Qwen3-TTS家族新推出兩款模型,音色創造模型Qwen3-TTS-VD-Flash(可通過Qwen API訪問)和音色克隆模型Qwen3-TTS-VC-Flash(可通過Qwen API訪問)。
主要特點:
-
音色創造:Qwen3-TTS-VD-Flash 支持複雜自然語言指令輸入,實現對音色、韻律、情感、人設等的精細化調控,實現從“説什麼”到“如何説”的全面掌控,可以讓用户自由的定義想要的音色,徹底擺脱只能進行根據已有的音色進行克隆或者只能選擇固定的一部分預設音色。在 InstructTTS-Eval 中綜合表現顯著優於 GPT-4o-mini-tts、Mimo-audio-7b-instruct,在角色扮演測試中也超越 Gemini-2.5-pro-preview-tts。
-
音色克隆:Qwen3-TTS-VC-Flash 支持3s級別音色克隆,並且可以基於克隆的音色生成中文、英文、德語、意大利語、葡萄牙語、西班牙語、日語、韓語、法語、俄語等10大主流語言。在MiniMax TTS Multilingual Test Set上,平均詞錯誤率(WER)全面優於MiniMax、ElevenLabs及GPT-4o-Audio-Preview。
-
高表現力:Qwen3-TTS-VD-Flash 和 Qwen3-TTS-VC-Flash 具備高表現力的擬人化音色,能夠穩定、可靠地輸出高度契合輸入文本的語音內容,並根據文本語義自動調節語氣節奏,呈現自然生動的表達效果。
-
魯棒的文本能力:Qwen3-TTS-VD-Flash 和 Qwen3-TTS-VC-Flash 具備強大的文本解析能力,可自動處理複雜文本結構,精準提取關鍵信息,對多樣化、非規範化的文本格式展現出較強的魯棒性。
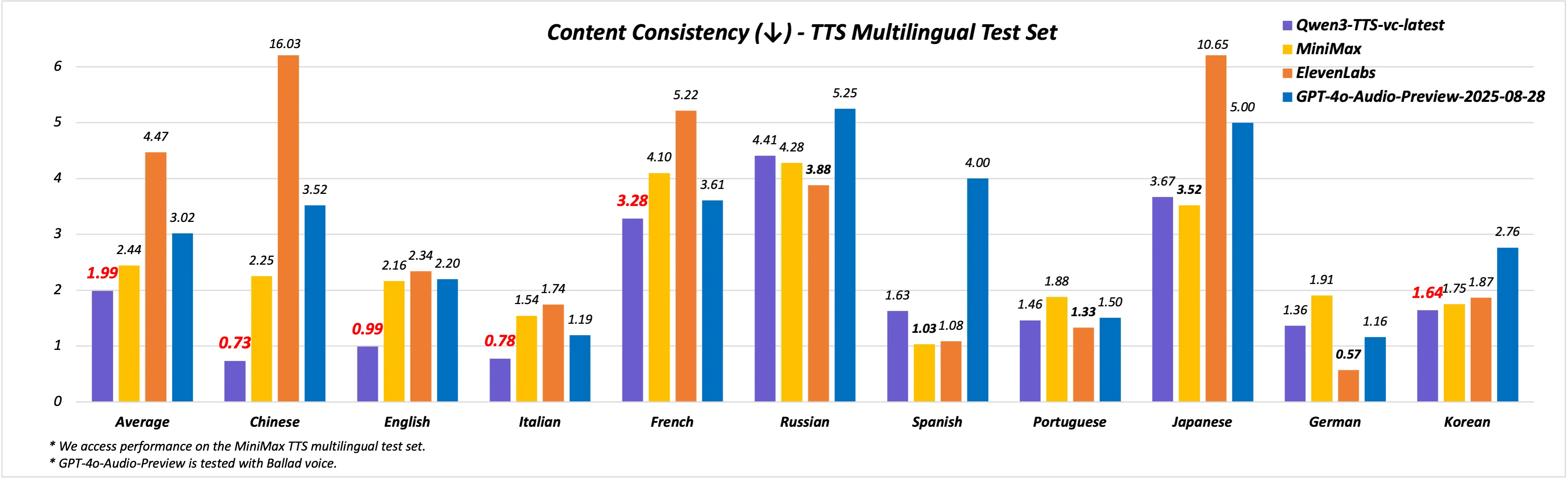
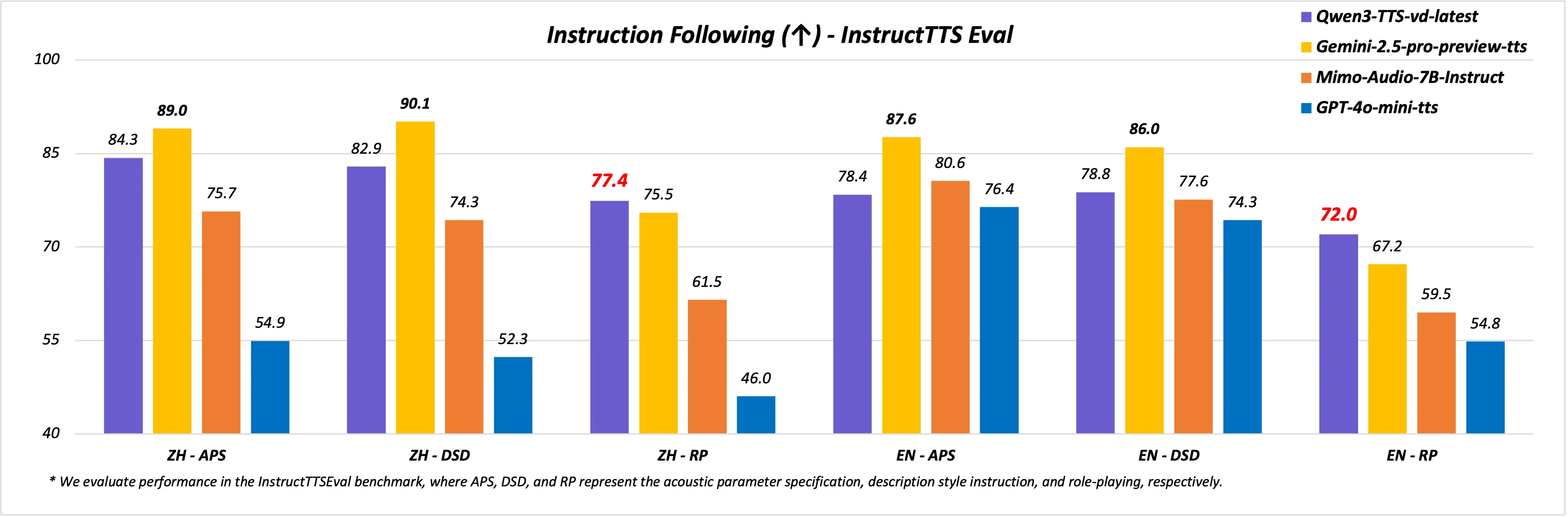
根據官方博客,Qwen3-TTS-VD-Flash模型支持通過自然語言指令自由設計聲音的音色、韻律和情感,不再依賴預設音庫。Qwen3-TTS-VC-Flash模型則能以極短音頻完成克隆,並支持中文、英文、日語等多種語言。兩款模型均已上線,用户可通過阿里雲百鍊平台 API 進行體驗。
