作者:高玉龍(元泊)
背景介紹
當用户使用 App 時產生不好的體驗,問題往往出現在以下場景:
- 打開復雜頁面時出現黑屏/白屏延遲
- 列表滑動時偶發性卡頓
- 圖片加載時界面響應滯後
- 網絡請求密集時出現操作卡死等現象
這些場景不僅出現在低端設備上,在中高端機型中同樣存在。如果主線程無法響應用户的交互就會造成卡頓,卡頓時間比較長是比較影響 App 的功能和用户體驗的。在移動應用開發中,卡頓問題也始終是影響用户體驗的核心痛點。
通常情況下,導致主線程阻塞並引發卡頓的原因主要有以下幾種:
- 繁重的 UI 渲染:當界面包含複雜的視圖層級、大量的圖文混排內容時,計算佈局和繪製到屏幕上的工作量會急劇增加,超出單次刷新週期的處理能力。
- 主線程同步網絡請求:在主線程中發起同步的網絡調用,意味着整個應用必須等待網絡數據返回後才能繼續執行,期間無法響應任何用户操作。
- 大量的文件讀寫(I/O):在主線程上直接進行大規模的數據讀取或寫入操作,例如讀寫數據庫或本地文件,會因為磁盤速度的限制而消耗大量時間。
- 高負荷的計算任務:將複雜的算法或大量數據的處理邏輯直接放在主線程執行,會導致 CPU 持續處於高佔用狀態,無暇顧及 UI 事件。
- 線程鎖使用不當:當主線程需要等待其他線程釋放某個鎖資源時,它會被掛起,如果等待時間過長,便會造成卡頓。在極端情況下,不同線程間的相互等待還會引發"死鎖",導致應用徹底無響應。
由於這些問題的偶發性和環境依賴性,傳統的線下調試手段往往難以奏效。為了能夠精確、高效地定位並解決這些線上卡頓,我們進行一些卡頓監控技術的探索。
主流卡頓監控方案
在 iOS 開發中,以下是幾種常見的主流卡頓監控方案:
- Ping 線程方案
- FPS 監控方案
- RunLoop 監控方案
Ping 線程方案簡介
Ping 線程方案的核心思想是:
- 創建一個子線程,通過子線程來"探測"主線程的響應能力。
- 子線程每次 ping 主線程時設置標記位為 YES,然後派發任務到主線程中,主線程把標記位設置為 NO。
- 子線程 sleep 指定時間,超時後判斷標記位是否設置為 NO,如果沒有説明主線程發生了卡頓。
如下圖所示:
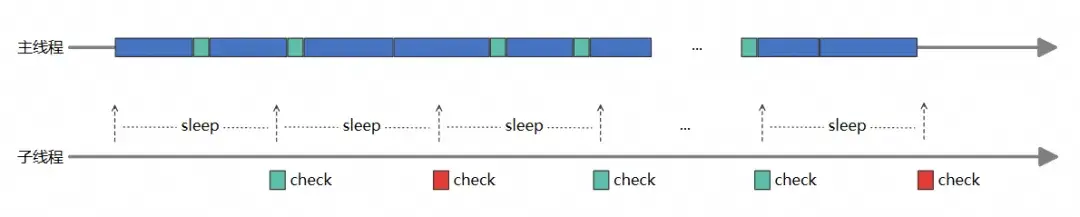
關鍵實現步驟:
-
創建子線程:啓動一個獨立的監控線程。
-
定時派發任務:子線程定期向主線程派發一個簡單的任務,並設置一個等待標記。
-
等待主線程響應:主線程執行該任務時,會回調子線程,並清除等待標記。
-
超時判斷:如果子線程在派發任務後的一小段時間內,發現等待標記仍未被清除,則判定主線程卡頓。
-
捕獲與上報:執行堆棧捕獲和上報流程。
Ping 線程的方案邏輯相對比較簡單,也比較容易理解。但精度較差,Ping 之間可能存在漏查的情況。同時,Ping 線程會不停喚醒主線程 RunLoop,也會存在一定的性能損耗。
FPS 監控方案簡介
通常情況下屏幕會保持 60Hz/s 的刷新速度(新的 iOS 設備甚至會保持 120Hz/s 的刷新速度),每次刷新時會發出一個屏幕刷新信號,CADisplayLink 允許開發者註冊一個與刷新信號同步的回調處理。
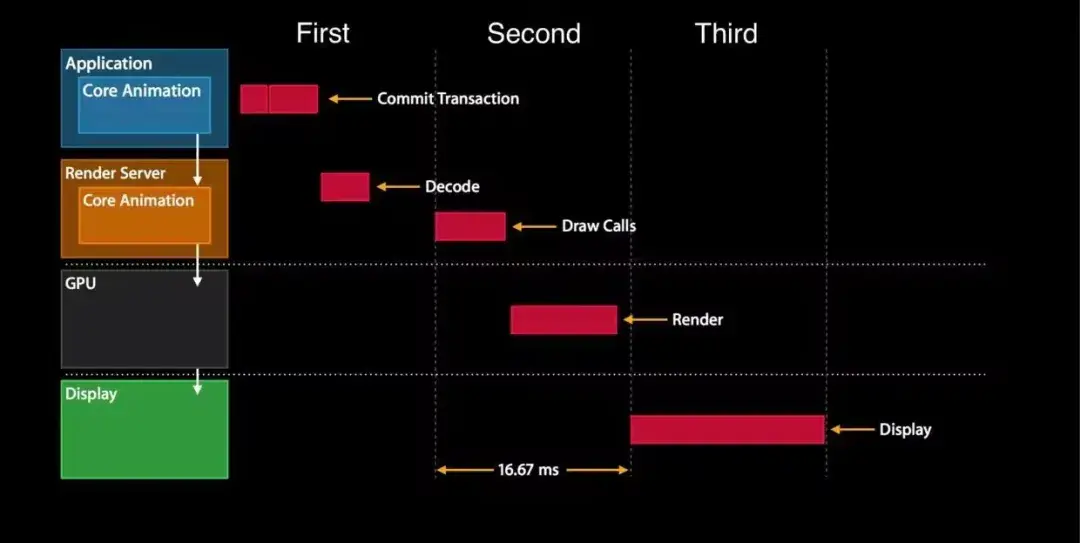
我們可以通過計算它 1 秒內調用多少次來查看界面的流暢度。雖然 CADisplayLink 更輕量,但需要在 CPU 稍微清閒時才能夠回調,嚴重卡頓的堆棧獲取不一定及時,並且就算 50fps 以下通過肉眼來看也是連貫的。所以,簡單的通過監控 FPS 很難確定是否出現了卡頓問題。
RunLoop 方案簡介
基於 RunLoop 的監控方案,是目前比較主流的可用於生產環境的監控方案。其原理是利用 CFRunLoopObserver 來觀察主線程 RunLoop 的狀態變化。這裏通過引用戴銘關於 RunLoop 原理的圖,來對 RunLoop 方案的原理進行簡單介紹:
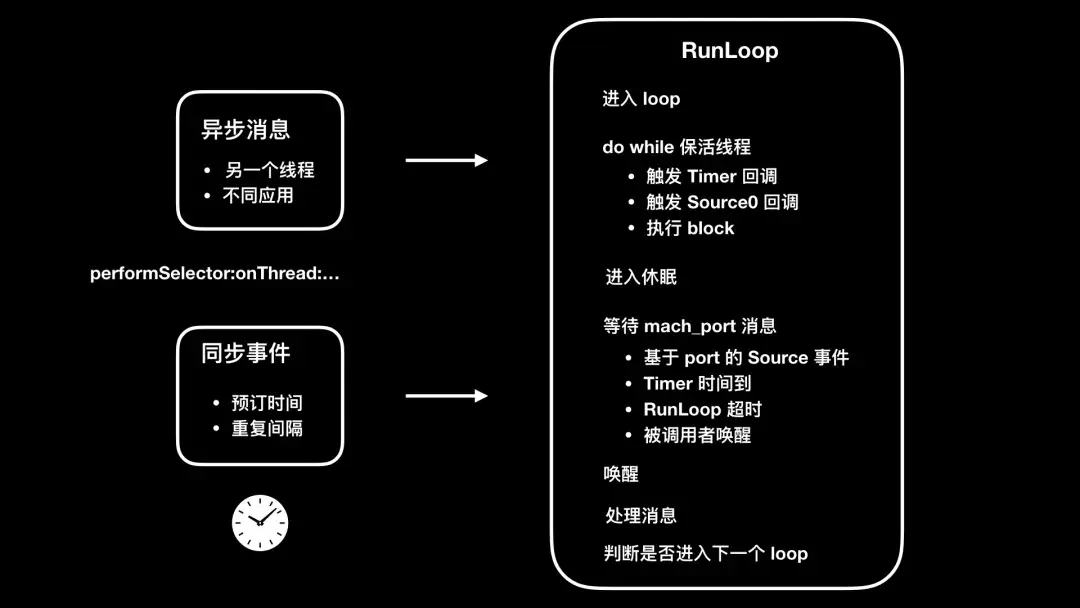
- 通知 observers:RunLoop 即將開始"進入 loop"
- 隨後,會開啓一個 do while 來保活線程
- 通知 obersers:RunLoop 會觸發 Timer、Source0 回調,緊接着執行加入的 block
- 如果 Source1 是 ready 狀態,會跳轉到"處理消息"流程
- 通知 observers:RunLoop 即將進入休眠狀態
- 等待 mach_port 消息,以再次喚醒
- 基於 port 的 Source 事件
- Timer 時間到
- RunLoop 超時
- 被調用者喚醒
- 通知 observers:RunLoop 被喚醒
- 處理消息
- 繼續下一個 loop
基於 RunLoop 的方案實現中,一般會包含下面幾個關鍵步驟:
-
註冊 Observer:向主線程 RunLoop 註冊 Observer 來監聽其狀態。
-
創建監控線程:用於監控主線程切換狀態。
-
狀態標記與超時判斷:子線程根據 RunLoop 的狀態變化來設置標記,並循環檢測該標記是否在預設的閾值內被更新,否則判定為卡頓。
-
堆棧捕獲與上報:判定為卡頓時,捕獲主線程的調用堆棧,並上報服務器進行分析。
基於 RunLoop 的方案能夠精準捕獲到由主線程阻塞導致的各類卡頓,適用於線上卡頓問題的監控和診斷分析。
方案對比
基於主流方案對比分析,三種性能監控策略分別聚焦不同維度,如下表:

- Ping 線程方案通過子線程週期性探測主線程響應時間識別卡頓,但精度低於 RunLoop 方案。
- FPS 監控作為全局性能指標,通過幀率波動反映應用流暢度並判斷卡頓,卻無法定位性能瓶頸。
- RunLoop 方案則介入主線程事件循環機制,實現單次阻塞事件的毫秒級捕捉,可精準識別主線程阻塞源。
卡頓監控方案實現
卡頓監控方案的核心目標在於精準捕獲並定位導致用户操作中斷、體驗顯著下降的"阻塞型"卡頓。當卡頓發生時,不僅包括識別卡頓事件的發生,更需追溯具體代碼行級的執行路徑以定位問題根源。
相較於其他主流方案,RunLoop 監控方案通過持續追蹤主線程任務執行耗時,能夠精確捕獲卡頓事件並同步採集完整的上下文調用堆棧信息。儘管其技術實現複雜度較高,但考慮到可部署於線上環境,以及對卡頓根因的診斷價值,最終被選定為核心實現方案。
上文中已經對 RunLoop 的原理有過大致的介紹,下文中將主要介紹如何具體實現。
監控 RunLoop 狀態
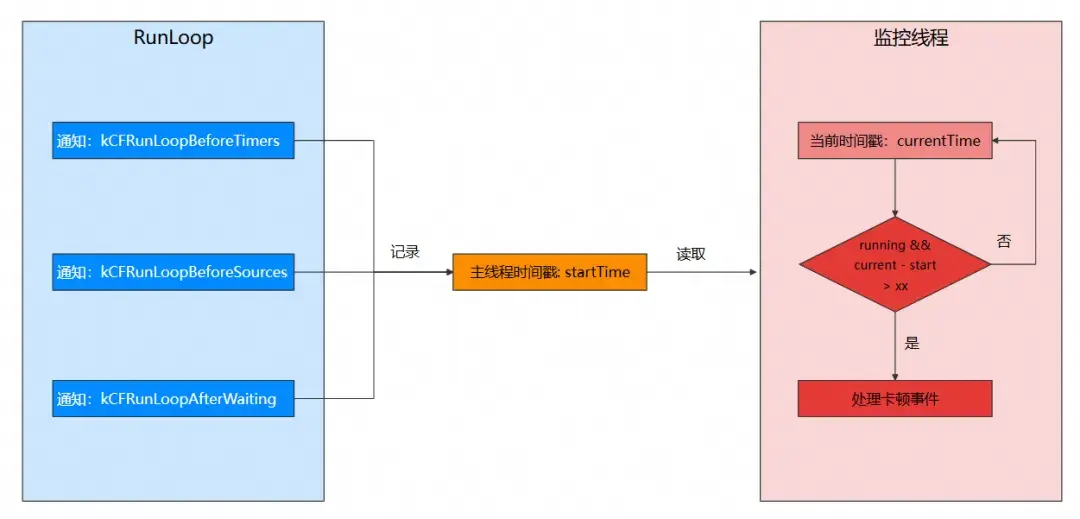
基於 RunLoop 實現卡頓監控方案,需要先監控 RunLoop 的狀態切換。如下圖,通過註冊的 Observer 可以監聽到主線程 RunLoop 狀態的切換事件,並通過 running 和 startTime 來記錄關聯的狀態和時間戳信息。監控線程通過讀取 running 狀態,以及 startTime 來判斷是否產生了狀態超時:
當主線程在執行某個任務的耗時較長時,RunLoop 的狀態切換就會延時。通過在子線程監控 RunLoop 關鍵狀態之間的時間差,就可以判斷主線程是否發生了阻塞。

方案實現中:
- 當 Observer 收到
kCFRunloopBeforeTimers、kCFRunloopBeforeSource、kCFRunLoopAfterWaiting通知時,會把running狀態置為 YES,並通過startTime記錄當前時間戳。 - 當 Observer 收到
kCFRunloopBeforeWaiting和kCFRunLoopExit通知時,把running狀態置為 NO。 - 監控線程需要持續讀取
running狀態和startTime時間戳,通過判斷當前時間與startTime的差異來確定是否發生了卡頓,如下圖:
堆棧提取
當 RunLoop 狀態超時,即檢測到卡頓時,需要提取主線程堆棧並保存到內存中。堆棧的提取方案基於業界知名的 KSCrash 實現。相比通過系統函數獲取堆棧,通過 KSCrash 獲取的堆棧可以配合 dSYM 進行符號還原,能夠定位到具體的代碼位置,而且性能消耗也不大。
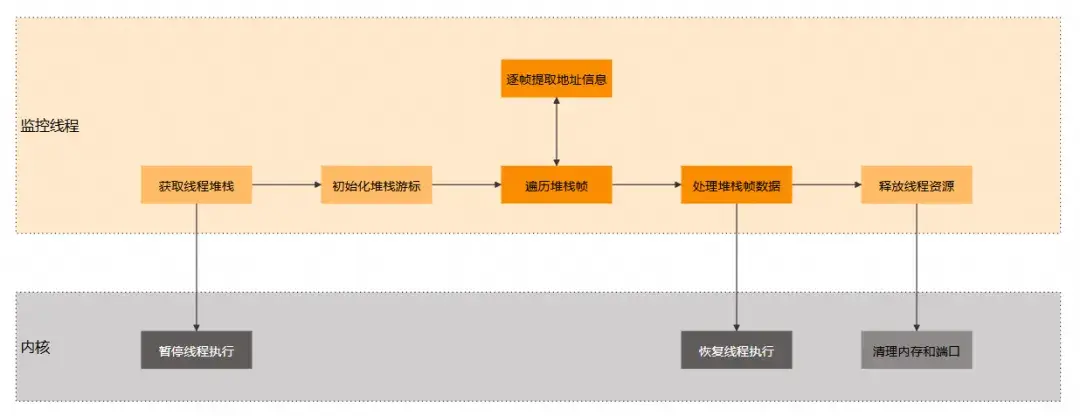
耗時堆棧提取
當監控線程監測主線程 RunLoop 時,會獲取主線程的線程快照作為卡頓堆棧。但是,這個主線程堆棧不一定是最耗時的堆棧,也不一定是導致主線程超時的主要原因。為了對這個問題進行優化,需要在檢測到主線程發生卡頓時,通過對保存在循環隊列中的堆棧進行回溯(間隔 50ms 獲取一次),獲取最近最耗時堆棧。
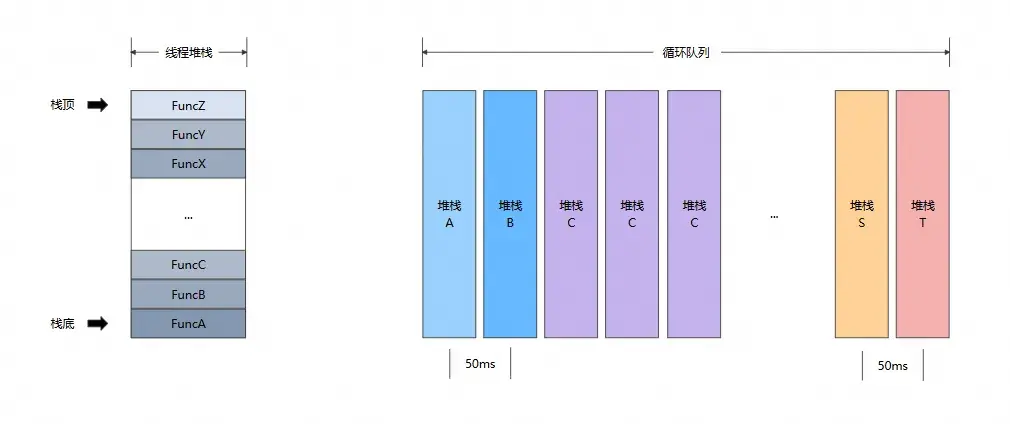
如上圖所示,通過以下特徵找出最近最耗時堆棧:
- 以棧頂函數為特徵,棧頂函數相同的,整個堆棧就是相同的,如:
- 堆棧 A 的棧頂調用函數為 FuncA
- 堆棧 B 的棧頂調用函數為 FuncB
- 棧頂函數 FuncA 與 FuncB 不同,因此堆棧 A 和堆棧 B 為不同的堆棧
- 獲取堆棧間隔相同,堆棧的重複次數近似作為堆棧的調用耗時,重複越多耗時越多,如:
- 堆棧 A 重複一次,近似耗時為 50ms
- 堆棧 B 重複一次,近似耗時為 50ms
- 堆棧 C 重複三次,近似耗時為 150ms
- 堆棧 C 為最耗時堆棧
- 重複次數相同的堆棧中,取最近的一個作為最耗時堆棧
監控線程退火算法
卡頓檢測機制在無異常場景下性能開銷可忽略,但遭遇持續數秒級卡頓時,頻繁採集主線程堆棧信息時將引發顯著性能損耗。且連續重複的堆棧記錄無分析價值,完全沒有必要。為了降低卡頓監測帶來的性能損耗,SDK 採用了退火算法遞增時間間隔,避免因同一個卡頓問題帶來的性能問題。
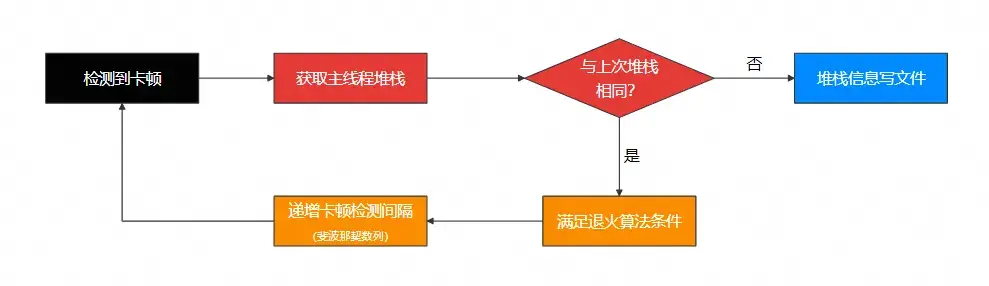
- 每次子線程檢測到主線程卡頓,會先獲取主線程的堆棧,並保存到內存中
- 把獲得的主線程堆棧與上次卡頓獲得的線程堆棧進行比對
- 不同:獲得當前線程快照並寫入到文件
- 相同:跳過,並按照斐波那契數列把檢測時間遞增,直到沒有卡頓或卡頓堆棧不同
以上算法可以避免同一個卡頓寫入多個文件的情況,避免檢測線程遇到主線程卡死的情況下,不斷寫線程快照文件。
性能開銷
任何一個監控工具的首要原則是不能影響被監控對象的性能。因此,我們還需要測量基於 RunLoop 的卡頓監控方案對應用性能的實際影響。性能測量的核心是進行 A/B 對比測試。我們需要準備兩個幾乎完全相同的 App 版本:
- A 版本(基準版本):卡頓監控功能完全禁用。
- B 版本(監控版本):卡頓監控功能完全開啓。
然後在完全相同的設備和環境下,對這兩個版本執行相同的操作,並測量關鍵性能指標的差異。這個差異就是卡頓監控帶來的性能開銷。
測試設備:iPhone 12 Pro
測試系統:iOS 18.7
卡頓監控功能沒有開啓的情況下,App 持續運行一段時間並主動觸發卡頓,App 整體的 CPU 佔用如下圖:
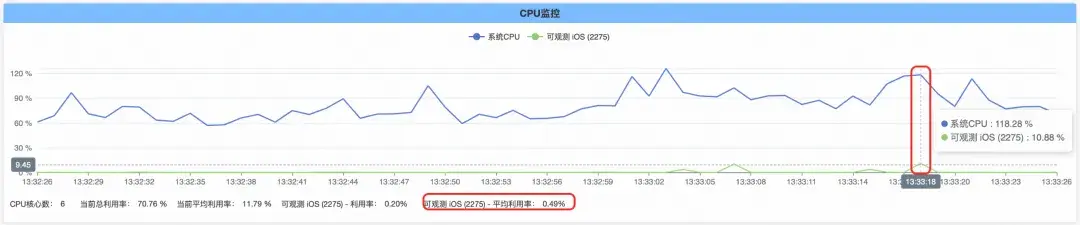
卡頓監控功能開啓的情況下,App 持續運行一段時間並主動觸發卡頓,App 整體的 CPU 佔用如下圖:
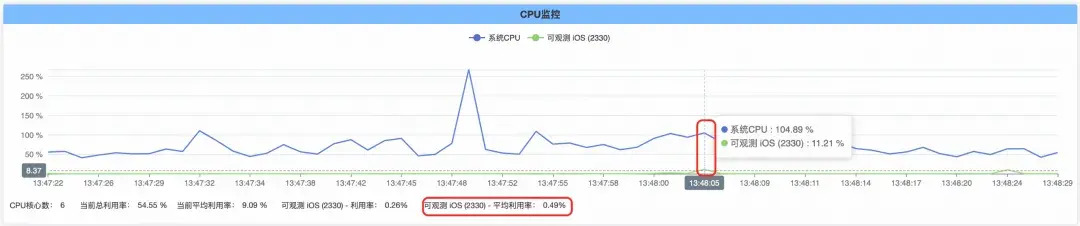
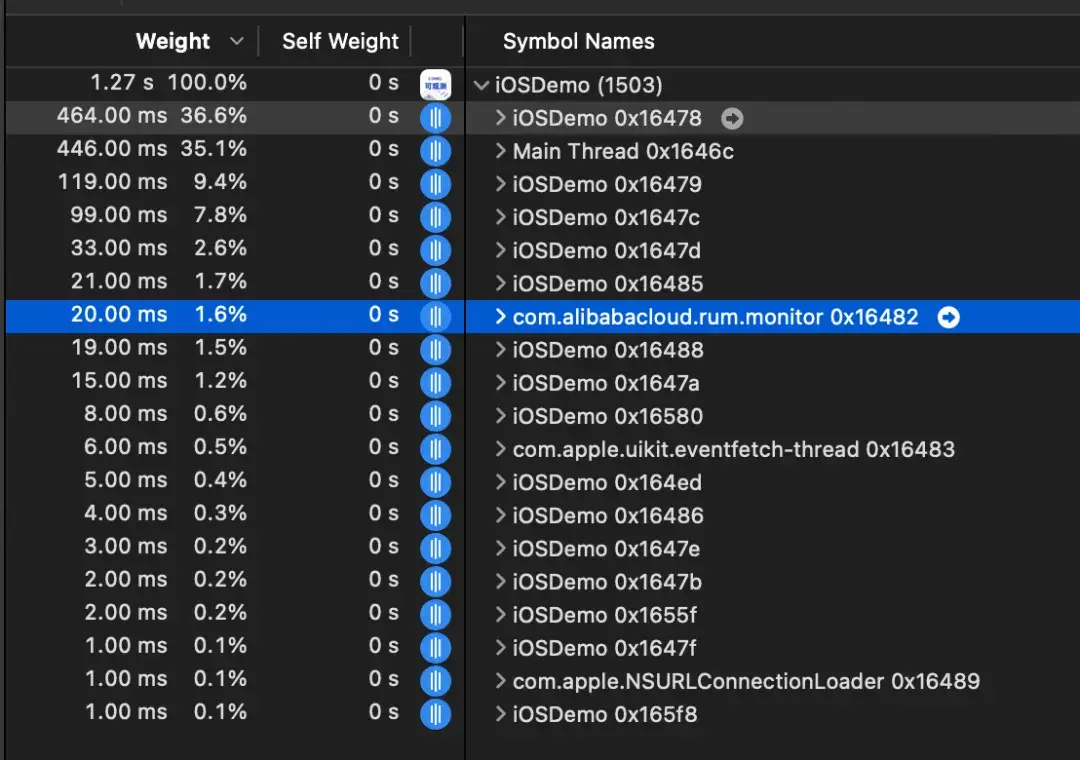
在卡頓監控開啓情況下,監控線程的 CPU 佔用如下。
有卡頓發生時:
無卡頓發生時:
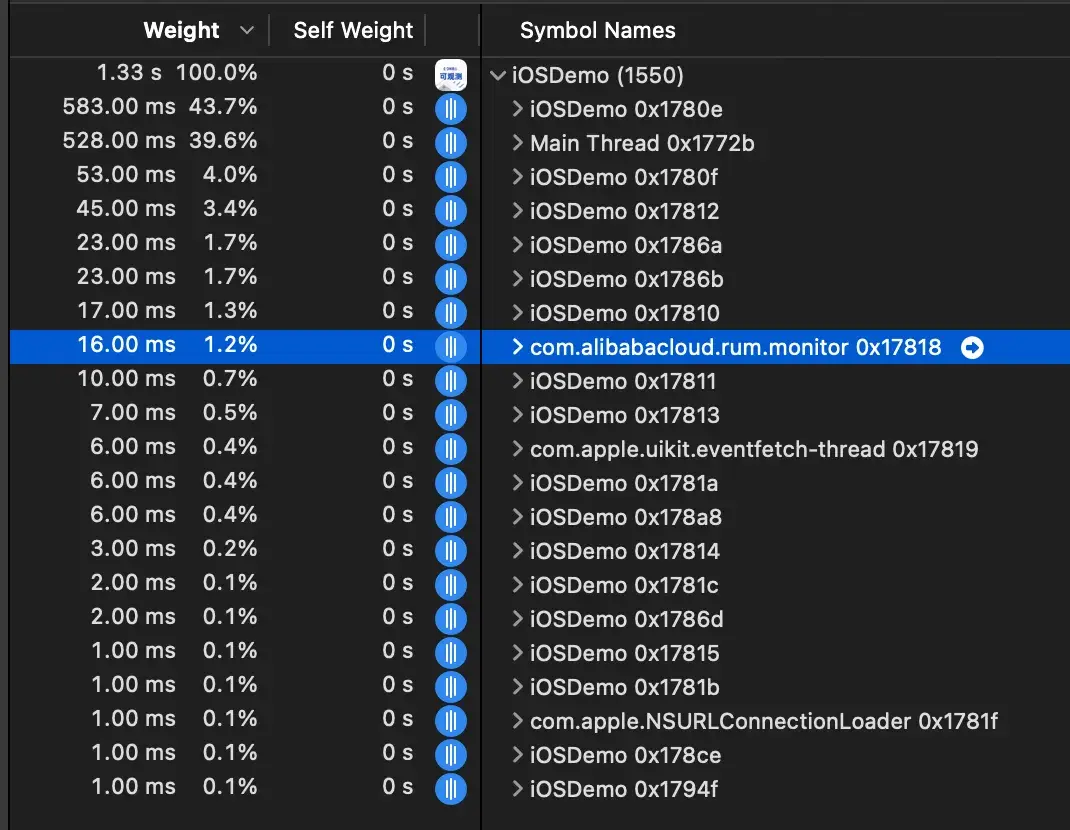
綜上分析,App 引入卡頓監控能力後:
- 無卡頓發生時,對 App 性能幾乎無影響
- 有卡頓發生時,App 整體 CPU 佔用增加約 0.33%(不同設備的測試值會略有差異)
總結
本文主要介紹了當下主流的 iOS 卡頓監控方案,和基於 RunLoop 的卡頓監控實現細節,包括 RunLoop 狀態的處理,堆棧以及耗時堆棧的提取,持續卡頓場景下的退火處理等。卡頓監控方案的實現過程中,通過融合行業成熟優秀的方案思路,實現了主線程阻塞卡頓的檢測能力。卡頓監控能力還在持續進化,後續還有不少可以優化和提升的點,如支持高 CPU 佔用卡頓、啓動卡頓等的檢測。目前這套方案已經應用在阿里雲 ARMS 用户體驗監控 iOS SDK 中,您可以參考接入文檔 [ 1] 體驗使用。相關問題可以加入"RUM 用户體驗監控支持羣"(釘釘羣號:67370002064)進行諮詢。
相關鏈接:
[1] 接入文檔
https://help.aliyun.com/zh/arms/user-experience-monitoring/monitor-ios-apps/
