智元機器人團隊宣佈開源 VideoDataset,一個基於實際 AI 訓練需求深度開發的高性能視頻數據加載庫。
- 極致性能: 通過將解碼任務從傳統的 CPU 轉移到 GPU,充分挖掘硬件解碼能力,吞吐量提升 4 倍。
- 隨機訪問: 解決了硬件解碼通常不支持隨機尋幀 (Random Seek) 的業界難題,專為 AI 訓練設計的隨機採樣功能。
- 無縫集成: 兼容 PyTorch Dataset 接口,提供 Mixin 類,開發者改幾行代碼即可接入現有訓練流。
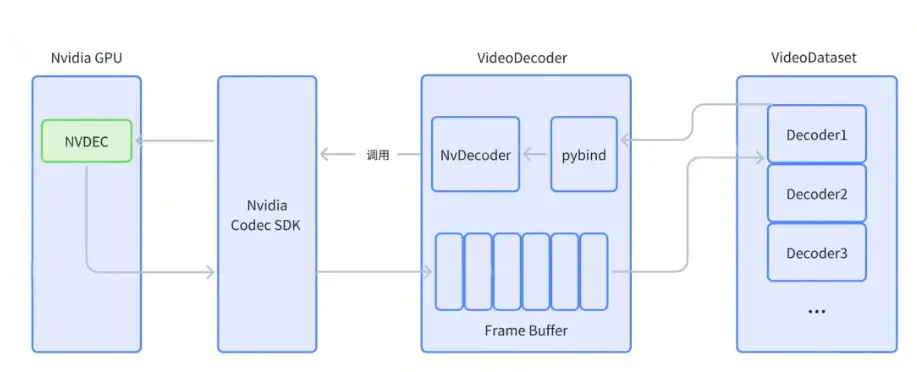
為了更直觀地評估 VideoDataset 的表現,智元方面進行了 VideoDataset 與主流 CPU 軟件解碼方案的全面性能對比測試,測試對象包括 OpenCV、Torchvision(PyAV)、Torchvision(VideoReader)和TorchCodec。
結果顯示,VideoDataset與主流 CPU 軟件解碼方案對比,在解碼吞吐量上提升了3到4倍。並且,它能更有效地分擔計算負載,從而將解碼任務近乎剝離CPU。這一優勢使得 VideoDataset 在大規模視頻數據訓練中不僅能提供更高的解碼效率,還能最大限度地利用GPU資源,提高整體訓練效率。
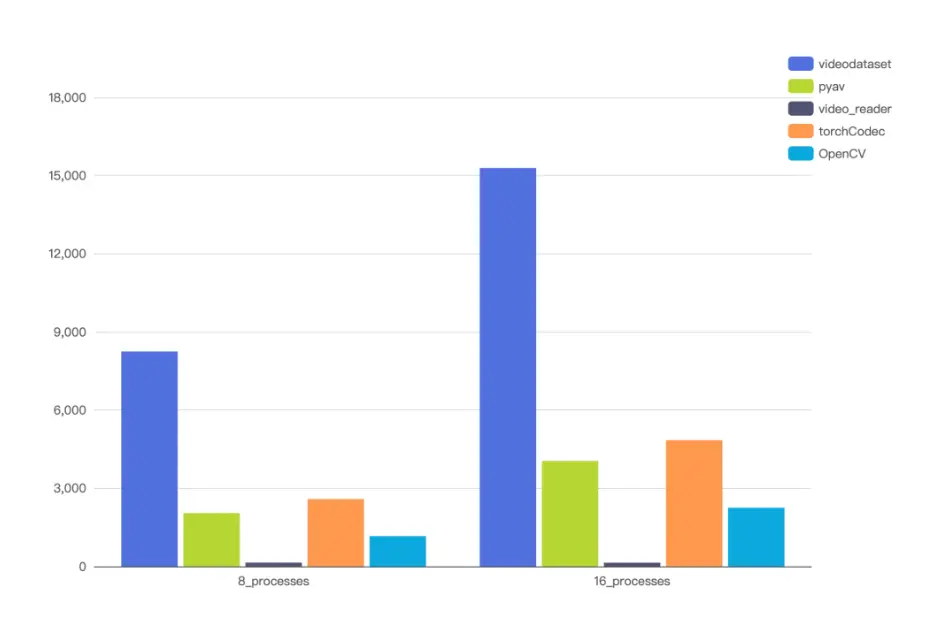
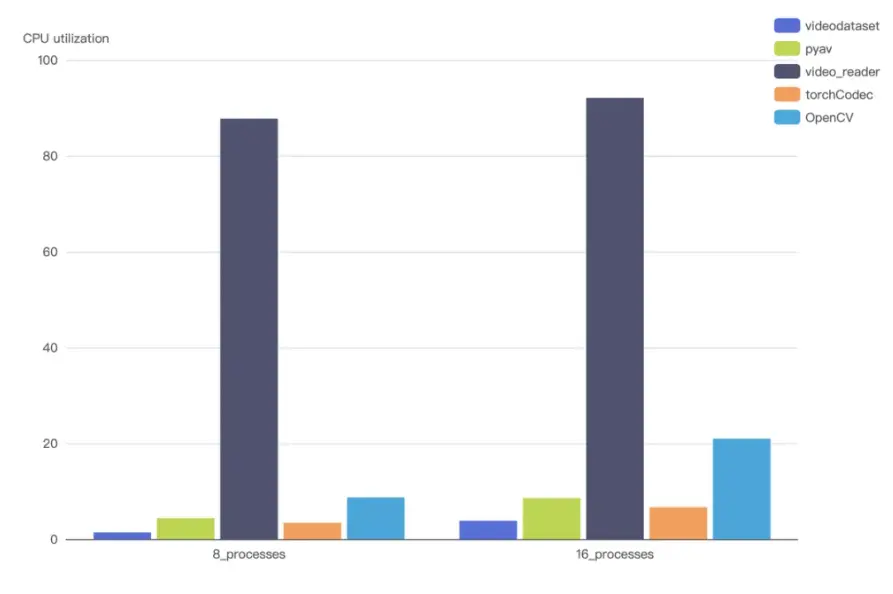
同時,由於支持多解碼器複用,在面對實際訓練中海量視頻隨機解碼的場景下,VideoDataset 的解碼吞吐量相比主流 GPU 硬件解碼方案同樣也有明顯的優勢。
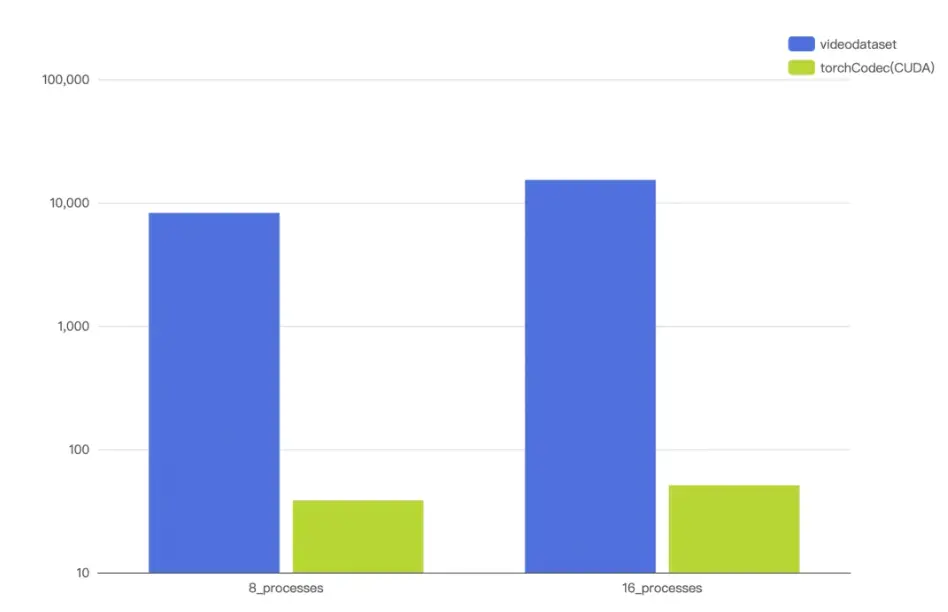
VideoDataset 基於 NVIDIA Video Codec SDK 進行封裝,通過多解碼器(Decoder)調度和生產者—消費者模型等多種手段實現瞭解碼與訓練的完全異步流水線,使解碼器利用率達到 90% 以上,提升瞭解碼性能和吞吐量。
並通過將視頻進行 GOP 級切分,支持快速定位到關鍵幀。這樣,解碼器無需解碼整個 GOP,只需要解碼到目標幀即可停止,從而實現了高效的隨機尋幀。還解決了 Python 多進程(spawn/fork)與 CUDA Context 的衝突,確保在 DataLoader 多 worker 模式下穩定運行。
公告透露,VideoDataset 接下來的版本更新將包括:
- 支持多級流水線優化,提升訓練流程的靈活性與效率;
- 完全支持Lerobot,推動生態系統的互聯互通;
- 面向PB級數據的分佈式存儲加載,處理海量數據不再是難題;
- 更多視頻格式的兼容,助力與HuggingFace生態深度集成。
