StepFun AI 近日發佈了其開源的音頻編輯模型 Step-Audio-EditX,這一創新的3B 參數模型將音頻編輯的操作變得像文本編輯一樣直接和可控。通過將音頻信號的編輯任務轉換為逐字的令牌操作,Step-Audio-EditX 使得表達性的語音編輯變得更加簡單。
目前,大多數零樣本文本到語音(TTS)系統在情感、風格、口音和音色的控制上都顯得有限。儘管它們可以生成自然的語音,但往往無法精確地符合用户的需求。過去的研究嘗試通過額外的編碼器和複雜的架構來拆分這些因素,而 Step-Audio-EditX 則通過調整數據和訓練目標來實現控制。
Step-Audio-EditX 採用了雙代碼本的標記器,將語音映射為兩個令牌流,一個是以16.7Hz 的速率記錄的語言流,另一個是以25Hz 的速率記錄的語義流。模型在一個包含文本和音頻令牌的混合語料庫上進行了訓練,使其能夠同時處理文本和音頻令牌。
該模型的關鍵在於採用大邊距學習的方法,後續訓練階段利用合成的大邊距三元組和四元組來增強模型的表現。通過使用約60000名説話者的高質量數據,模型在情感和風格編輯方面表現出色。此外,模型還利用人類評分和偏好數據進行強化學習,以提高語音生成的自然性和準確性。
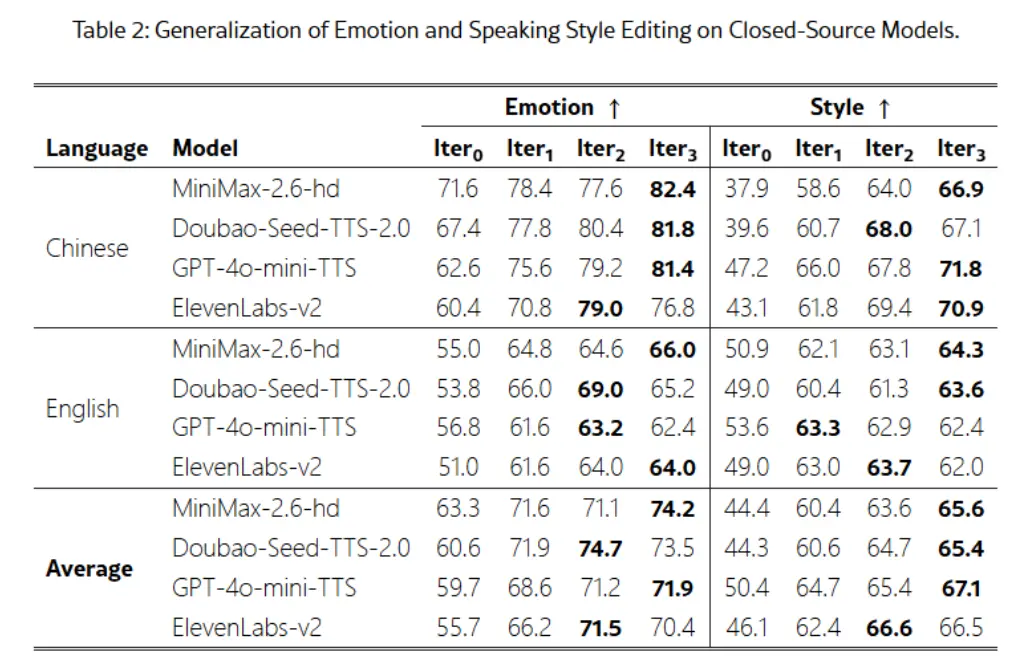
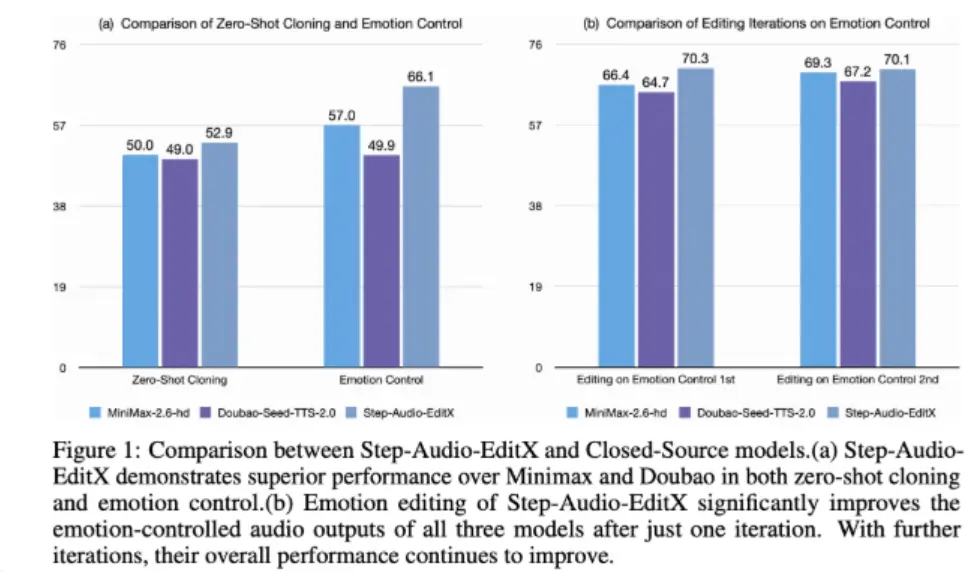
為了評估模型的效果,研究團隊引入了 Step-Audio-Edit-Test 基準,使用 Gemini2.5Pro 作為評判工具。測試結果顯示,經過多輪編輯,模型在情感和説話風格的準確性上都顯著提升。此外,Step-Audio-EditX 還可以有效提升其他閉源 TTS 系統的音頻質量,為音頻編輯的研究帶來了新的可能性。
