
導讀:
StarRocks 4.0 已正式發佈!這一版本將優化能力從查詢層延伸至數據層,通過全新的 Global Shuffle Ingestion、Spill-Aware Writes、Compaction API 與 Local Sort 等特性,讓數據在寫入的同時即完成優化。面對 Apache Iceberg 等開放格式中"小文件過多、查詢延遲高"的挑戰,StarRocks 4.0 將數據倉庫級的治理理念引入 Lakehouse 架構,實現了從寫入、組織到維護的全鏈路提速。
本文將帶你瞭解這些關鍵機制如何讓 Lakehouse 變得真正 Query-Ready。
在 Apache Iceberg 表中,數據的寫入方式往往並未針對查詢性能進行優化。持續不斷的微批寫入會產生成千上萬個小文件;也很難做到讓數據在寫入後的第一時間就能被快速查詢。
結果是:查詢變慢、資源佔用激增,成本也隨之持續攀升。
為什麼僅靠查詢優化無法解決性能問題
查詢優化可以不斷地進行剪枝、緩存和向量化處理------但再聰明的優化器,也無法扭轉"小文件風暴"帶來的性能損耗。在實際使用中,性能不穩定往往源於以下幾個原因:
-
在分佈式、併發、多分區寫入過程中,小文件迅速倍增;
-
數據寫入時未經過排序,削弱了剪枝與 I/O 合併效果;
傳統的事後合併雖有助於緩解問題,但過程複雜、觸發不及時,常常錯過數據剛剛寫入的關鍵窗口。
讓數據湖具備數據倉庫級的治理能力
在傳統數據倉庫中,幾乎不會出現"小文件過多"或性能波動的問題。因為數據在寫入存儲前,通常已經經過合併和排序等優化處理;同時,後台還會有輕量級服務持續維護系統的穩定與高效。
我們將這一理念引入 Apache Iceberg,構建了兩層優化機制。
1. Ingestion-first(寫入優先)
在數據寫入前,系統會智能路由以避免寫入衝突;在落盤前,數據經過緩衝與合併,最終以更大、更整潔的文件寫入存儲。這意味着------數據一旦落地,即可被查詢,無需等待漫長的合併或維護任務。
2. Compaction service
後台服務持續運行,不斷將小文件合併為適合查詢的文件,並保持分區均衡。服務具有限流、跳過熱點、即時可用等機制,能夠在需要時快速完成數據整理。
藉助這兩層機制,Iceberg 表的運行特性更接近數據倉庫表:
-
高負載下寫入依然穩定;
-
新寫入的數據可立即查詢;
-
後台合併優化,確保查詢性能始終如一。
StarRocks 如何讓這一理念落地
StarRocks 是一款為 Apache Iceberg 等開放格式而生的高性能 SQL 引擎,專注於低延時與高併發查詢。
無論是實時數據看板,還是大規模的用户側分析場景,StarRocks 都能以強大的查詢性能為支撐,讓"速度"成為用户體驗的核心競爭力。
StarRocks 4.0 新特性
在 4.0 版本中,StarRocks 的優化不再侷限於查詢執行層,而是進一步下沉到數據層------從寫入、組織到維護,實現全鏈路優化。
全局 Shuffle 寫入機制
全新的 Global Shuffle Ingestion 機制能夠在集羣節點間智能分配數據寫入,避免後端之間的衝突。每個節點只負責部分分區,從而生成更少但更大的文件,避免"小文件"氾濫。這一機制顯著降低了元數據開銷,並在高分區場景下大幅提升查詢掃描效率。
感知溢出的寫入機制(Spill-Aware Writes)
在內存壓力增大時,StarRocks 不再被動提前刷寫數據,而是儘可能將數據緩存在內存中,並在需要時自動將其溢寫到磁盤或對象存儲。
這一機制避免了因防止 OOM 而過早生成小文件的問題,使數據文件更接近理想大小,即使在上千分區的複雜寫入場景下,仍能保持穩定、高效的性能表現。
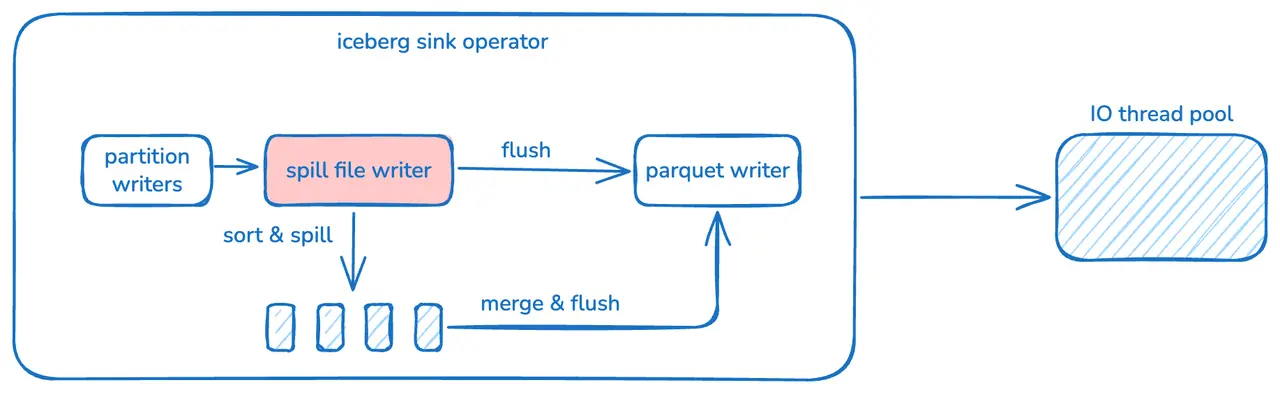
Compaction API
在需要進行數據維護時------例如經歷大量微批寫入之後------StarRocks 4.0 引入了全新的 Compaction API。
它複用了寫入階段的同一套 Shuffle、Spill 與 Sort 邏輯,可按需快速完成文件合併。
藉助這一機制,用户無需藉助外部工具,即可直接在 StarRocks 內完成數據佈局的修復與優化。
本地排序
在文件層面,StarRocks 現已支持在寫入階段完成數據排序。每個文件內部保持有序,更便於剪枝優化,無需額外的排序任務即可顯著降低查詢延時。
數據在寫入的同時即完成優化,可直接支撐快速、穩定、可預測的查詢體驗。
Benchmarks
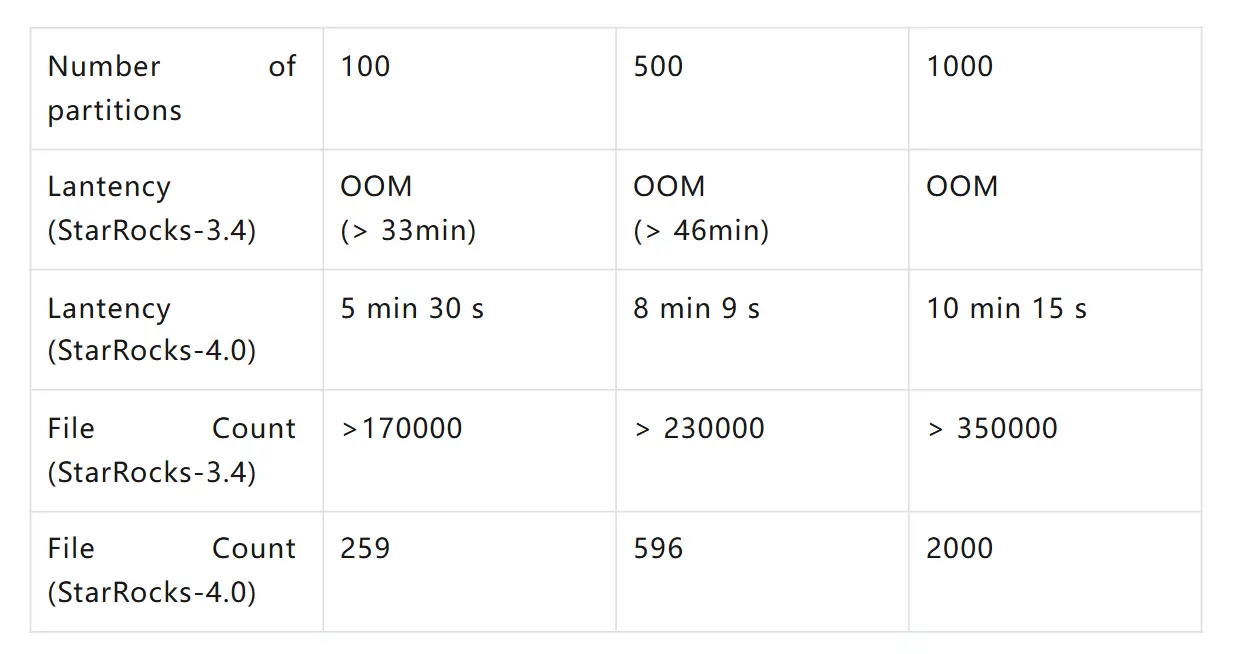
我們針對 Apache Iceberg 表進行了多組寫入測試,對比 StarRocks 4.0 與 3.4 版本在不同負載下的表現。
測試涵蓋 100、500 和 1000 個分區的典型場景,指標包括寫入延時、文件數量與平均文件大小。
主要結果如下:
-
大規模寫入穩定性顯著提升:舊版本在超過 100 個分區時常出現 OOM 錯誤;而 4.0 版本可穩定支持多達 1000 個分區的寫入,無任何失敗。
-
寫入延時大幅降低:在 100 分區下,寫入時間縮短一半以上;在 500 分區下,延時減少約 75%,端到端數據新鮮度顯著提升。
-
文件數量驟減:新的寫入路徑生成的文件更少、體量更大。在 100 分區測試中,文件數從 17 萬餘個降至僅 259 個;在 500 分區下,則從 23 萬多個降至 596 個。
A Query-Ready Lakehouse
Apache Iceberg 為現代 Lakehouse 架構帶來了開放性與治理能力,但要實現高性能,僅有開放格式還不夠------還需要像數據倉庫那樣,對底層文件進行有序的管理與優化。
在 StarRocks 4.0 中,這種"倉庫級的嚴謹"已被融入系統內核:
數據落地即具備可查詢狀態,寫入過程穩定高效,合併維護可按需即時完成。
由此,StarRocks 讓 Lakehouse 兼具數據倉庫的速度與可預測性,同時保留開放架構的靈活與自由。
