東北大學“小牛翻譯”團隊近日正式開源其最新大模型——NiuTrans.LMT(Large-scale Multilingual Translation),一舉實現60種語言、234個翻譯方向的全覆蓋,不僅以中文與英文為雙核心構建全球語言橋樑,更在藏語、阿姆哈拉語等29種低資源語言上取得顯著突破。
區別於多數以英語為唯一樞紐的翻譯模型,NiuTrans.LMT採用中-英雙中心設計,支持中文↔58種語言、英文↔59種語言的高質量直譯,避免“中文→英文→小語種”的二次失真。
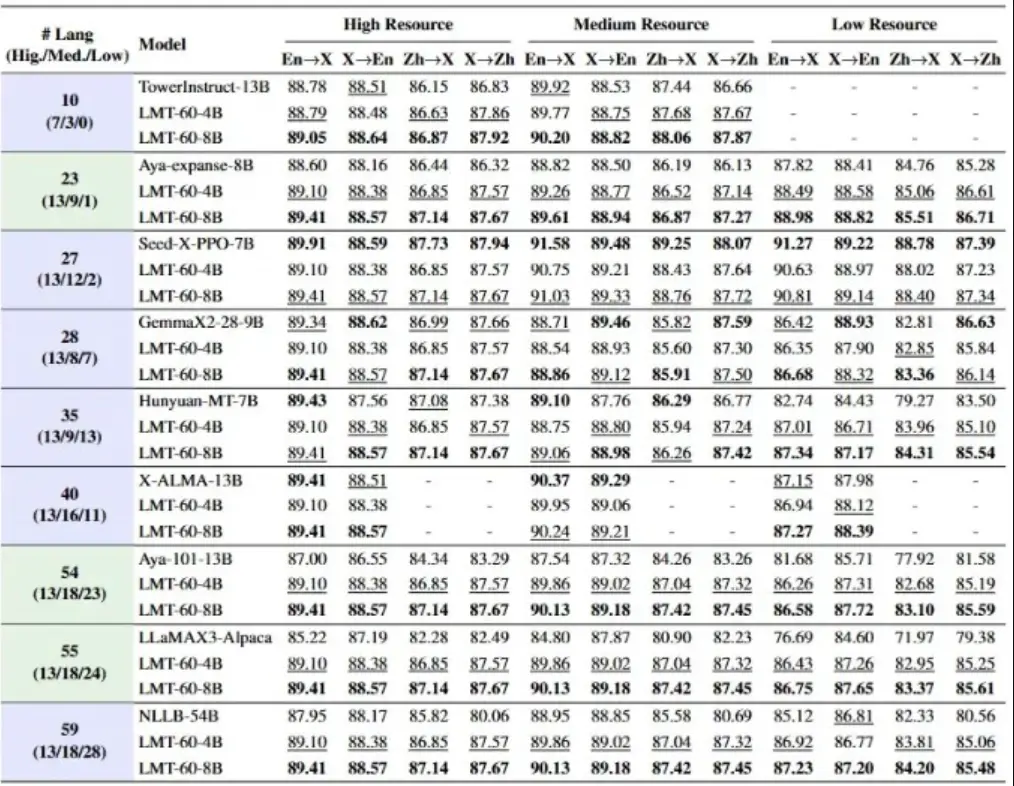
13種高資源語言(如法語、阿拉伯語、西班牙語):翻譯流暢度媲美人類;
18種中資源語言(如印地語、芬蘭語):在專業術語與語法結構上高度準確;
29種低資源語言(含藏語、斯瓦希里語、孟加拉語等):通過數據增強與遷移學習,實現從“不可譯”到“可用譯”的跨越。
NiuTrans.LMT 的兩階段訓練流程如下:
- 繼續預訓練(CPT):在900億tokens的多語言語料上均衡學習,確保小語種不被淹沒;
- 監督微調(SFT):整合FLORES-200、WMT等高質量平行語料(56.7萬條樣本,覆蓋117方向),精調翻譯準確性與風格一致性。
為滿足不同場景需求,團隊同步開源0.6B、1.7B、4B、8B四種參數規模模型,全部可在GitHub與Hugging Face免費下載。輕量版可在消費級GPU運行,適合移動端部署;8B版本則面向企業級高精度翻譯場景,支持API集成與私有化部署。
