來自蘇黎世大學、阿姆斯特丹大學、杜克大學和紐約大學的研究團隊近日發佈了一項最新研究,揭示了大語言模型生成的社交媒體帖子在內容識別方面的不足。研究表明,這些 AI 生成的帖子在各大社交平台上容易被人類識別,識別準確率達到70% 至 80%,遠高於隨機猜測的結果。
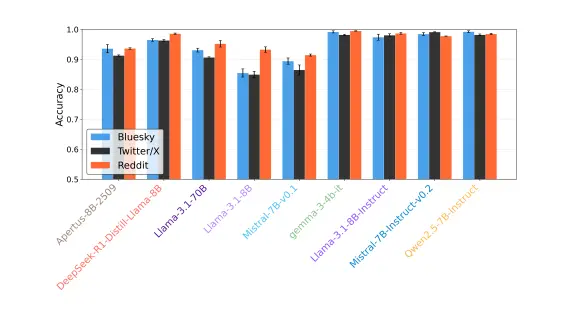
研究人員測試了九個不同的大語言模型,包括 Apertus、DeepSeek、Gemma、Llama、Mistral、Qwen 等,分析了它們在 Bluesky、Reddit 和 X 平台上的表現。
結果顯示,這些 AI 生成的內容在 “毒性評分” 上具有顯著差異,這成為區分 AI 與人類帖子的重要因素。換句話説,如果在某個帖子下出現特別尖鋭或搞笑的評論,那麼這很可能是人類用户所寫。
研究指出,雖然大語言模型可以模仿在線對話的形式,但在捕捉情感表達方面卻顯得捉襟見肘。自發和富有感情的表達是人類社交互動的特點,而 AI 在這方面的表現遠不如人類。此外,研究還發現,在特定情況下,例如在馬斯克的 X 平台上發表積極情感或在 Reddit 上討論政治,AI 模型的表現尤為不佳。
從整體來看,參與測試的 AI 模型在模仿 X 平台的帖子時表現較好,而在 Bluesky 上則稍顯遜色,Reddit 則是三者中最具挑戰性的,因為該平台的對話規範更加複雜。同時,研究也發現,某些未經過人類指令微調的 AI 模型表現較好,這説明過度的訓練可能使模型的風格變得過於一致,從而導致內容更加機械化。
