微軟開源了 9B 參數的全新統一語音識別模型 VibeVoice-ASR,支持處理長達 60分鐘的長音頻,能夠在單次處理中生成包含説話人身份、精確時間戳和文本內容的結構化轉錄結果。模型支持用户自定義熱詞以提升特定領域的識別準確率。
VibeVoice-ASR 主要特性:
-
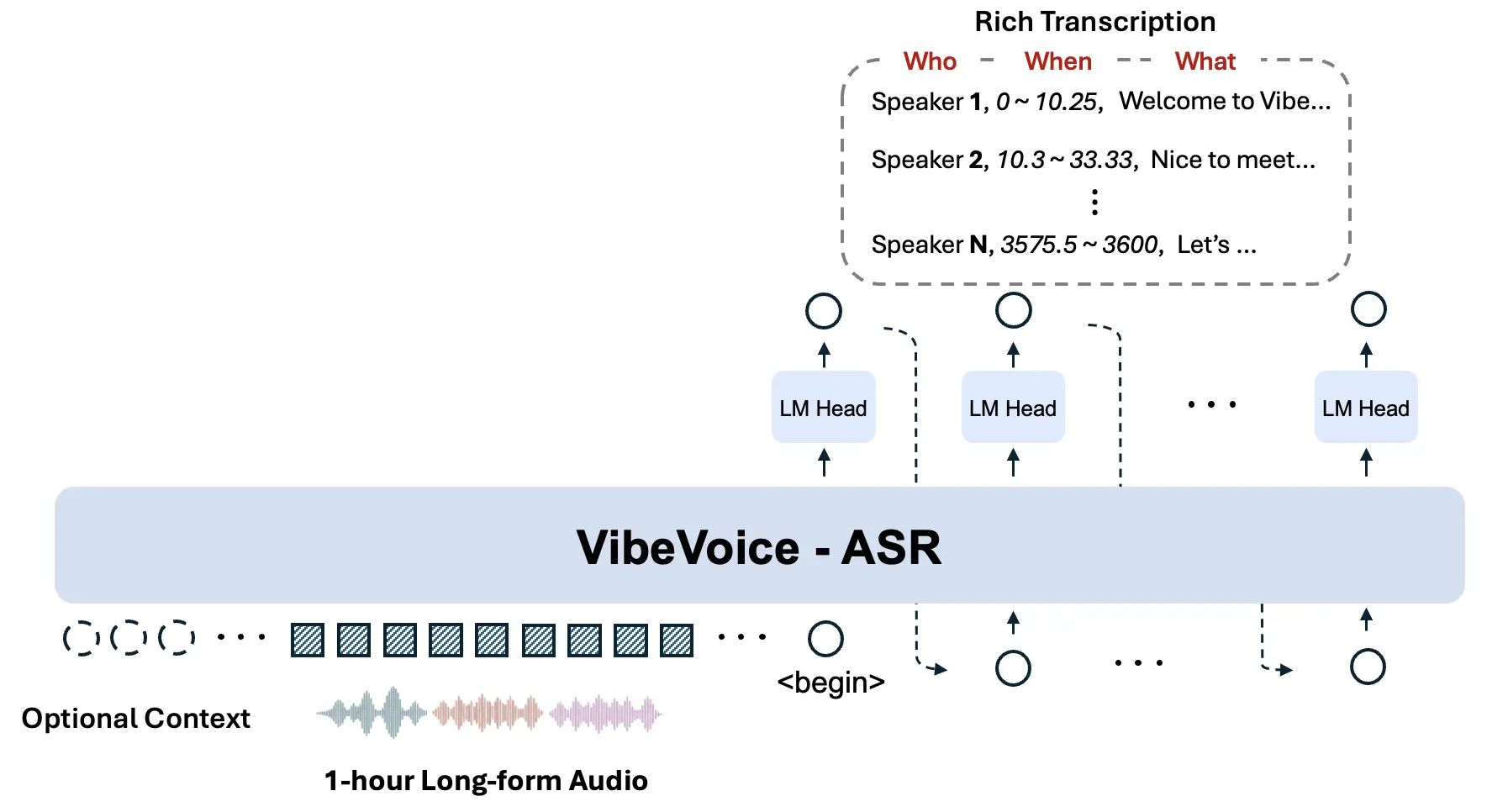
單次處理最長 60 分鐘音頻:與將音頻分割成短片段(通常會丟失全局上下文)的傳統 ASR 模型不同,VibeVoice ASR 可接受長達 60 分鐘的連續音頻輸入,每個音頻片段長度為 64K。這確保了整整一小時內説話人追蹤的一致性和語義連貫性。
-
自定義熱詞:用户可以提供自定義熱詞(例如,特定名稱、技術術語或背景信息)來指導識別過程,從而顯著提高特定領域內容的識別準確率。
-
豐富的轉錄(誰、何時、什麼):該模型聯合執行 ASR、人聲分割和時間戳功能,生成結構化的輸出:「誰 在 何時 説了什麼」。
模型整體架構如下:
開源地址
https://huggingface.co/microsoft/VibeVoice-ASR
https://github.com/microsoft/VibeVoice
