作者:望宸
LangChain 近期發佈了《State of Agent Engineering》報告,內容比較翔實,全面分析了 AI 智能體在企業中的採用現狀、挑戰與趨勢。(或尚未應用的原因)
我們對報告進行了翻譯,並做了些描述和內容排序上的的優化,讓中文讀者更易於理解。同時,我們將今年 9 月底發佈的《AI 原生應用架構白皮書》中的部分調研數據,和《State of Agent Engineering》進行比對,以瞭解智能體工程現狀在國內外的差異,以及對共性問題提供了些應對思路。
報名與白皮書原文:
《State of Agent Engineering》
https://www.langchain.com/state-of-agent-engineering
《AI 原生應用架構白皮書》
https://developer.aliyun.com/ebook/8479
- 《State of Agent Engineering》人羣畫像:1340 份有效回覆,包括工程師、產品經理、業務負責人和企業高管。
- 《AI 原生應用架構白皮書》人羣畫像:來自參加杭州、上海、北京、深圳、廣州舉辦的 6 場 AI 原生為主題的線下開發者沙龍,填寫問卷的總人數是 1382 人,以架構師、後端、運維、技術負責人為主。
什麼是智能體工程?
智能體工程是將大語言模型(LLM)轉化為可靠系統的迭代過程。由於智能體具有不確定性,我們認為,工程師必須通過快速迭代來持續優化其輸出質量。
核心發現
企業的關注度不再問是否要構建智能體,而是關注如何可靠、高效且規模化地部署智能體,且這一趨勢會一直蔓延到 2026 年,直到能有效的解決問題。核心發現:
- 生產落地勢頭強勁:57% 的受訪者已將智能體投入生產環境,大型企業引領採納潮流。
- 質量是最大攔路虎:32% 的人將"質量"列為首要障礙;相比之下,成本擔憂較去年有所下降。
- 可觀測性已成為標配:近 89% 的受訪者為其智能體實施了可觀測性方案,遠超評估(evals)的採用率(52%)。
- 多模型策略成常態:OpenAI 的 GPT 系列模型佔據主導,但 Gemini、Claude 和開源模型也獲得廣泛應用;微調尚未普及。
大型企業引領採納浪潮
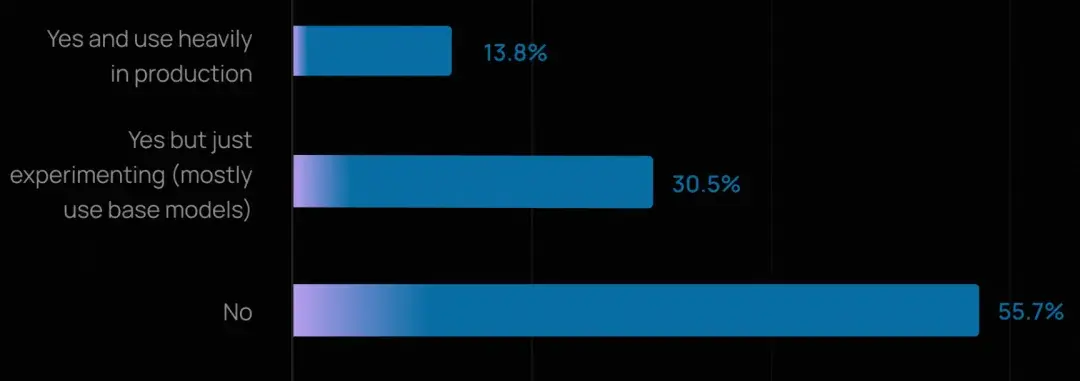
超過半數(57.3%)的受訪者表示其公司已在生產環境中運行智能體,另有 30.4% 正在積極開發並有明確的上線計劃。
這標誌着相較於去年(51% 的受訪者稱已有智能體上線),有了顯著增長。企業正從概念驗證階段邁向生產部署。
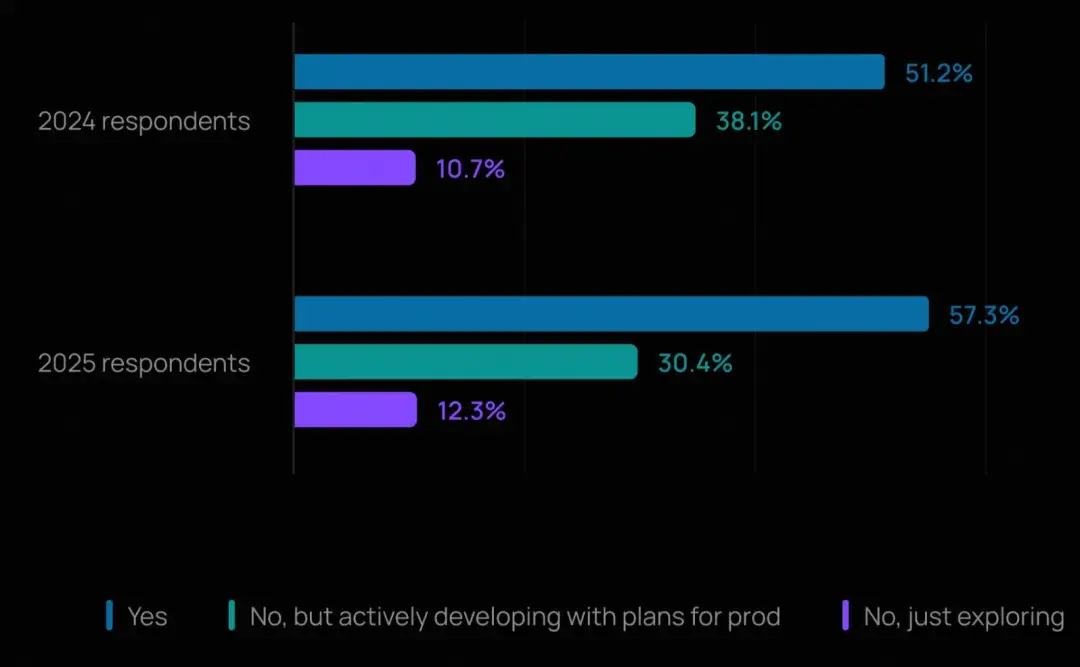
《AI 原生應用架構白皮書》中關於實施進程的調研結果,國內外的智能體發展勢頭均比較強勢,企業關注的不再是"是否"要推出智能體,而是"如何"以及"何時"。

規模效應顯現
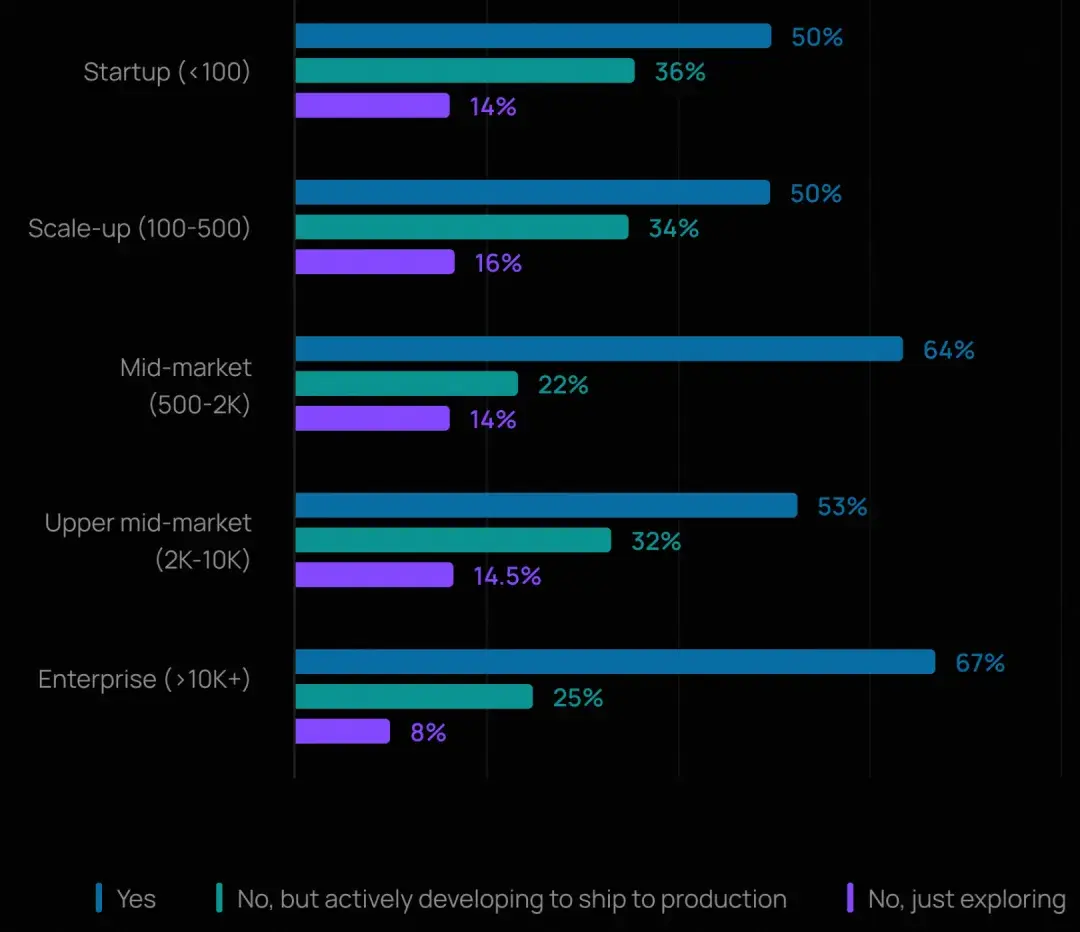
在員工規模超 10,000 人的大型組織中,67% 已部署智能體,24% 正在開發中;而在員工少於 100 人的小型組織中,這一比例分別為 50% 和 36%。這表明大型企業正更快地從試點走向可持續演進,可能得益於其在平台團隊、安全性和可靠性基礎設施上,有着更大的投入。
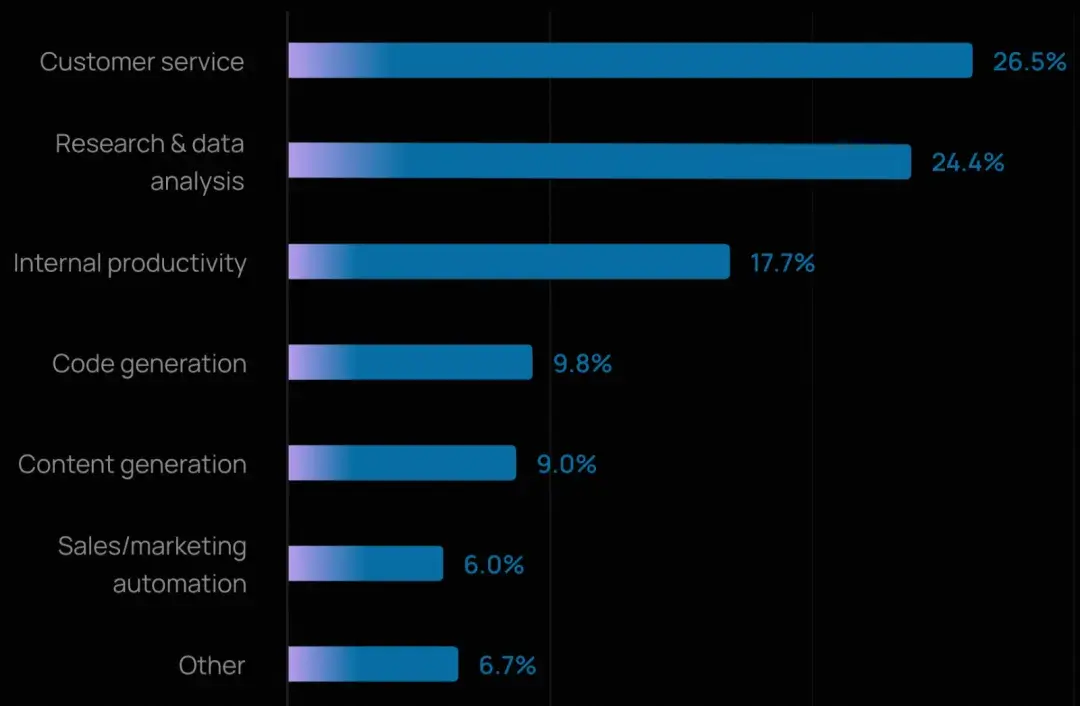
主流智能體應用場景
客户服務是最常見的智能體用例(26.5%),緊隨其後的是研究與數據分析(24.4%)。這兩類應用合計佔所有主要部署場景的一半以上。
這一結果表明:
- 企業正越來越多地將智能體直接面向客户,而不僅限於內部使用。同時,智能體在提升內部效率方面也表現出顯著的價值,18% 的受訪者提到將其用於內部工作流自動化。
- 研究與數據分析場景的流行,進一步印證了智能體當前的優勢所在,即整合海量信息、跨源推理,並加速知識密集型任務。
- 今年的受訪者選擇的應用場景更加分散(每人僅可選一項主要用例),説明智能體的應用正在從早期少數場景向更廣泛的領域拓展。
- 大企業的偏好略有不同,在萬人以上企業中,內部生產力提升成為首要用例(26.8%),客户服務(24.7%)和研究與數據分析(22.2%)緊隨其後。這表明大型企業可能優先聚焦於提升內部團隊效率,再逐步或同步向終端用户部署。
《AI 原生應用架構白皮書》提供了以下 4 類落地場景供多選,重塑客户互動 > 重塑業務流程 > 提升員工體驗 > 推動創新突破。結合兩份數據,客户服務和企業內提效是智能體最確定的應用場景。

投產的最大障礙:質量、延遲與安全
- 質量仍是頭號難題,與去年一致。 今年有三分之一的受訪者將其列為最大障礙。這裏的"質量"涵蓋準確性、相關性、一致性,以及智能體能否保持恰當語氣並遵守品牌或政策規範。
- 延遲成為第二大挑戰(20%)。 隨着智能體進入客户服務、代碼生成等面向客户的場景,響應速度已成為用户體驗的關鍵。這也反映了團隊在質量與速度之間的權衡:能力更強、步驟更多的智能體雖能產出更高質量結果,但響應往往更慢。
- 成本作為擔憂因素的提及率低於往年。 模型價格下降和效率提升似乎已將組織的關注點從"花費多少"轉向"如何讓智能體又快又好"。
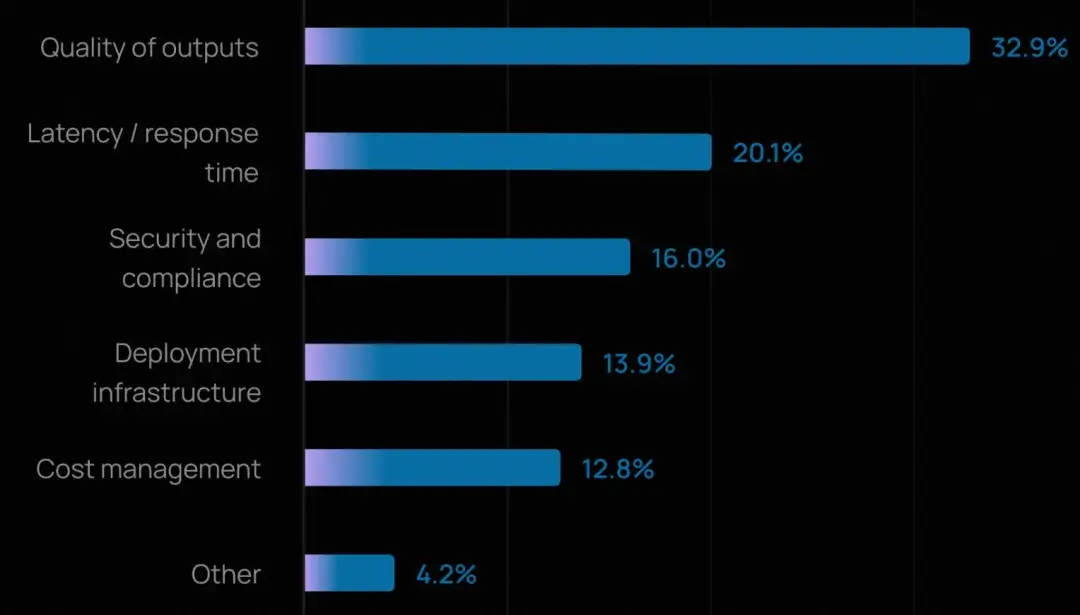
《AI 原生應用架構白皮書》側重於技術層面的挑戰進行調研:長回話狀態管理 > 算力資源調度 > 數據梳理鏈路 > 異步通信需求,和質量、延遲、成本有所呼應。

規模帶來的新挑戰:
- 在 2,000 人以上的大型企業中,安全躍升為第二大障礙(24.9%),超過了延遲。這反映出大型組織對數據合規、權限控制和審計追蹤的更高要求。
- 在萬人以上企業中,開放式回答指出,幻覺和輸出一致性是確保智能體質量的最大挑戰。許多人還提到,在大規模場景下進行上下文工程和管理上下文仍十分困難。
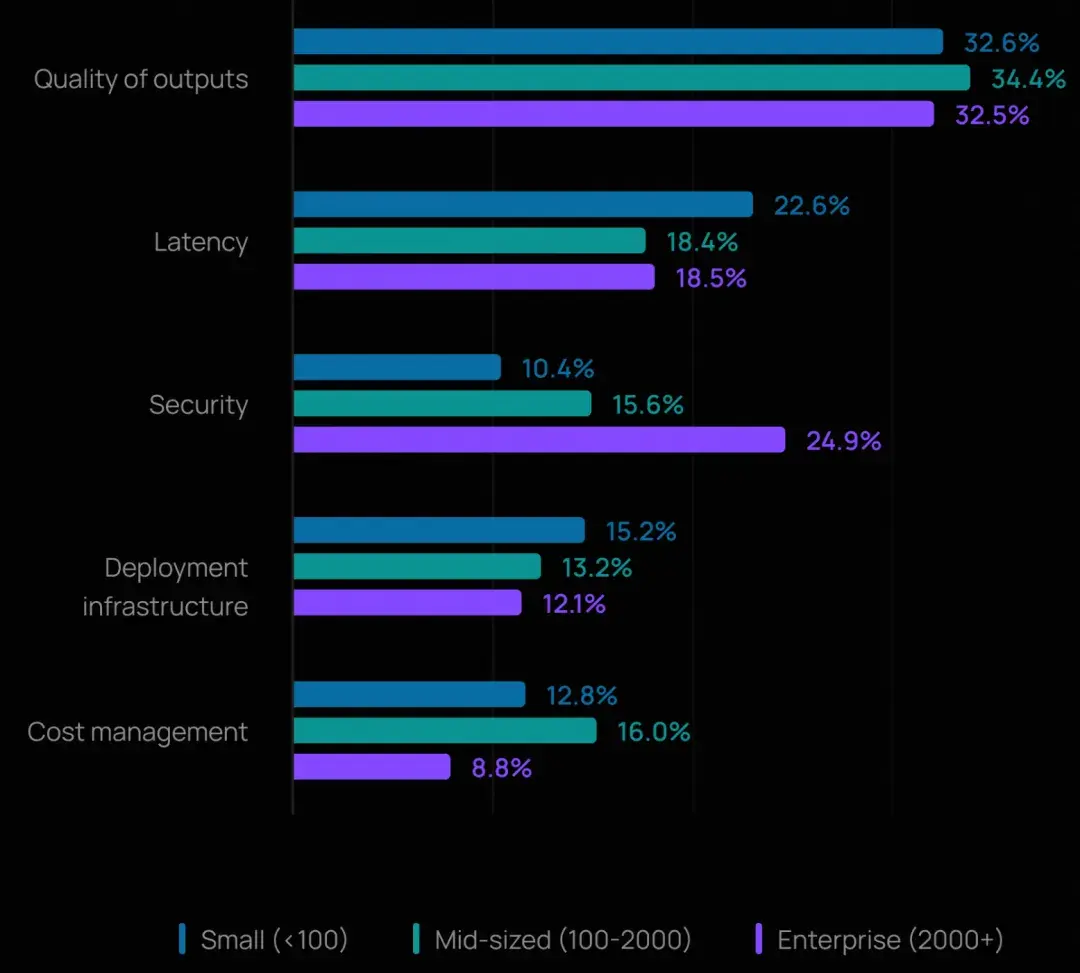
《AI 原生應用架構白皮書》中提供了上下文工程和 AI 安全的一些初步探索。其中,上下文工程是技術難點,安全則依賴組織的體系化設計。


智能體可觀測性:已成為行業標配
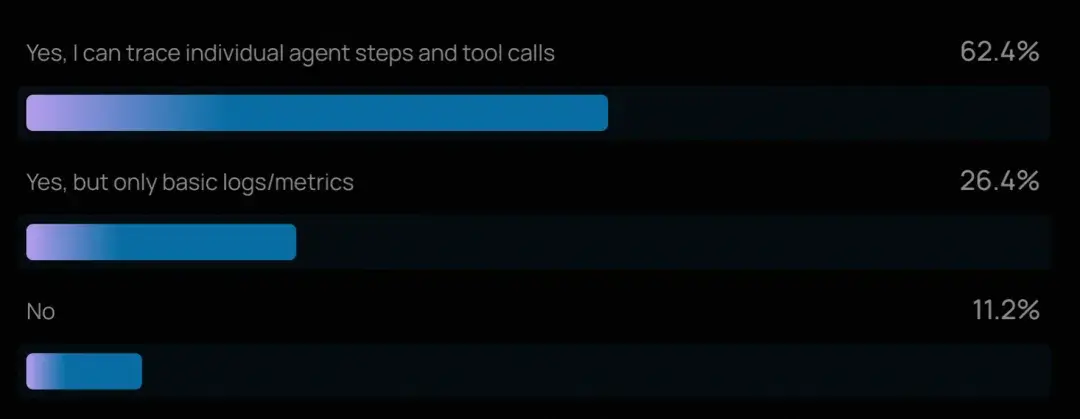
- 對多步推理鏈和工具調用進行追蹤的能力,如今已是智能體工程的"基本要求"。89% 的組織已為其智能體實施了某種形式的可觀測性,其中 62% 具備詳細追蹤能力,可檢查智能體的每一步操作和工具調用。
- 在已上線智能體的團隊中,這一比例更高,94% 擁有某種可觀測性,71.5% 具備完整追蹤能力。這揭示了一個基本事實:若無法看清智能體如何推理和行動,團隊就無法可靠地調試故障、優化性能,也無法贏得內外部利益相關者的信任。
《AI 原生應用架構白皮書》:調研了可觀測的主流應用場景。

同時,《AI 原生應用架構白皮書》提供了相關的理論和實踐。解決以上痛點的關鍵能力是:端到端的全鏈路跟蹤、全棧觀測、自動化評估。

智能體評估與測試:仍在追趕
- 儘管可觀測性已廣泛普及,但智能體評估(evals)的採用仍在追趕中。略超一半的組織(52.4%)報告會在測試集上運行離線評估,表明許多團隊已意識到在部署前捕捉迴歸和驗證行為的重要性。
- 在線評估(online evals)的採用率較低(37.3%),但正在快速增長,因為團隊開始監控智能體在真實世界中的表現。
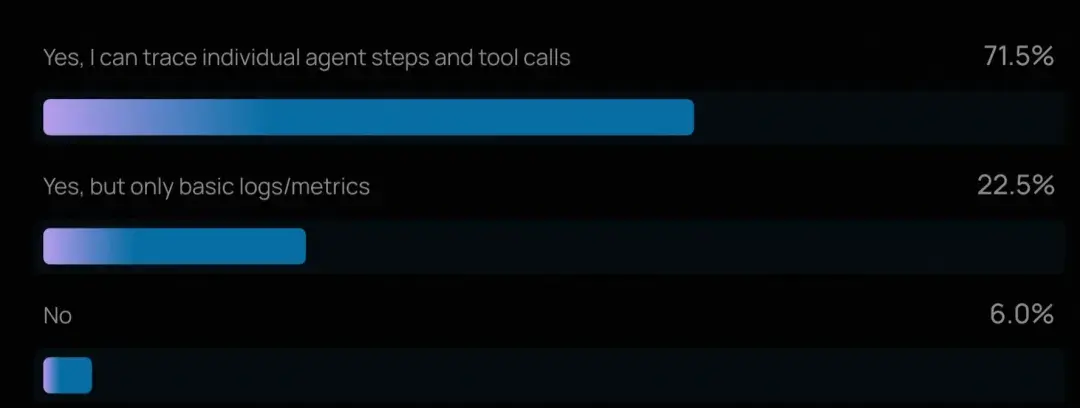
- 對於已上線智能體的團隊,評估實踐明顯更成熟:"不評估"的比例從 29.5% 降至 22.8%,而進行在線評估的比例升至 44.8%。這表明一旦智能體面對真實用户,團隊就必須依賴生產數據實時發現問題。
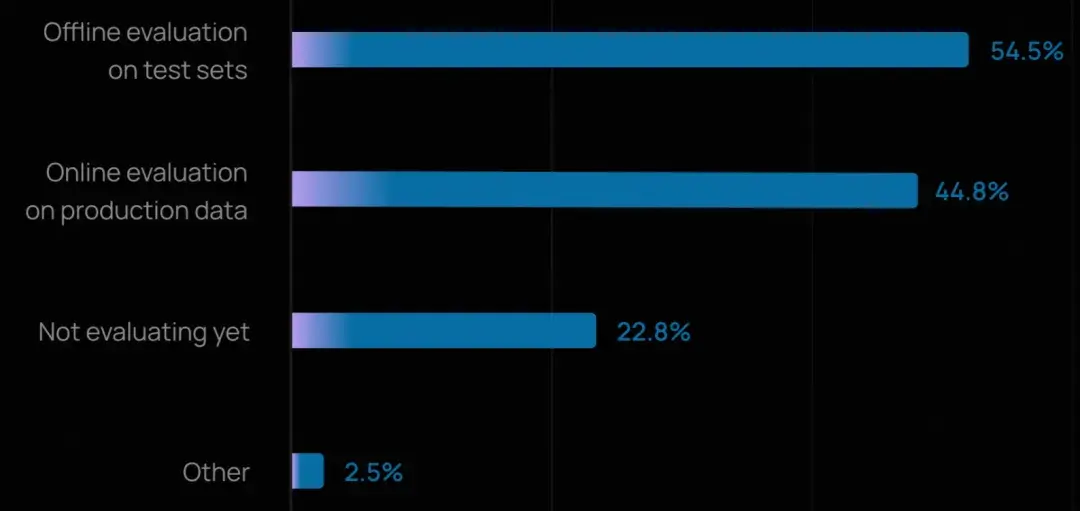
- 大多數團隊仍從離線評估入手(因其門檻較低、設置更清晰),但許多正在疊加多種方法。在開展評估的組織中,近四分之一同時使用離線和在線評估。
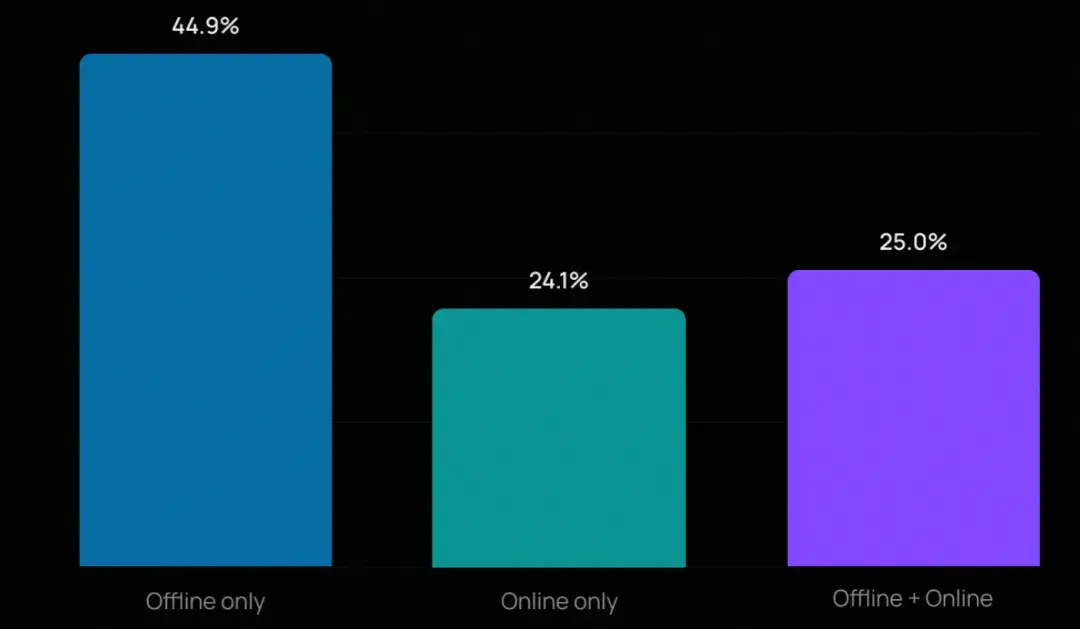
這些團隊通常結合人工評審與自動化方法:用 LLM-as-Judge 實現廣度覆蓋,用人工審核處理深度判斷。
- 總體而言,人工評審(59.8%)在高風險或需細膩判斷的場景中仍不可或缺,而 LLM-as-Judge(53.3%)則被越來越多地用於規模化評估質量、事實準確性和合規性。
- 相比之下,傳統的機器學習指標(如 ROUGE、BLEU)採用率很低,在開放式智能體交互中,往往存在多個有效答案,這些指標並不適用。
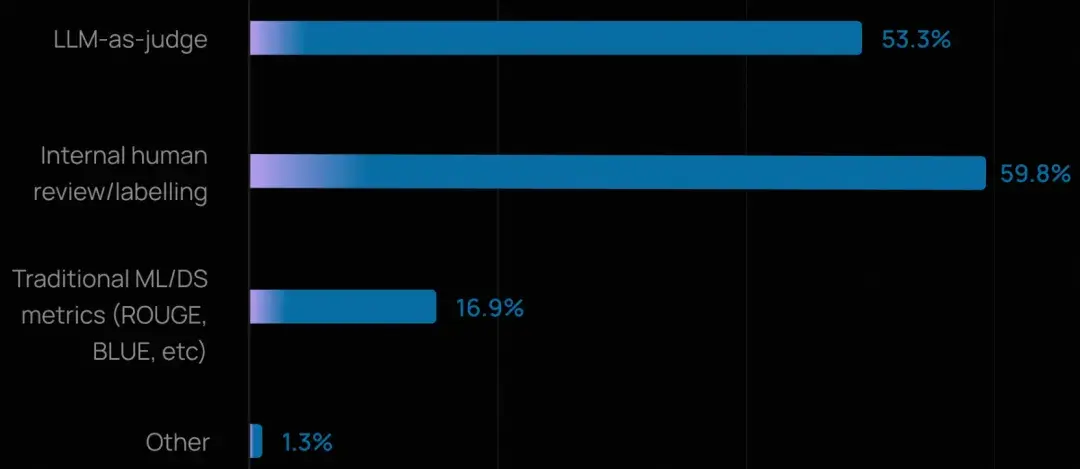
《AI 原生應用架構白皮書》也認為傳統的機器學習指標(如 ROUGE、BLEU),存在較高的侷限性。

更流行的是 LLM-as-Judge 範式,並提供了利用在線數據,實現自動化評估的實踐框架。

模型與工具生態:開放、多元、務實
- OpenAI 模型佔據主導,但很少有團隊押注單一供應商。超過三分之二的組織使用 OpenAI 的 GPT 系列模型,但超過四分之三(75%+)在生產或開發中使用多個模型。
- 團隊越來越傾向於根據任務複雜度、成本和延遲等因素,將不同任務路由給不同模型,而非陷入平台鎖定。
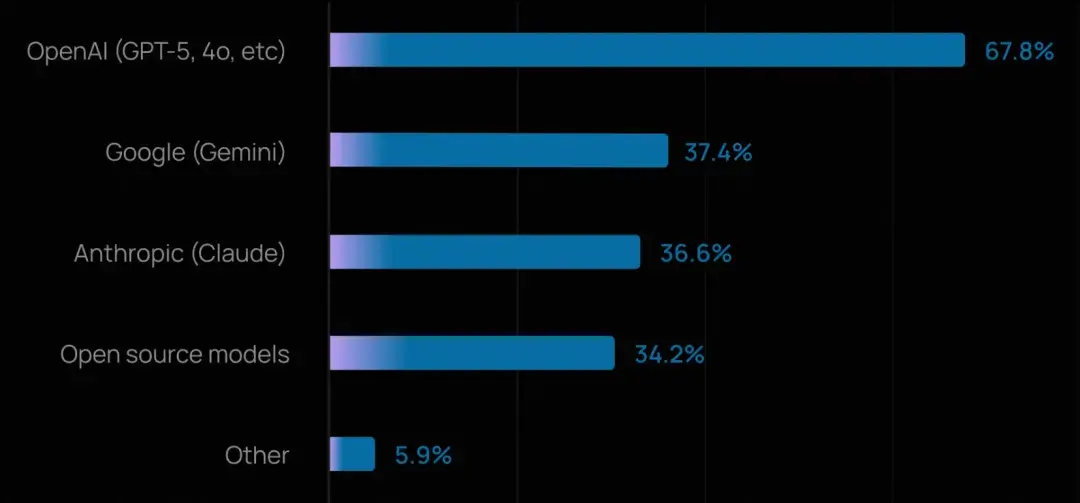
《AI 原生應用架構白皮書》中提到多模型策略是常態,通過 AI 網關可以高效、安全、量化管理模型供應和 Token 的消耗。
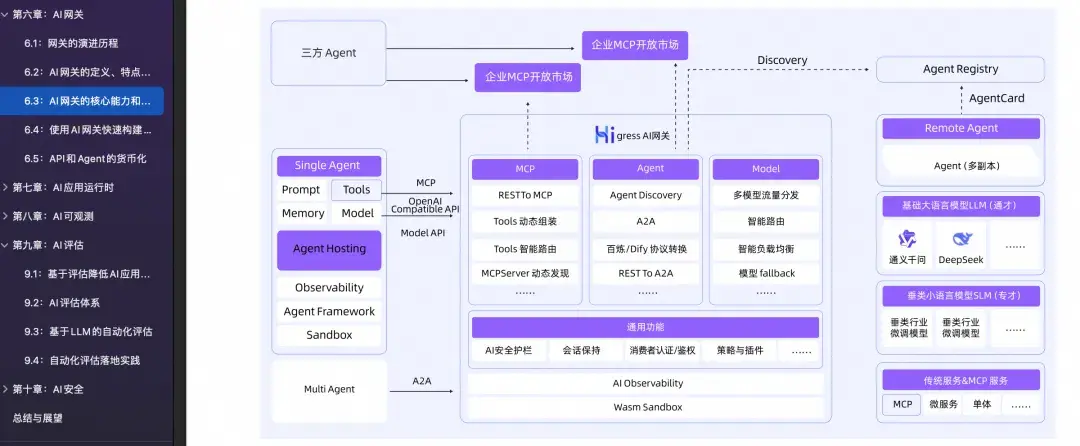
- 儘管商業 API 使用便捷,但自託管模型仍是重要策略。 約三分之一的組織投入資源建設自有基礎設施以部署開源模型。這可能是出於高用量下的成本優化、數據駐留/主權要求,或特定行業的監管約束。
- 同時,微調仍未普及。 57% 的組織未進行任何微調,而是依賴基礎模型結合提示工程和檢索增強生成。由於微調需要大量投入(數據收集、標註、訓練基礎設施和持續維護),目前主要用於高影響力或高度專業化的場景。