作者:柳遵飛(翼嚴)
前言
隨着 AI Agent 應用的快速發展,智能體需要處理越來越複雜的任務和更長的對話歷史。然而,LLM 的上下文窗口限制、不斷增長的 token 成本,以及如何讓 AI"記住"用户偏好和歷史交互,都成為了構建實用 AI Agent 系統面臨的核心挑戰。記憶系統(Memory System)正是為了解決這些問題而誕生的關鍵技術。
記憶系統使 AI Agent 能夠像人類一樣,在單次對話中保持上下文連貫性(短期記憶),同時能夠跨會話記住用户偏好、歷史交互和領域知識(長期記憶)。這不僅提升了用户體驗的連續性和個性化程度,也為構建更智能、更實用的 AI 應用奠定了基礎。
Memory 基礎概念
1.1 記憶的定義與分類
對於 AI Agent 而言,記憶至關重要,因為它使它們能夠記住之前的互動、從反饋中學習,並適應用户的偏好。
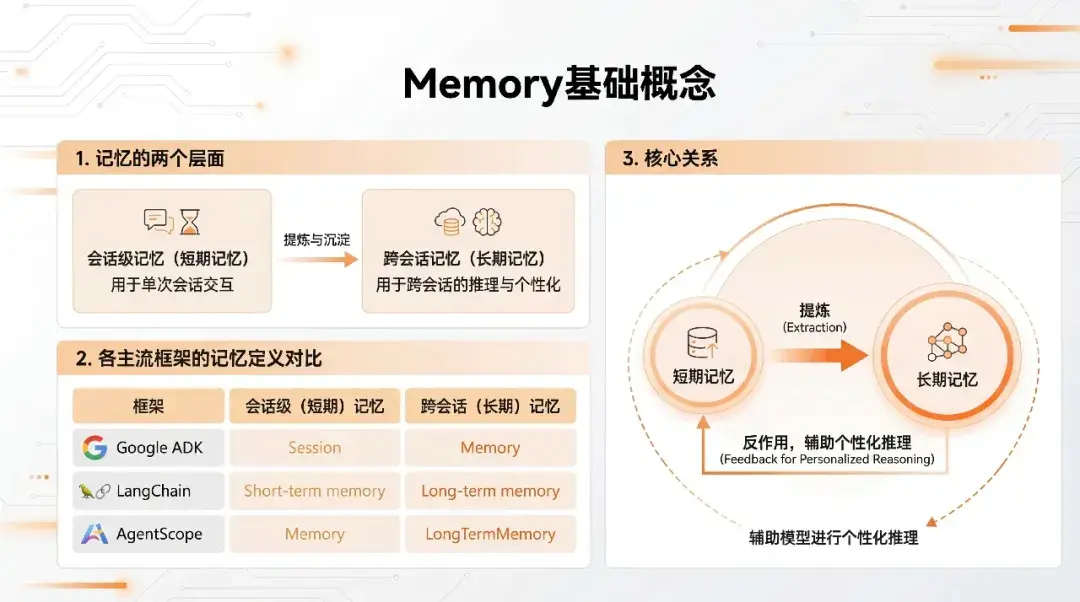
對"記憶"的定義有兩個層面:
- 會話級記憶: 用户和智能體 Agent 在一個會話中的多輪交互(user-query & response)
- 跨會話記憶: 從用户和智能體 Agent 的多個會話中抽取的通用信息,可以跨會話輔助 Agent 推理
1.2 各 Agent 框架的定義差異
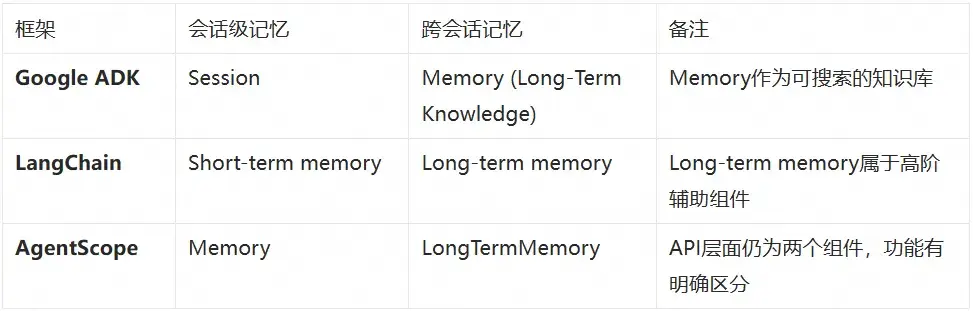
各個 Agent 框架對記憶的概念命名各有不同,但共同的是都遵循上一節中介紹的兩個不同層面的劃分:會話級和跨會話級。
框架説明:
- Google ADK: Session 表示單次持續交互;Memory 是長期知識庫,可包含來自多次對話的信息
- LangChain: Short-term memory 用於單線程或對話中記住之前的交互;Long-term memory 不屬於基礎核心組件,而是高階的"個人知識庫"外掛
- AgentScope: 雖然官方文檔強調需求驅動,但 API 層面仍然是兩個組件(memory 和 long_term_memory),功能層面有明確區分
習慣上,可以將會話級別的歷史消息稱為短期記憶 ,把可以跨會話共享的信息稱為長期記憶,但本質上兩者並不是通過簡單的時間維度進行的劃分,從實踐層面上以是否跨 Session 會話來進行區分。長期記憶的信息從短期記憶中抽取提煉而來,根據短期記憶中的信息實時地更新迭代,而其信息又會參與到短期記憶中輔助模型進行個性化推理。
Agent 框架集成記憶系統的架構
各 Agent 框架在集成記憶系統時,雖然實現細節不同,但都遵循相似的架構模式。理解這些通用模式有助於更好地設計和實現記憶系統。
2.1 Agent 框架集成記憶的通用模式
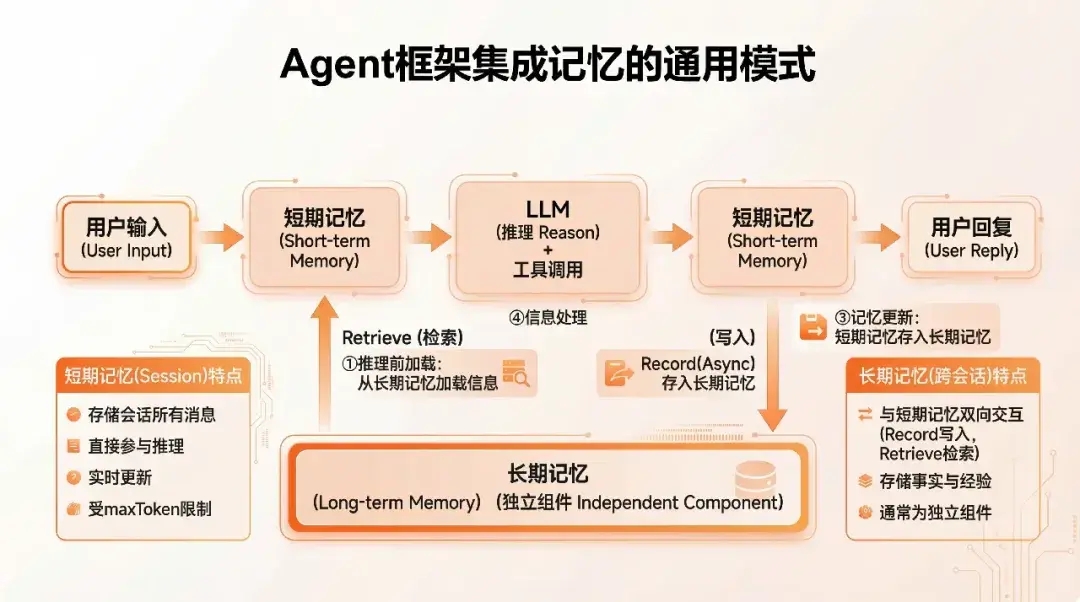
各 Agent 框架集成記憶系統通常遵循以下通用模式:
1. Step1:推理前加載 - 根據當前 user-query 從長期記憶中加載相關信息
2. Step2:上下文注入 - 從長期記憶中檢索的信息加入當前短期記憶中輔助模型推理
3. Step3:記憶更新 - 短期記憶在推理完成後加入到長期記憶中
4. Step4:信息處理 - 長期記憶模塊中結合 LLM+向量化模型進行信息提取和檢索
2.2 短期記憶(Session 會話)
短期記憶存儲會話中產生的各類消息,包括用户輸入、模型回覆、工具調用及其結果等。這些消息直接參與模型推理,實時更新,並受模型的 maxToken 限制。當消息累積導致上下文窗口超出限制時,需要通過上下文工程策略(壓縮、卸載、摘要等)進行處理,這也是上下文工程主要處理的部分。
核心特點:
- 存儲會話中的所有交互消息(用户輸入、模型回覆、工具調用等)
- 直接參與模型推理,作為 LLM 的輸入上下文
- 實時更新,每次交互都會新增消息
- 受模型 maxToken 限制,需要上下文工程策略進行優化
關於短期記憶的上下文工程策略(壓縮、卸載、摘要等),將在下一章節中詳細介紹。
2.3 長期記憶(跨會話)
長期記憶與短期記憶形成雙向交互:一方面,長期記憶從短期記憶中提取"事實"、"偏好"、"經驗"等有效信息進行存儲(Record);另一方面,長期記憶中的信息會被檢索並注入到短期記憶中,輔助模型進行個性化推理(Retrieve)。
與短期記憶的交互:
- Record(寫入): 從短期記憶的會話消息中提取有效信息,通過LLM進行語義理解和抽取,存儲到長期記憶中
- Retrieve(檢索): 根據當前用户查詢,從長期記憶中檢索相關信息,注入到短期記憶中作為上下文,輔助模型推理
實踐中的實現方式:
在 Agent 開發實踐中,長期記憶通常是一個獨立的第三方組件,因為其內部有相對比較複雜的流程(信息提取、向量化、存儲、檢索等)。常見的長期記憶組件包括 Mem0、Zep、Memos、ReMe 等,這些組件提供了完整的 Record 和 Retrieve 能力,Agent 框架通過 API 集成這些組件。
信息組織維度:
不同長期記憶產品在信息組織維度上有所差異:一些產品主要關注個人信息(個人記憶),而一些產品除了支持個人記憶外,還支持工具記憶、任務記憶等更豐富的維度。
-
用户維度(個人記憶): 面向用户維度組織的實時更新的個人知識庫
- 用户畫像分析報告
- 個性化推薦系統,千人千面
- 處理具體任務時加載至短期記憶中
-
業務領域維度: 沉澱的經驗(包括領域經驗和工具使用經驗)
- 可沉澱至領域知識庫
- 可通過強化學習微調沉澱至模型
短期記憶的上下文工程策略
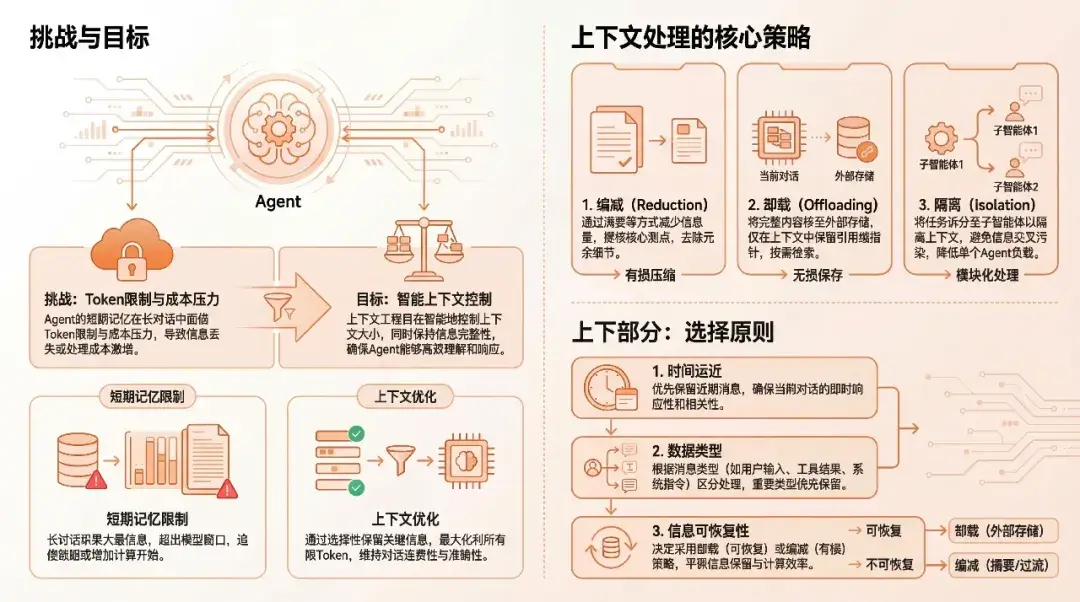
短期記憶直接參與 Agent 和 LLM 的交互,隨着對話歷史增長,上下文窗口會面臨 token 限制和成本壓力。上下文工程策略旨在通過智能化的壓縮、卸載和摘要技術,在保持信息完整性的同時,有效控制上下文大小。
備註: 需要説明的是,各方對上下文工程的概念和理解存在些許差異。狹義的上下文工程 特指對短期記憶(會話歷史)中各種壓縮、摘要、卸載等處理機制,主要解決上下文窗口限制和 token 成本問題;廣義的上下文工程則包括更廣泛的上下文優化策略,如非運行態的模型選擇、Prompt 優化工程、知識庫構建、工具集構建等,這些都是在模型推理前對上下文進行優化的手段,且這些因素都對模型推理結果有重要影響。本章節主要討論狹義的上下文工程,即針對短期記憶的運行時處理策略。
3.1 核心策略
針對短期記憶的上下文處理,主要有以下幾種策略:
上下文縮減(Context Reduction)
上下文縮減通過減少上下文中的信息量來降低 token 消耗,主要有兩種方法:
1. 保留預覽內容: 對於大塊內容,只保留前 N 個字符或關鍵片段作為預覽,原始完整內容被移除
2. 總結摘要: 使用 LLM 對整段內容進行總結摘要,保留關鍵信息,丟棄細節
這兩種方法都會導致信息丟失,但能有效減少 token 消耗。
上下文卸載(Context Offloading)
上下文卸載主要解決被縮減的內容是否可恢復的問題。當內容被縮減後,原始完整內容被卸載到外部存儲(如文件系統、數據庫等),消息中只保留最小必要的引用(如文件路徑、UUID 等)。當需要完整內容時,可以通過引用重新加載。
優勢:上下文更乾淨,佔用更小,信息不丟,隨取隨用。適用於網頁搜索結果、超長工具輸出、臨時計劃等佔 token 較多的內容。
上下文隔離(Context Isolation)
通過多智能體架構,將上下文拆分到不同的子智能體中(類似單體拆分稱多個微服務)。主智能體編寫任務指令,發送給子智能體,子智能體的整個上下文僅由該指令組成。子智能體完成任務後返回結果,主智能體不關心子智能體如何執行,只需要結果。
適用場景:任務有清晰簡短的指令,只有最終輸出才重要,如代碼庫中搜索特定片段。
優勢:上下文小、開銷低、簡單直接。
策略選擇原則:
以上三種策略(上下文縮減、上下文卸載、上下文隔離)需要根據數據的分類進行綜合處理,主要考慮因素包括:
- 時間遠近: 近期消息通常更重要,需要優先保留;歷史消息可以優先進行縮減或卸載
- 數據類型: 不同類型的消息(用户輸入、模型回覆、工具調用結果等)重要性不同,需要採用不同的處理策略
- 信息可恢復性: 對於需要完整信息的內容,應優先使用卸載策略;對於可以接受信息丟失的內容,可以使用縮減策略
3.2 各框架的實現方式
各框架一般內置上下文處理策略,通過參數化配置的方式指定具體策略。
Google ADK
構建 Agent 時通過 events_compaction_config 設置上下文處理策略,和 Session 本身的數據存儲獨立。
from google.adk.apps.app import App, EventsCompactionConfig
app = App(
name='my-agent',
root_agent=root_agent,
events_compaction_config=EventsCompactionConfig(
compaction_interval=3, # 每3次新調用觸發壓縮
overlap_size=1 # 包含前一個窗口的最後一次調用
),
)
LangChain
構建 Agent 時通過 middleware 機制中的 SummarizationMiddleware 設置上下文處理參數,與短期記憶本身的數據存儲獨立。
from langchain.agents import create_agent
from langchain.agents.middleware import SummarizationMiddleware
agent = create_agent(
model="gpt-4o",
tools=[...],
middleware=[
SummarizationMiddleware(
model="gpt-4o-mini",
max_tokens_before_summary=4000, # 4000 tokens時觸發摘要
messages_to_keep=20, # 摘要後保留最後20條消息
),
],
)
AgentScope
AgentScope 通過 AutoContextMemory 提供智能化的上下文工程解決方案。AutoContextMemory 實現了 Memory 接口,當對話歷史超過配置閾值時,自動應用 6 種漸進式壓縮策略(從輕量級到重量級)來減少上下文大小,同時保留重要信息。
集成方式:
- 直接作為
Memory接口實現,通過memory參數集成到 Agent 中 - 與框架深度集成,無需額外的 middleware 或獨立配置
與 ADK 和 LangChain 的差異:
- 更精細化的壓縮策略: 提供 6 種漸進式壓縮策略(壓縮歷史工具調用、卸載大型消息、摘要對話輪次等),相比 ADK 的簡單壓縮和 LangChain 的摘要 middleware,策略更加細化和可控
- 集成方式: 直接實現 Memory 接口,與 Agent 構建流程無縫集成,而 ADK 和 LangChain 需要獨立的配置對象或 middleware 機制
- 完整可追溯性: 提供工作內存、原始內存、卸載上下文和壓縮事件四層存儲架構,支持完整歷史追溯,而其他框架通常只提供壓縮後的結果
使用示例:
AutoContextMemory memory = new AutoContextMemory(
AutoContextConfig.builder()
.msgThreshold(100)
.maxToken(128 * 1024)
.tokenRatio(0.75)
.build(),
model
);
ReActAgent agent = ReActAgent.builder()
.name("Assistant")
.model(model)
.memory(memory)
.build();
詳細文檔: 關於 AutoContextMemory 的 6 種壓縮策略、存儲架構和高級配置,請參考 AutoContextMemory 詳細文檔。
長期記憶技術架構及 Agent 框架集成
與短期記憶不同,長期記憶需要跨會話持久化存儲,並支持高效的檢索和更新。這需要一套完整的技術架構,包括信息提取、向量化存儲、語義檢索等核心組件。
4.1 核心組件
長期記憶涉及 record & retrieve 兩個核心流程,需要以下核心組件:
1. LLM 大模型: 提取短期記憶中的有效信息(記憶的語義理解、抽取、決策和生成)
2. Embedder 向量化: 將文本轉換為語義向量,支持相似性計算
3. VectorStore 向量數據庫: 持久化存儲記憶向量和元數據,支持高效語義檢索
4. GraphStore 圖數據庫: 存儲實體-關係知識圖譜,支持複雜關係推理
5. Reranker(重排序器): 對初步檢索結果按語義相關性重新排序
6. SQLite: 記錄所有記憶操作的審計日誌,支持版本回溯
4.2 Record & Retrieve 流程
Record(記錄)
LLM 事實提取 → 信息向量化 → 向量存儲 →(複雜關係存儲)→ SQLite 操作日誌
Retrieve(檢索)
User query 向量化 → 向量數據庫語義檢索 → 圖數據庫關係補充 →(Reranker-LLM)→ 結果返回
4.3 長期記憶與 RAG 的區別
像 Mem0 這類面向 AI Agent 的個性化長期記憶系統,與 RAG(Retrieval-Augmented Generation)在技術架構上有諸多相似之處,但功能層面和場景上有明顯區別:

技術層面的相似點:
-
向量化存儲:都將文本內容通過 Embedding 模型轉為向量,存入向量數據庫
-
相似性檢索:在用户提問時,將當前 query 向量化,在向量庫中檢索 top-k 最相關的條目
-
注入上下文生成:將檢索到的內容注入到模型交互上下文中,輔助 LLM 生成最終回答
4.4 關鍵問題與挑戰
長期記憶系統在實際應用中面臨諸多挑戰,這些挑戰直接影響系統的可用性和用户體驗。
1. 準確性
記憶的準確性包含兩個層面:
- 有效的記憶管理:需要具備智能的鞏固、更新和遺忘機制,這主要依賴於記憶系統中負責信息提取的模型能力和算法設計
- 記憶相關性的檢索準確度:主要依賴於向量化檢索&重排的核心能力
核心挑戰:
- 記憶的建模:需要完善強大的用户畫像模型
- 記憶的管理:基於用户畫像建模算法,提取有效信息,設計記憶更新機制
- 向量化相關性檢索能力:提升檢索準確率和相關性
2. 安全和隱私
記憶系統記住了大量用户隱私信息,如何防止數據中毒等惡意攻擊,並保障用户隱私,是必須解決的問題。
核心挑戰:
- 數據加密與訪問控制
- 防止惡意數據注入
- 透明的數據管理機制
- 用户對自身數據的掌控權
3. 多模態記憶支持
文本記憶、視覺、語音仍被孤立處理,如何構建統一的"多模態記憶空間"仍是未解難題。
核心挑戰:
- 跨模態關聯與檢索
- 統一的多模態記憶表示
- 毫秒級響應能力
4.5 Agent 框架集成
在 AgentScope 中,可以通過集成第三方長期記憶組件來實現長期記憶功能。常見的集成方式包括:
4.5.1 集成 Mem0
Mem0 是一個開源的長期記憶框架,幾乎成為事實標準。在 AgentScope 中集成 Mem0 的示例:
// 初始化Mem0長期記憶
Mem0LongTermMemory mem0Memory = new Mem0LongTermMemory(
Mem0Config.builder()
.apiKey("your-mem0-api-key")
.build()
);
// 創建Agent並集成長期記憶
ReActAgent agent = ReActAgent.builder()
.name("Assistant")
.model(model)
.memory(memory) // 短期記憶
.longTermMemory(mem0Memory) // 長期記憶
.build();
4.5.2 集成 ReMe
ReMe 是 AgentScope 官方提供的長期記憶實現,與框架深度集成:
// 初始化ReMe長期記憶
ReMeLongTermMemory remeMemory = ReMeLongTermMemory.builder()
.userId("user123") // 用户ID,用於記憶隔離
.apiBaseUrl("http://localhost:8002") // ReMe服務地址
.build();
// 創建Agent並集成長期記憶
ReActAgent agent = ReActAgent.builder()
.name("Assistant")
.model(model)
.memory(memory) // 短期記憶
.longTermMemory(remeMemory) // 長期記憶
.longTermMemoryMode(LongTermMemoryMode.BOTH) // 記憶模式
.build();
行業趨勢與產品對比
5.1 AI 記憶系統發展趨勢
AI 記憶系統的核心目標是讓 AI 能像人類一樣持續學習、形成長期記憶,從而變得更智能、更個性化。當前行業呈現出從研究原型向生產級系統演進、從單一技術向綜合解決方案發展的趨勢。
5.1.1 當前發展的核心脈絡

5.1.2 技術發展趨勢
記憶即服務(Memory-as-a-Service, MaaS)
AI Agent 是大模型、記憶、任務規劃以及工具使用的集合體,記憶管理將是 Agent 智能體的核心基礎功能之一。類似"數據庫"之於傳統軟件,記憶系統將成為 AI 應用的基礎設施,提供標準化的記憶服務接口、可擴展的存儲和檢索能力。
精細化記憶管理
借鑑人腦記憶機制,構建分層動態的記憶架構,對記憶進行全生命週期管理。技術路徑包括:LLM 驅動記憶提取 + 向量化存儲 + 圖數據庫補充;向量化檢索(海馬體)+ LLM 提純(大腦皮層)結合;通過強化學習提升記憶管理表現。
多模態記憶系統
多模態大模型的興起推動記憶系統向多模態、跨模態方向發展,要求存儲具備跨模態關聯與毫秒級響應能力。
參數化記憶(Model 層集成記憶)
在 Transformer 架構中引入可學習的記憶單元 Memory Adapter,實現模型層面原生支持用户維度的記憶。優點是響應速度快,但面臨"災難性遺忘"和更新成本高的挑戰。
5.1.3 當前主要的技術路徑
1. 外部記憶增強(當前主流): 使用向量數據庫等外部存儲來記憶歷史信息,並在需要時通過檢索相關信息注入當前對話。這種方式靈活高效,檢索的準確性是關鍵。
2. 參數化記憶(深度內化): 直接將知識編碼進模型的參數中。這可以通過模型微調、知識編輯等技術實現,優點是響應速度快,但面臨"災難性遺忘"和更新成本高的挑戰。
5.2 相關開源產品對比
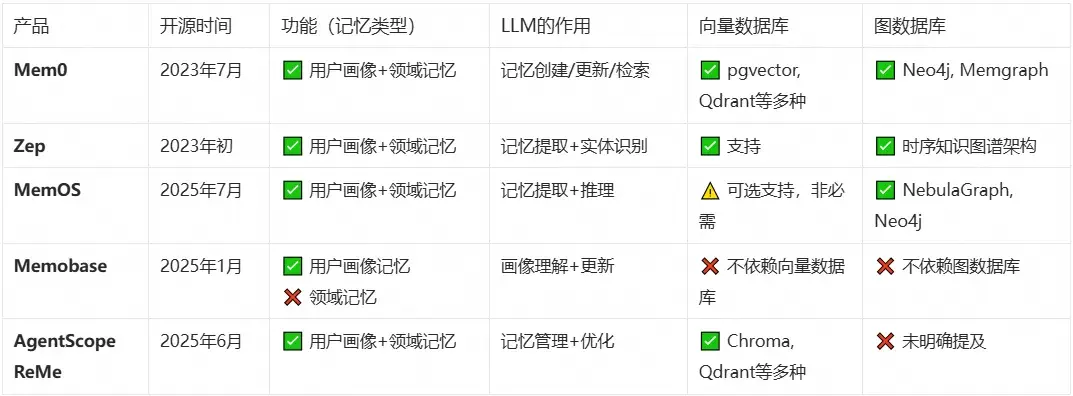
關於各產品的具體數據指標對比,評測方式各有側重,因此評測結果不盡相同,從實際情況看,各方均以 mem0 為評測基準,從各類技術指標評測結果以及開源社區的活躍度(star,issues 等)方面,mem0 仍然是佔據長期記憶產品的領頭地位。
結語
記憶系統作為 AI Agent 的核心基礎設施,其發展直接影響着智能體的能力和用户體驗。現在各框架內置的壓縮、卸載、摘要等策略,已經能解決 80-90% 的通用場景問題,但對於特定行業或場景,比如醫療、法律、金融等領域,基於通用的上下文處理策略基礎之上進行針對性的處理和更精細的壓縮 prompt 設計,仍然有較大的優化空間。而長期記憶作為可獨立演進的組件,未來會更加貼近人腦的記憶演化模式,包括記憶的鞏固、強化、遺忘等全生命週期管理,同時長期記憶應該以雲服務模式提供通用的記憶服務,共同助力 Agent 邁向更高階的智能。
相關閲讀:
《AgentScope Java 答疑時間:開發者近期最關心的 12 個問題》
《AgentScope x RocketMQ:打造企業級高可靠 A2A 智能體通信基座》
《AgentScope Java v1.0 發佈,讓 Java 開發者輕鬆構建企業級 Agentic 應用》
參考文檔:
[1] FlowLLM Context Engineering
https://github.com/FlowLLM-AI/flowllm/tree/main/docs/zh/reading
[2] Google ADK Memory
https://google.github.io/adk-docs/sessions/memory/
[3] LangChain Memory
https://docs.langchain.com/oss/python/langchain/long-term-memory
[4] AgentScope Memory
https://doc.agentscope.io/zh_CN/tutorial/task_memory.html
[5] O-MEM
https://arxiv.org/abs/2511.13593
