今天主要看SeaTunnel自研的數據同步引擎,叫Zeta。 首先,如果使用的是zeta引擎,那麼第一步一定是運行bin/seatunnel-cluster.sh腳本,這個腳本就是啓動zeta的服務端的。
打開seatunnel-cluster.sh看看,可以看到其實是去啓動seatunnel-core/seatunnel-starter/src/main/java/org/apache/seatunnel/core/starter/seatunnel/SeaTunnelServer.java中的main()方法
這個就是zeta的核心啓動方法了。
如下方代碼所示:
public class SeaTunnelServer {
public static void main(String[] args) throws CommandException {
ServerCommandArgs serverCommandArgs =
CommandLineUtils.parse(
args,
new ServerCommandArgs(),
EngineType.SEATUNNEL.getStarterShellName(),
acceptUnknownOptions: true
);
SeaTunnel.run(serverCommandArgs.buildCommand());
}
}
其實應該先看看ServerCommandArgs類,該類會基於命令參數拼裝啓動類,方法入口為serverCommandArgs.buildCommand()
@EqualsAndHashCode(callSuper = true)
@Data
public class ServerCommandArgs extends CommandArgs {
@Parameter(
names = {"-cn", "--cluster"},
description = "The name of cluster"
)
private String clusterName;
@Parameter(
names = {"-d", "--daemon"},
description = "The cluster daemon mode"
)
private boolean daemonMode = false;
@Parameter(
names = {"-r", "--role"},
description =
"The cluster node role, default is master_and_worker, " +
"support master, worker, master_and_worker"
)
private String clusterRole;
@Override
public Command<?> buildCommand() {
return new ServerExecuteCommand(this);
}
}
接着SeaTunnel.run()會啓動SeaTunnelServer,啓動流程如下:
共分為以下步驟:
1)校驗當前環境 2)加載SeaTunnel配置 3)設置節點角色,包含Master、Worker、Master_And_Worker 4)創建Hazelcast實例,用於集羣發現、註冊、分佈式數據管理等
@Override
public void execute() {
// Validate environment
checkEnvironment();
// Load SeaTunnel configuration
SeaTunnelConfig seaTunnelConfig = ConfigProvider.locateAndGetSeaTunnelConfig();
String clusterRole = this.serverCommandArgs.getClusterRole();
// Set node role
if (StringUtils.isNotBlank(clusterRole)) {
if (EngineConfig.ClusterRole.MASTER.toString().equalsIgnoreCase(clusterRole)) {
seaTunnelConfig.getEngineConfig().setClusterRole(EngineConfig.ClusterRole.MASTER);
} else if (EngineConfig.ClusterRole.WORKER.toString().equalsIgnoreCase(clusterRole)) {
seaTunnelConfig.getEngineConfig().setClusterRole(EngineConfig.ClusterRole.WORKER);
// In Hazelcast lite node, it will not store IMap data.
seaTunnelConfig.getHazelcastConfig().setLiteMember(true);
} else {
throw new SeaTunnelEngineException("Not supported cluster role: " + clusterRole);
}
} else {
seaTunnelConfig.getEngineConfig().setClusterRole(EngineConfig.ClusterRole.MASTER_AND_WORKER);
}
// Create Hazelcast instance for cluster discovery, registration, and distributed data management
SeaTunnelServerStarter.createHazelcastInstance(seaTunnelConfig, Thread.currentThread().getName());
}
節點角色説明:
- Master 節點:
- 核心職責:負責集羣的作業調度、狀態管理及資源協調。Master 節點運行 CoordinatorService 服務,處理作業的邏輯計劃(LogicalDAG)到物理計劃(PhysicalDAG)的轉換,並生成執行計劃。此外,它還管理檢查點(Checkpoint)機制和作業監控指標。
- 高可用性:採用 Active/Standby 模式,同一時間僅有一個 Active Master,其餘為 Standby。當 Active Master 故障時,會觸發選舉新 Master,確保集羣持續運行。
- 數據存儲:通過內置的分佈式內存網格(如 Hazelcast IMap)存儲作業狀態和元數據,無需依賴外部系統(如 ZooKeeper)。在分離部署模式下,所有狀態數據僅存儲在 Master 節點,避免 Worker 節點負載影響數據穩定性。
- Worker 節點:
- 核心職責:執行具體的數據處理任務。Worker 節點運行 TaskExecutionService 和 SlotService,前者提供任務運行時環境,後者管理節點的資源分配(如 CPU 核心數)。
- 動態資源分配:通過 SlotService 實現資源的動態劃分,支持按任務並行度動態調整資源,提升資源利用率。
- 無狀態設計:Worker 節點不存儲作業狀態數據,僅負責計算。在容錯場景下,Worker 故障後任務會被重新調度到其他節點,依賴 Master 存儲的狀態恢復。
- 混合角色節點(舊架構):
- 在早期版本中,節點角色未嚴格分離,同一節點可同時作為 Master 和 Worker(稱為 master_and_worker 模式)。此架構下,節點既參與調度又執行任務,但在高負載場景下可能導致容錯效率問題(如主節點故障引發連鎖負載壓力)。
- 新架構優化:2.3.6 版本後推薦分離部署模式,徹底解耦 Master 與 Worker 角色,提升集羣穩定性和擴展性。
接着回到上面的創建Hazelcast實例:
如下所示,核心代碼為:HazelcastInstanceFactory.newHazelcastInstance方法,該方法表示創建了Hazelcast實例;
private static HazelcastInstanceImpl initializeHazelcastInstance(
@NonNull SeaTunnelConfig seaTunnelConfig, String customInstanceName) {
// Set the default async executor for Hazelcast InvocationFuture
ConcurrencyUtil.setDefaultAsyncExecutor(CompletableFuture.EXECUTOR);
// Check whether to enable metrics reporting
boolean condition = checkTelemetryConfig(seaTunnelConfig);
String instanceName = customInstanceName != null
? customInstanceName
: HazelcastInstanceFactory.createInstanceName(seaTunnelConfig.getHazelcastConfig());
// Create Hazelcast instance
HazelcastInstanceImpl original = ((HazelcastInstanceProxy)
HazelcastInstanceFactory.newHazelcastInstance(
seaTunnelConfig.getHazelcastConfig(),
instanceName,
new SeaTunnelNodeContext(seaTunnelConfig)))
.getOriginal();
// Initialize telemetry instance
// Enable metrics reporting, including: JvmCollector, JobInfoDetail, ThreadPoolStatus, NodeMetrics, ClusterMetrics
if (condition) {
initTelemetryInstance(original.node);
}
return original;
}
其中,最重要的就是這句代碼中的new SeaTunnelNodeContext(seaTunnelConfig),這裏會返回一個SeaTunnelNodeContext類,這個類是繼承自Hazelcast這個組件的DefaultNodeContext類。在Hazelcast啓動的過程中,會去調用DefaultNodeContext類的實現類的createNodeExtension()方法,在這裏其實也就是SeaTunnelNodeContext類的createNodeExtension()方法。這裏不具體展開講解Hazelcast類,大家可以去查一下其他Hazelcast資料。
然後我們接着分析在Hazelcast節點啓動時會調用createNodeExtension方法
@Slf4j
public class SeaTunnelNodeContext extends DefaultNodeContext {
private final SeaTunnelConfig seaTunnelConfig;
public SeaTunnelNodeContext(@NonNull SeaTunnelConfig seaTunnelConfig) {
this.seaTunnelConfig = seaTunnelConfig;
}
@Override
public NodeExtension createNodeExtension(@NonNull Node node) {
return new org.apache.seatunnel.engine.server.NodeExtension(node, seaTunnelConfig);
}
}
這裏跟蹤進去,查看節點擴展的實現,這裏初始化了Zeta引擎。
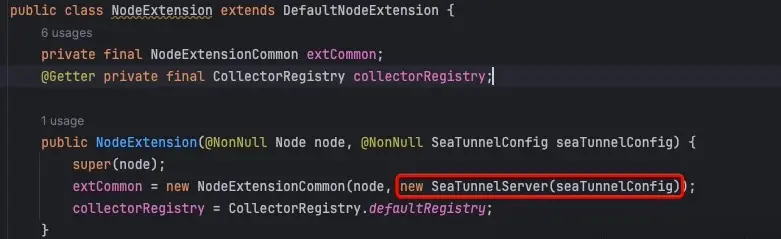
SeaTunnelServe類實現了一系列Hazelcast接口,用於監聽集變更狀態,包含:節點初始化、集羣節點加入/移除,跟蹤和管理分佈式系統操作;
接下來依次分析各個操作:
1)節點初始化:
這個初始化方法為SeaTunnel服務器提供了完整的啓動流程,確保了各個服務組件的正確初始化和配置;
核心方法包括: startMaster()方法和startWorker()方法
@Override
public void init(NodeEngine engine, Properties hzProperties) {
this.nodeEngine = (NodeEngineImpl) engine;
// TODO: Decide whether to run these methods on the master node based on deployment type
classLoaderService = new DefaultClassLoaderService(
seaTunnelConfig.getEngineConfig().isClassLoaderCacheMode(), nodeEngine);
// Handles event processing and forwarding
eventService = new EventService(nodeEngine);
// Start Master / Worker capabilities
if (EngineConfig.ClusterRole.MASTER_AND_WORKER.ordinal()
== seaTunnelConfig.getEngineConfig().getClusterRole().ordinal()) {
startWorker();
startMaster();
} else if (EngineConfig.ClusterRole.WORKER.ordinal()
== seaTunnelConfig.getEngineConfig().getClusterRole().ordinal()) {
startWorker();
} else {
startMaster();
}
// SeaTunnel health-check monitor
seaTunnelHealthMonitor = new SeaTunnelHealthMonitor(((NodeEngineImpl) engine).getNode());
// Task log management service
if (seaTunnelConfig.getEngineConfig().getTelemetryConfig() != null
&& seaTunnelConfig.getEngineConfig().getTelemetryConfig().getLogs() != null
&& seaTunnelConfig.getEngineConfig().getTelemetryConfig().getLogs().isEnabled()) {
taskLogManagerService = new TaskLogManagerService(
seaTunnelConfig.getEngineConfig().getTelemetryConfig().getLogs());
taskLogManagerService.initClean();
}
// Start Jetty service: provides HTTP REST API, Web UI, job management, monitoring endpoints, etc.
if (seaTunnelConfig.getEngineConfig().getHttpConfig().isEnabled()) {
jettyService = new JettyService(nodeEngine, seaTunnelConfig);
jettyService.createJettyServer();
}
// A trick to fix StatisticsDataReference cleaner thread class-loader leak.
// See https://issues.apache.org/jira/browse/HADOOP-19049
FileSystem.Statistics statistics = new FileSystem.Statistics("SeaTunnel");
}
首先是startMaster方法,主要初始化了協調器服務、檢查點服務、監控服務;
各個服務職責如下:
-
協調器服務:負責作業調度管理、集羣資源協同、任務分配、狀態同步等;
-
檢查點服務:檢查點管理、數據一致性保證、故障恢復支持、狀態保存和恢復等;
-
監控服務:定期打印執行信息、監控系統狀態、性能指標收集;
private void startMaster() { // Initialize coordinator service coordinatorService = new CoordinatorService(nodeEngine, this, seaTunnelConfig.getEngineConfig());
// Initialize checkpoint service checkpointService = new CheckpointService(seaTunnelConfig.getEngineConfig().getCheckpointConfig()); // Initialize monitoring service monitorService = Executors.newSingleThreadScheduledExecutor(); monitorService.scheduleAtFixedRate( this::printExecutionInfo, 0, // initial delay seaTunnelConfig.getEngineConfig().getPrintExecutionInfoInterval(), TimeUnit.SECONDS);}
其次是startWorker方法,這裏重點介紹TaskExecutionService服務,通過這個服務,SeaTunnel能夠高效地執行各種數據處理任務,同時保證系統的穩定性和可靠性;
private void startWorker() {
// 1. Initialize task execution service
taskExecutionService = new TaskExecutionService(classLoaderService, nodeEngine, eventService);
// 2. Register metrics collector
nodeEngine.getMetricsRegistry().registerDynamicMetricsProvider(taskExecutionService);
// 3. Start task execution service
taskExecutionService.start();
// 4. Initialize slot service
getSlotService();
}
其實在SeaTunnelServer最核心的就是調用TaskExecutionService類的start()方法,基本流程如下圖所示:
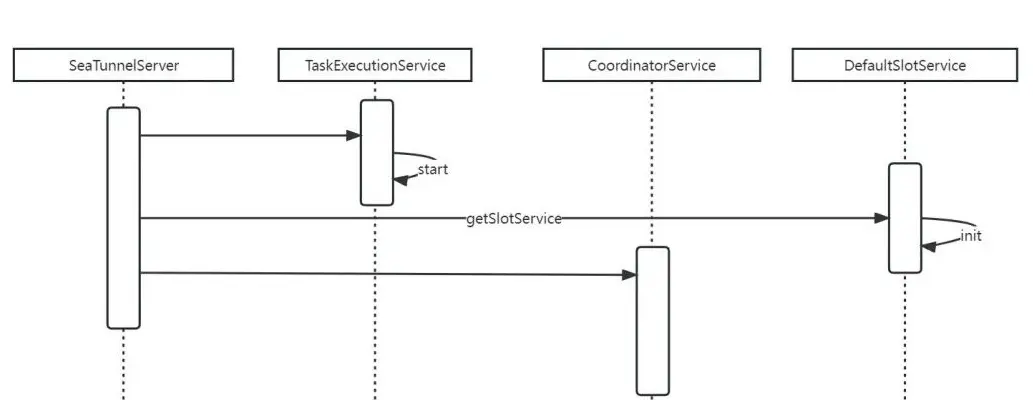
這裏引用來自一篇官方文章的介紹文字:
- TaskExecutionService TaskExecutionService 是一個執行任務的服務,將在每個節點上運行一個實例。它從 JobMaster 接收 TaskGroup 並在其中運行 Task。並維護TaskID->TaskContext,對Task的具體操作都封裝在TaskContext中。而Task內部持有OperationService,也就是説Task可以通過OperationService遠程調用其他Task或JobMaster進行通信。
- CoordinatorService CoordinatorService是一個充當協調器的服務,它主要負責處理客户端提交的命令以及切換master後任務的恢復。客户端在提交任務時會找到master節點並將任務提交到CoordinatorService服務上,CoordinatorService會緩存任務信息並等待任務執行結束。當任務結束後再對任務進行歸檔處理。
- SlotService SlotService是slot管理服務,用於管理集羣的可用Slot資源。SlotService運行在所有節點上並定期向master上報資源信息。
2)集羣節點加入/移除:
memberAdded:處理集羣成員加入事件
memberRemoved:處理集羣成員離開事件
這裏説明下問什麼memberAdded是空實現:
a) 設計考慮:
成員加入是一個正常的事件,不需要特殊處理;
新成員加入時會自動進行初始化;
資源分配和任務調度是動態的;
b)實際原因:
新成員加入時,會通過其他機制(如SlotService)自動處理資源分配;
任務調度是動態的,不需要在成員加入時特別處理;
保持簡單性,避免不必要的複雜性;
memberRemoved主要處理邏輯:只在主節點上處理成員移除事件,成員移除需要處理的關鍵問題:
a)資源回收:釋放離開節點的資源、重新分配任務、清理相關狀態;
b)任務重分配:重新分配離開節點的任務、確保任務繼續執行、維護任務狀態
c)狀態維護:更新集羣狀態、維護成員列表、更新資源分配;
為什麼需要memberRemoved:
a)可靠性考慮:節點離開可能影響任務執行、需要確保數據一致性、需要保證系統可用性;
b)資源管理:需要及時釋放資源、需要重新分配任務、需要維護集羣狀態;
3)跟蹤和管理分佈式系統操作:
實現是空的,説明在當前版本沒有特別需要跟蹤的操作;
@Override
public void populate(LiveOperations liveOperations) {
// In SeaTunnelServer this implementation is empty,
// indicating the current version has no special operations to track.
}
最後,分享一個在本地Idea環境啓動過程中的問題:
如下所示,官方默認配置為hdfs方式,由於本地缺少hdfs環境,因此會阻礙服務啓動,調整為localfile本地即可啓動。
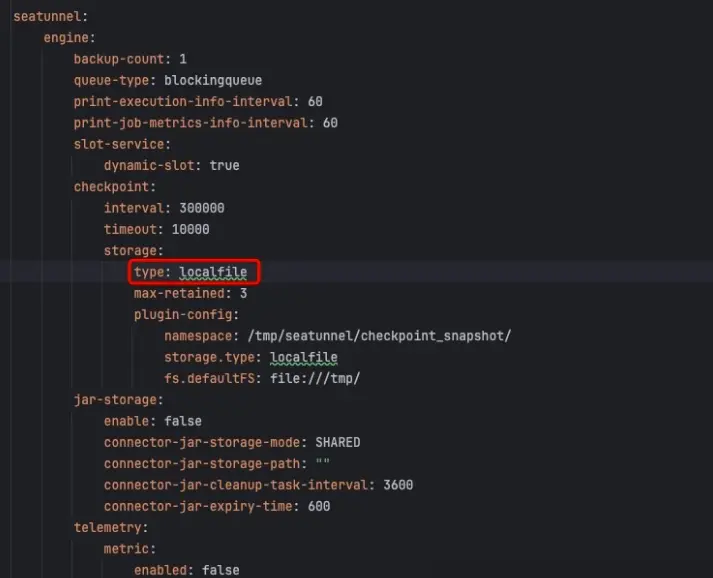
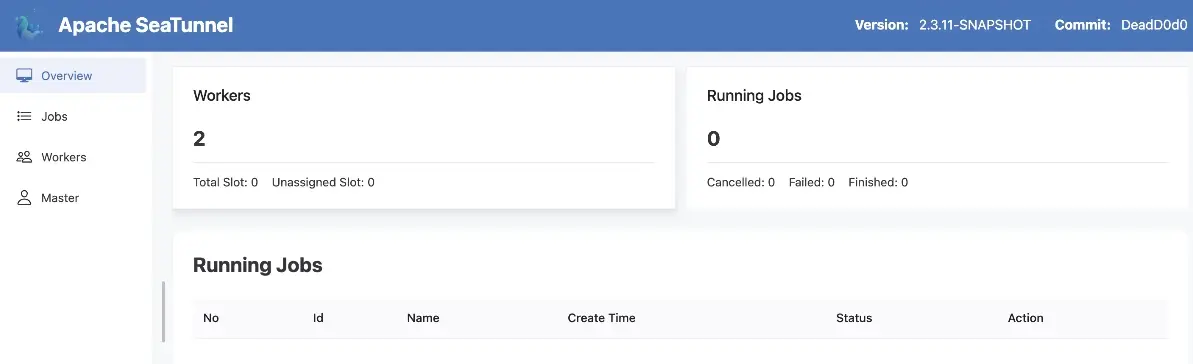
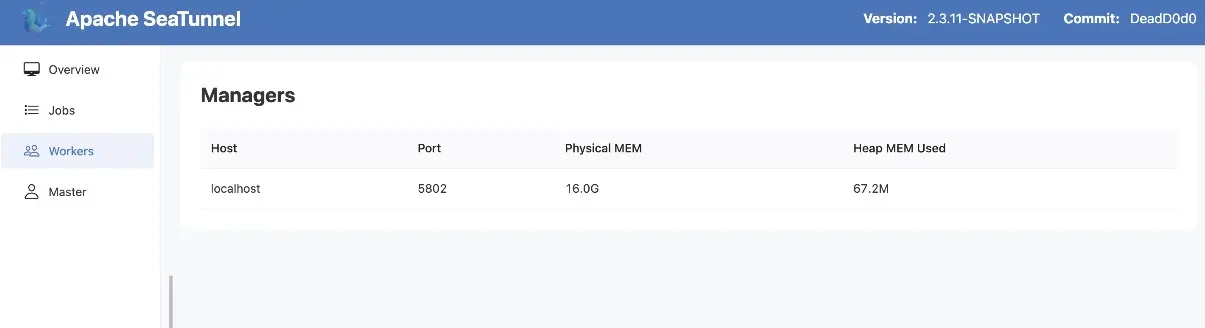
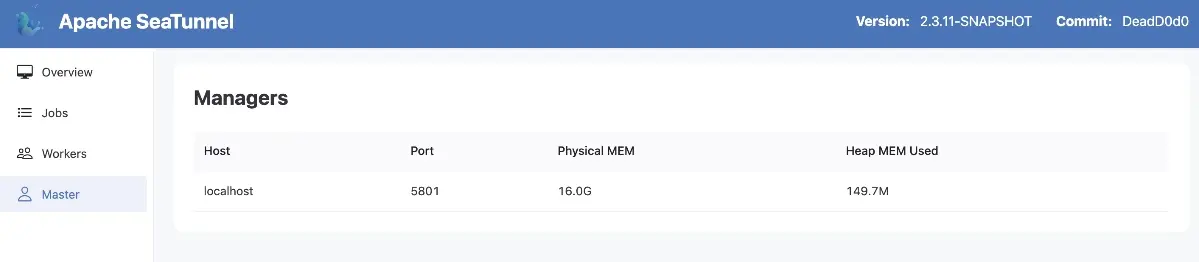
最後,訪問localhost:8080即可查看服務狀態: