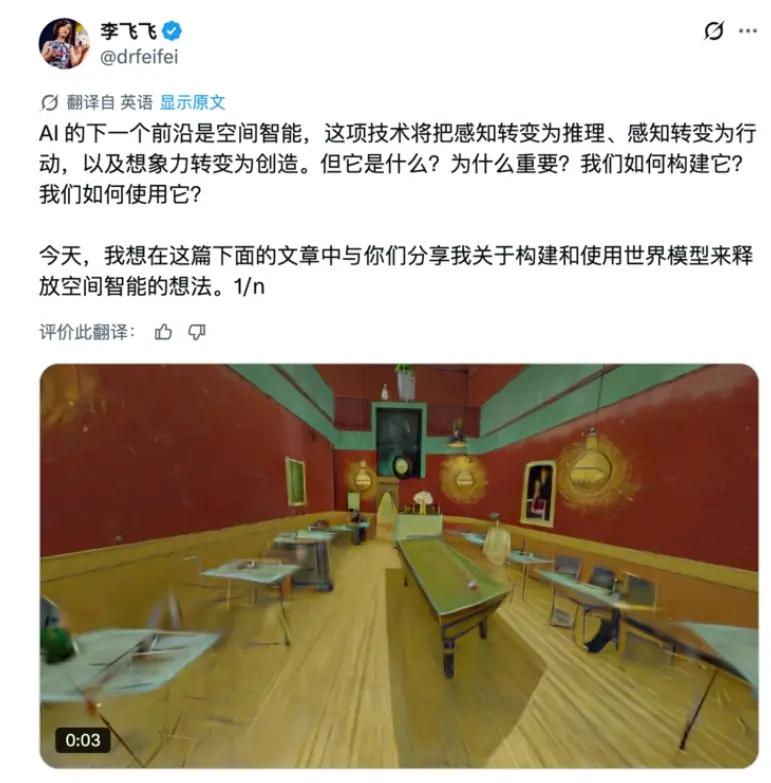
並強調,空間智能是人類認知的基石,遠早於語言出現。從嬰兒伸手抓握玩具,到科學家通過X射線衍射圖推演出DNA雙螺旋結構;從古希臘人用影子測算地球周長,到工程師設計自動駕駛路徑——這些突破無不依賴對空間、形狀、運動與因果關係的深刻理解。而當前主流大模型雖能流暢生成文本,卻對“杯子放在桌子邊緣是否會掉落”這類基礎物理常識頻頻出錯。
要突破這一瓶頸,李飛飛提出必須構建新一代世界模型(World Model)——一種能對物理環境進行生成、交互與狀態預測的多模態系統。該模型需具備三大核心能力:
- 感知三維甚至四維(含時間),而非僅處理二維圖像;
- 理解動作與結果的因果鏈,例如“推倒積木塔”後的連鎖反應;
- 通過主動交互學習,而非被動接受標註數據。
實現這一目標面臨三大挑戰:新型訓練範式(替代“下一個詞預測”)、從海量視頻中提取深層空間結構、以及支持3D/4D推理的新神經架構。目前,李飛飛團隊正全力攻關,試圖將計算機視覺、具身智能與生成式AI深度融合。
李飛飛認為,空間智能的具體演進路徑為:近期:賦能電影、遊戲與虛擬敍事,實現更真實的動態場景生成;中期:讓服務機器人真正理解家庭環境,安全遞送物品、協助老人;長期:推動科學發現(如分子摺疊模擬)、精準醫療(手術路徑規劃)與沉浸式教育。
此外,李飛飛還重申了其一貫立場:“AI的終極目標不是替代人類,而是擴展人類的能力邊界。”呼籲學界、產業界共建開放、負責任的空間智能生態,確保技術紅利普惠全人類。
