螞蟻 ASystem 團隊宣佈開源其強化學習系統的關鍵組件:AMem NCCL-Plugin,用於解決 RL 訓練中的顯存瓶頸和通信連接的耗時難題,以實現高性能計算。
NCCL 是 NVIDIA Collective Communications Library(英偉達集合通信庫)的縮寫,它是多 GPU 和多節點分佈式深度學習的核心通信庫,提供了包括 AllReduce、AlltoAll 等多種高效集體通信操作。
據介紹,AMem NCCL-Plugin 是螞蟻 ASystem 團隊自研的 NCCL 功能擴展庫,主要提供了 ncclPause() 和 ncclResume() 兩個顯存管理 API,旨在解決 RL 流程中,通信庫 NCCL 分配的顯存無法被高效卸載的這一難題。
通過輕量級插件方式,在保留 NCCL 通信連接的情況下,實現對訓推引擎 NCCL 顯存的透明卸載(offload)與恢復(reload)注1,這些優勢特點已在 Ring-1T 萬億參數推理模型的強化學習訓練中得到了驗證。
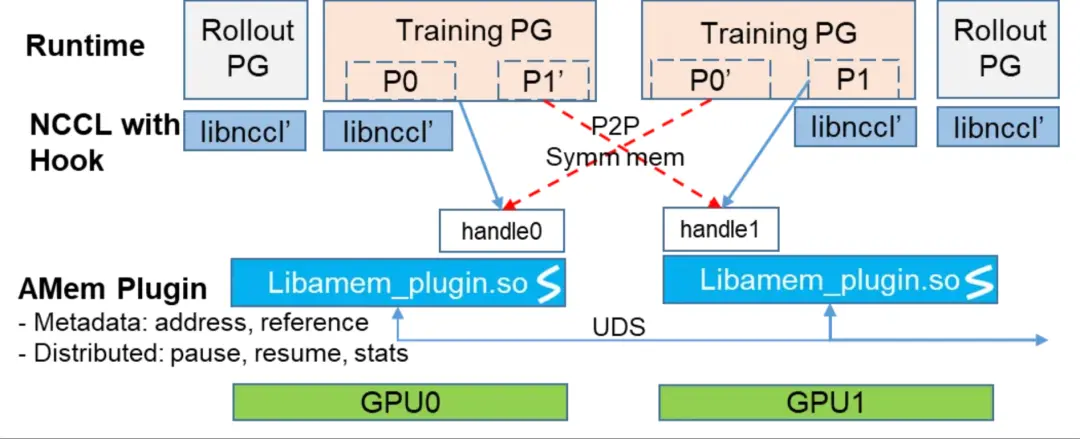
AMem NCCL-plugin總體架構圖
AMem NCCL-Plugin 的優勢體現在如下兩個方面:
-
顯存節約:通過識別並解決 NCCL 通信庫中 cross-rank 的顯存交叉引用問題,實現正確的顯存透明釋放與恢復。在訓推切換時,可在保持通信組連接的情況下,單卡(Hopper 架構卡)釋放出 10GB+ 顯存;
-
極致高效:因為保留了通信組的連接,訓推轉換僅卸載和恢復 NCCL 的元數據,無需重建通信連接(典型耗時為數秒鐘),從而實現典型耗時 <1 秒的極致優化。
與社區已知方案的在 Hopper 架構卡上的能力對比:
|
組件 |
方案 |
內存節省情況 |
每step卸載恢復耗時 |
|
Slime注2 |
通過銷燬和重建訓練引擎通信組清理 NCCL 顯存 |
推理不節省:殘留 2GB 訓練節省 10GB+ |
數秒 |
|
OpenRLHF |
不支持卸載 NCCL 顯存 |
推理不節省:殘留 2GB 訓練不節省:殘留 10GB+ |
0s |
|
AMem |
通過 Plugin 卸載 NCCL 顯存 |
推理節省 2GB 訓練節省 10GB+ |
<1s |
AMem NCCL-plugin 功能對比
注 1: 顯存釋放:把顯存交還操作系統;顯存卸載:把顯存中的信息放入CPU pinned buffer, 然後釋放顯存;顯存恢復:把顯存重新分配回來,把暫存 CPU pinned buffer 的信息拷貝回顯存中。
注 2: slime 介紹, Slime V0.1.0. https://zhuanlan.zhihu.com/p/1945237948166547268
代碼地址:https://github.com/inclusionAI/asystem-amem
