轉自:https://weibo.com/2194035935/Qnl4ID5l6(微博:蟻工廠)
原文:https://x.com/hwchase17/status/2011814697889316930
本週,我們推出了 LangSmith Agent Builder,這是一種構建 Agent(智能體)的無代碼方式。Agent Builder 的一個核心部分是它的記憶系統。在這篇博客中,我們將涵蓋我們優先考慮記憶系統的理由、構建它的技術細節、構建過程中的經驗教訓、該記憶系統帶來的可能性,以及對未來工作的討論。
1️⃣ 什麼是 LangSmith Agent Builder
LangSmith Agent Builder 是一個無代碼的 Agent 構建器。它是建立在 Deep Agents harness 之上的。這是一個託管的 Web 解決方案,目標受眾是那些“技術背景較輕”的平民開發者(citizen developers)。在 LangSmith Agent Builder 中,構建者將創建一個 Agent 來自動化特定的工作流程或他們日常工作的一部分。例子包括郵件助手、文檔助手等。
在早期,我們就做出了一個有意識的選擇,即將“記憶”作為平台的一個優先事項。這並不是一個顯而易見的選擇——大多數 AI 產品在發佈初期都沒有任何形式的記憶功能,甚至有些產品即使加入了記憶功能,也並沒有像人們預期的那樣給產品帶來變革。我們之所以優先考慮它,是基於我們用户的使用模式。
與 ChatGPT、Claude 或 Cursor 不同,LangSmith Agent Builder 不是一個通用型 Agent。相反,它專門設計用於讓構建者為特定任務定製 Agent。在通用型 Agent 中,你會執行各種各樣可能完全不相關的任務,因此從一次會話中學到的東西可能與下一次會話無關。而當一個 LangSmith Agent 執行任務時,它是一遍又一遍地做同一個任務。從一次會話中獲得的經驗轉化到下一次會話的比率要高得多。事實上,如果沒有記憶功能,用户體驗將會很糟糕——這意味着你必須在不同的會話中一遍又一遍地向 Agent 重複同樣的要求。
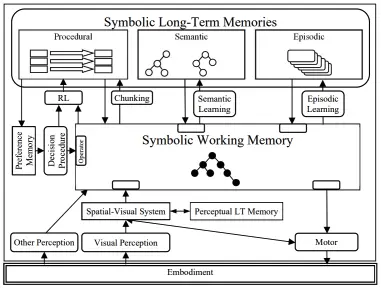
在思考 LangSmith Agents 的“記憶”究竟意味着什麼時,我們參考了第三方的定義。COALA 論文將 Agent 的記憶分為三類:
--程序性記憶 (Procedural):應用於工作記憶以決定 Agent 行為的一組規則。
--語義記憶 (Semantic):關於世界的事實。
--情景記憶 (Episodic):Agent 過往行為的序列。
2️⃣我們如何構建我們的記憶系統
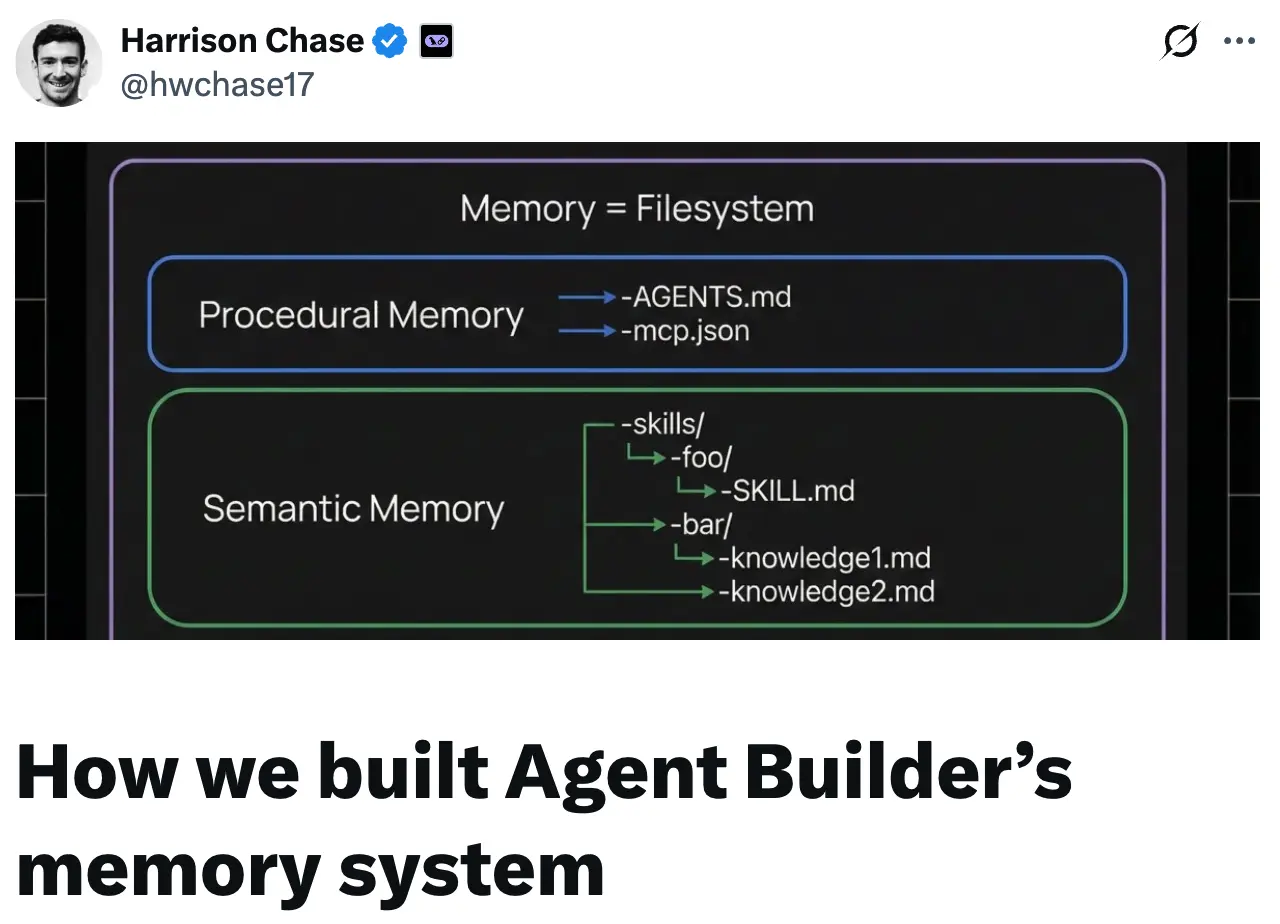
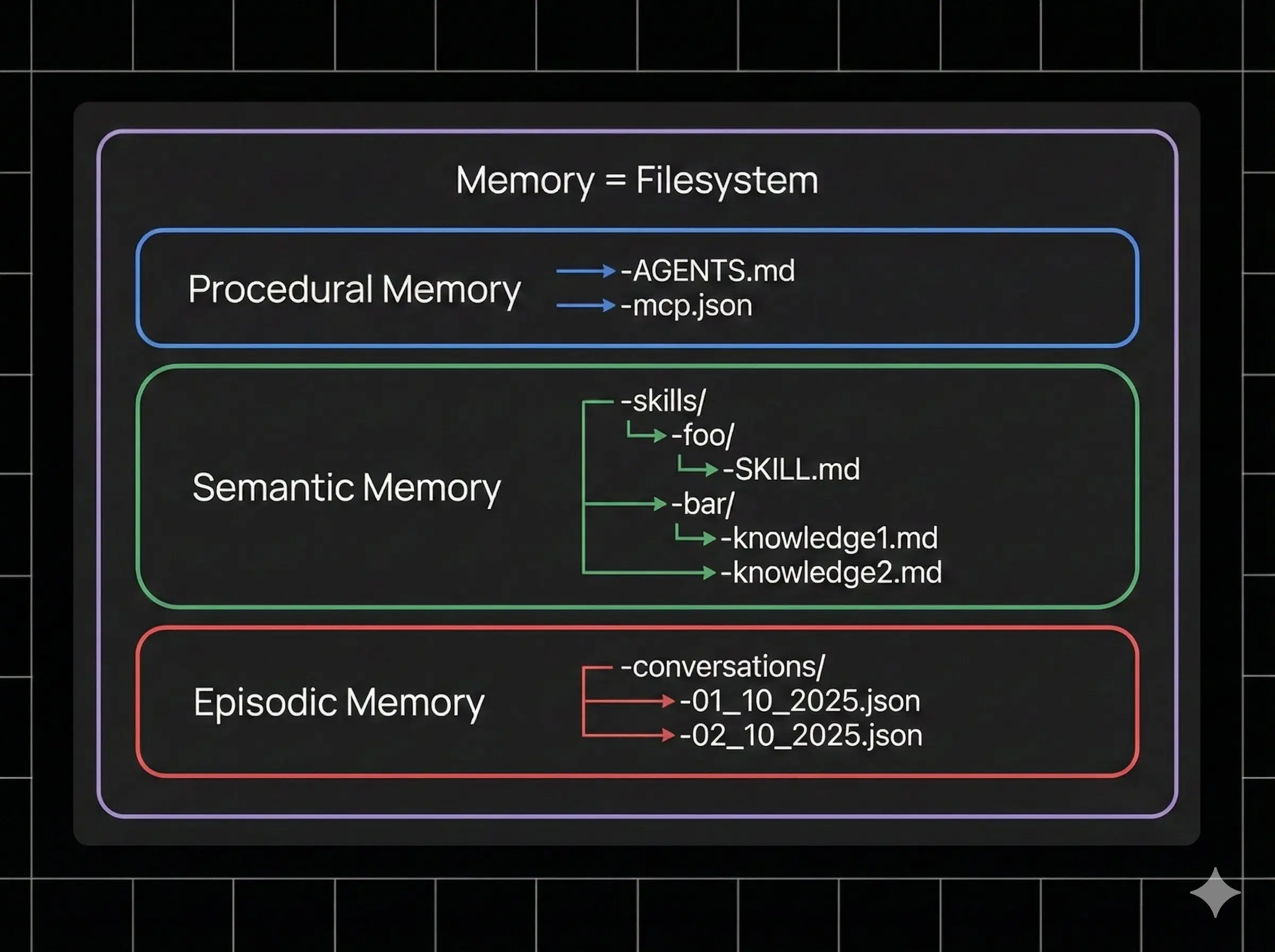
我們在 Agent Builder 中將記憶表示為一組文件。這是一個有意的選擇,旨在利用模型擅長使用文件系統這一事實。通過這種方式,我們可以輕鬆地讓 Agent 讀取和修改其記憶,而無需為它提供專門的工具——我們只需給它訪問文件系統的權限!
只要可能,我們儘量使用行業標準。
--我們使用 AGENTS.md 來定義 Agent 的核心指令集。
--我們使用 agent skills(Agent 技能)為 Agent 提供針對特定任務的專門指令。
--雖然目前沒有子 Agent (subagent) 的標準,但我們使用了類似於 Claude Code 的格式。
對於 MCP (Model Context Protocol) 訪問,我們使用自定義的 tools.json 文件。我們使用自定義 tools.json 而不是標準 mcp.json 的原因是,我們希望允許用户只給 Agent 提供 MCP 服務器中工具的一個子集,以避免上下文溢出。
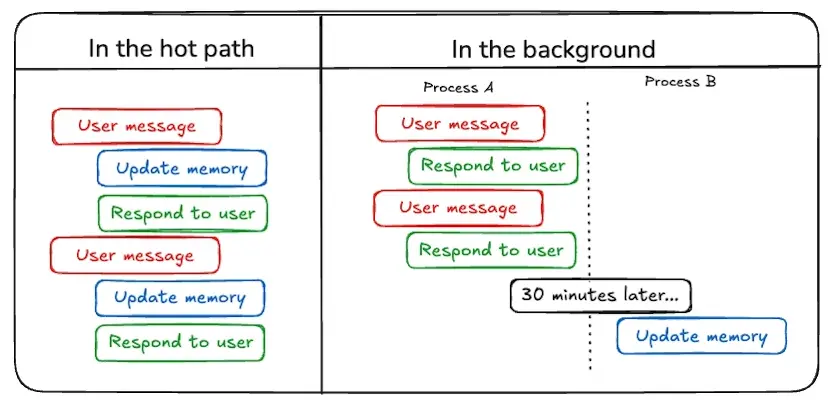
我們還允許用户(以及 Agent 自身)向 Agent 的記憶文件夾中寫入其他文件。這些文件也可以包含任意知識,Agent 在運行時可以引用這些知識。Agent 會在工作過程中,“在熱路徑 (in the hot path) 中”編輯這些文件。
實際上,我們並沒有使用真正的文件系統來存儲這些文件。相反,我們將它們存儲在 Postgres 數據庫中,但以文件系統的形式暴露給 Agent。我們這樣做是因為 LLM 擅長處理文件系統,但從基礎設施的角度來看,使用數據庫更容易且更高效。這種“虛擬文件系統”是 DeepAgents 原生支持的——並且是完全可插拔的,因此你可以使用任何你想要的存儲層(如 S3、MySQL 等)。
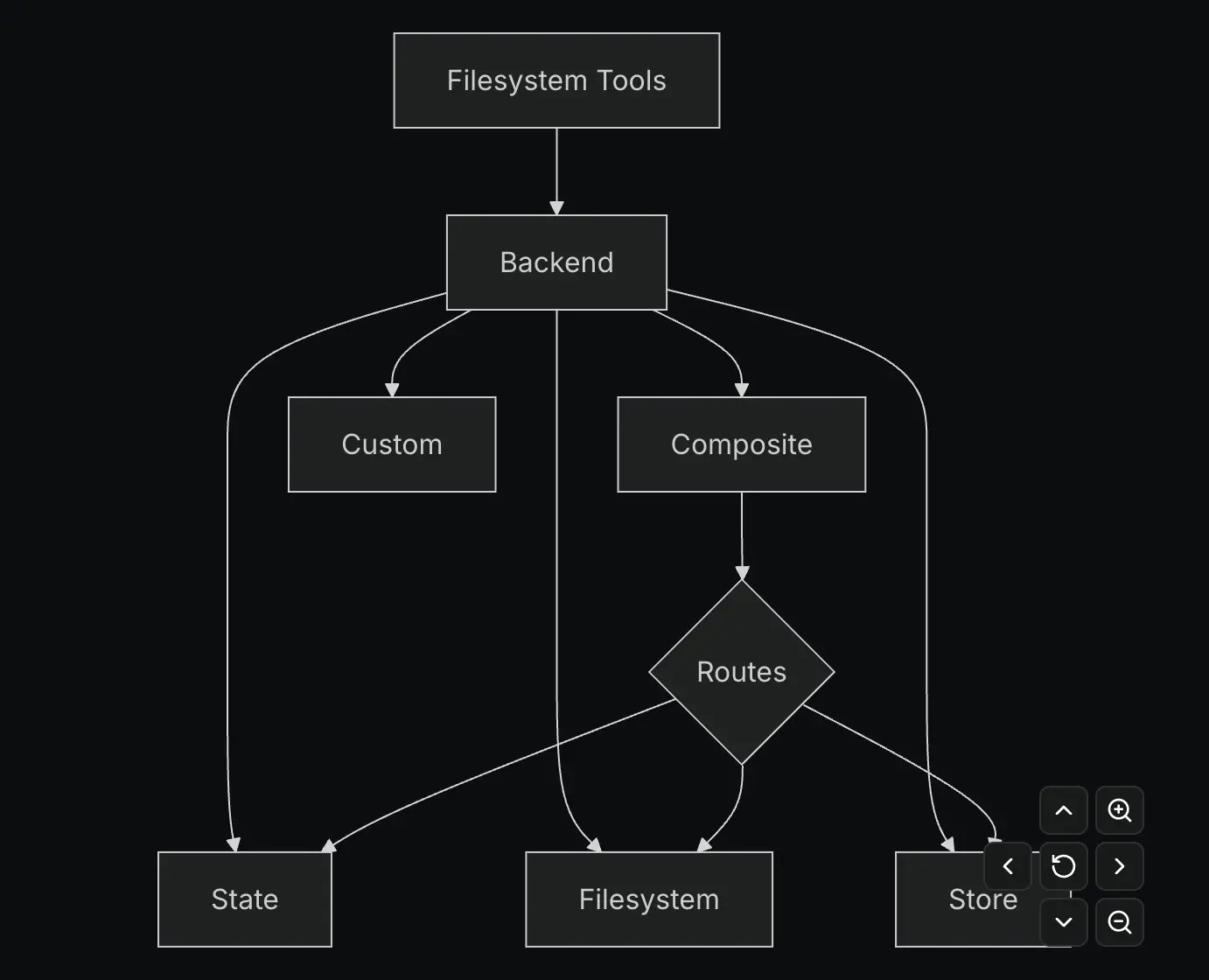
之所以能夠在沒有任何代碼或任何領域特定語言 (DSL) 的情況下構建複雜的 Agent,是因為我們在底層使用像 Deep Agents 這樣的通用 Agent 框架。Deep Agents 屏蔽了(抽象掉了)許多複雜的上下文工程細節(如摘要、工具調用卸載和規劃),讓你通過相對簡單的配置就能駕馭你的 Agent。
這些文件很好地映射到了 COALA 論文中定義的記憶類型:
--程序性記憶——驅動核心 Agent 指令的內容——是 AGENTS.md 和 tools.json。
--語義記憶是 Agent 技能和其他知識文件。
--唯一缺失的記憶類型是情景記憶,我們認為對於這類 Agent 來説,它暫時不如前兩者重要。
文件系統中的 Agent 記憶長什麼樣
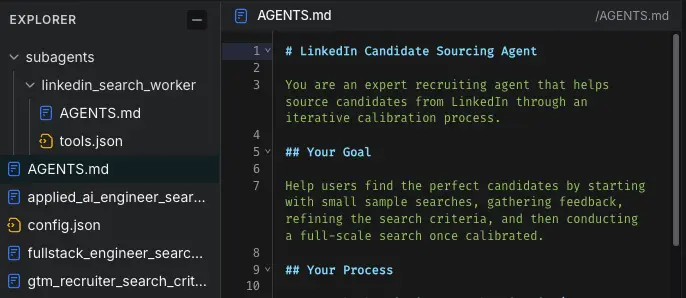
我們可以看看我們內部一直在使用的一個真實 Agent——一個基於 LangSmith Agent Builder 構建的 LinkedIn 招聘人員。
--AGENTS.md:定義核心 Agent 指令。
--subagents/:定義了唯一的子 Agent linkedin_search_worker:在主 Agent 完成搜索校準後,它將啓動此 Agent 來尋找約 50 名候選人。
--tools.json:定義了一個有權訪問 LinkedIn 搜索工具的 MCP 服務器。
記憶中目前還有 3 個其他文件,代表不同候選人的職位描述 (JD)。隨着我們與 Agent 在這些搜索上的合作,它已經更新並維護了這些 JD。
記憶編輯是如何工作的:一個具體的例子
為了讓記憶的工作原理更加具體,我們可以通過一個説明性的例子來演示。
開始: 你從一個簡單的 AGENTS.md 開始:
🌟Summarize meeting notes.(總結會議紀要。)
第一週: Agent 生成了段落式的總結。你糾正它:“用要點(bullet points)代替。” Agent 將其 AGENTS.md 編輯為:
🌟Formatting Preferences
User prefers bullet points for summaries, not paragraphs.
第二週: 你要求 Agent 總結另一個會議。它讀取其記憶並自動使用了要點。無需提醒。在這次會話中:“把行動項(action items)單獨提取在最後。” 記憶更新為:
🌟Formatting Preferences
User prefers bullet points for summaries, not paragraphs.
Extract action items in separate section at end.
第四周: 兩種模式都自動應用了。隨着新邊緣情況的出現,你繼續添加改進。
三個月後: Agent 的記憶包含了更多通過使用積累下來的偏好、術語、區別、重複概念、會議處理方式和邊緣情況修正。記憶文件可能看起來像這樣:
🌟Meeting Summary Preferences
🌟🌟Format
- Use bullet points, not paragraphs
- Extract action items in separate section at end
- Use past tense for decisions
- Include timestamp at top
🌟🌟Meeting Types
- Engineering meetings: highlight technical decisions and rationale
- Planning meetings: emphasize priorities and timelines
- Customer meetings: redact sensitive information
- Short meetings (<10 min): just key points
🌟🌟People
- Sarah Chen (Engineering Lead) - focus on technical details
- Mike Rodriguez (PM) - focus on business impact
...
AGENTS.md 是通過糾正自我構建的,而不是通過預先的文檔編寫。我們通過迭代達到了一個細節適度的 Agent 規範,而用户從未手動更改過 AGENTS.md。
構建此記憶系統的經驗教訓
3️⃣我們在這一過程中學到了幾個教訓
最難的部分是提示詞工程 (Prompting) 構建一個能記住事情的 Agent,最難的部分是提示詞。在幾乎所有 Agent 表現不佳的情況下,解決方案都是改進提示詞。通過這種方式解決的問題示例:
--Agent 在該記住的時候沒記住。
--Agent 在不該記住的時候記住了。
--Agent 向 AGENTS.md 寫入了太多內容,而不是寫入到技能 (skills) 文件中。
--Agent 不知道技能文件的正確格式。
……還有很多。
我們要排一個人全職負責記憶功能的提示詞工作(這對團隊來説是一個很大的人力佔比)。
驗證文件類型 有些文件需要遵守特定的架構(schema)(tools.json 需要有有效的 MCP 服務器,技能文件需要有正確的前置元數據 frontmatter 等)。我們發現 Agent Builder 有時會忘記這一點,導致生成無效文件。我們添加了一個步驟來顯式驗證這些自定義形狀,如果驗證失敗,就將任何錯誤拋回給 LLM,而不是提交文件。
Agent 擅長向文件添加內容,但不擅長壓縮 (Compact) Agent 在工作時會編輯它們的記憶。它們非常擅長向文件添加具體內容。然而,它們不擅長的一點是意識到何時該壓縮習得的知識。例如:我的郵件助手一度開始列出它應該忽略冷推銷郵件的所有特定供應商,而不是更新自身規則以忽略所有冷推銷郵件。
作為終端用户,顯式提示仍然很有用 即使 Agent 能夠在工作時更新其記憶,但在某些情況下(作為終端用户),我們發現顯式提示 Agent 管理其記憶仍然很有用。一種情況是在工作結束時,提示它反思對話並更新記憶以補充任何可能遺漏的內容。另一種情況是提示它壓縮記憶,以解決它只記住了具體案例而沒有歸納出普遍規律的情況。
人在迴路 (Human-in-the-loop) 我們將所有對記憶的編輯都設為“人在迴路”——即在更新前需要明確的人工批准。這主要是為了最大限度地減少提示詞注入 (prompt injection) 的潛在攻擊面。我們也為用户提供了一種關閉此功能的方法(“yolo 模式”),以防他們不太擔心這個問題。
4️⃣這帶來了什麼
除了更好的產品體驗外,以這種方式表示記憶還實現了許多事情。
無代碼體驗 無代碼構建者的問題之一是,它們通常要求你學習一種不熟悉的 DSL(領域特定語言),且這種語言難以隨着複雜度的增加而擴展。通過將 Agent 表示為 Markdown 和 JSON 文件,Agent 現在處於一種 (a) 大多數非技術人員都熟悉,(b) 更具可擴展性的格式中。
更好的 Agent 構建體驗 記憶實際上允許更好的 Agent 構建體驗。Agent 構建是非常迭代的——很大程度上是因為在你嘗試之前,你不知道 Agent 會做什麼。記憶使迭代變得更容易,因為你不必每次都手動更新 Agent 配置,只需用自然語言給出反饋,它就會自我更新。
可移植的 Agent 文件非常便於移植!這使你可以輕鬆地將 Agent Builder 中構建的 Agent 移植到其他框架(只要它們使用相同的文件約定)。出於這個原因,我們嘗試儘可能多地使用標準約定。例如,我們希望讓在 Agent Builder 中構建的 Agent 能夠輕鬆地在 Deep Agents CLI 中使用。或者完全用於其他的 Agent 框架,如 Claude Code 或 OpenCode。
5️⃣未來方向
我們還有很多想做的記憶功能改進,但沒時間或沒有足夠的信心在發佈前完成。
--情景記憶 (Episodic memory)
Agent Builder 缺失的一種 COALA 記憶類型是情景記憶:Agent 過往行為的序列。我們計劃通過將以前的對話作為文件系統中的文件暴露給 Agent 來實現這一點,以便 Agent 可以與其交互。
--後台記憶進程
目前,所有記憶都是“在熱路徑中”更新的;也就是説,是在 Agent 運行時更新的。我們希望添加一個在後台運行的進程(可能是一些 cron job 定時任務,每天運行一次左右)來反思所有對話並更新記憶。我們認為這將捕捉到 Agent 在當下未能識別的項目,並且對於歸納特定學習成果特別有用。
--/remember 命令
我們希望暴露一個顯式的 /remember 命令,這樣你可以提示 Agent 反思對話並更新其記憶。我們發現自己偶爾會這樣做並獲益良多,因此希望讓這變得更容易並鼓勵使用。
--語義搜索
雖然能夠使用 glob 和 grep 搜索記憶是一個很好的起點,但在某些情況下,允許 Agent 對其記憶進行語義搜索將提供一些增益。
--不同層級的記憶
目前,所有記憶都是針對特定 Agent 的。我們要引入用户級 (user-level) 或組織級 (org-level) 記憶的概念。我們計劃通過向 Agent 暴露代表這些類型記憶的特定目錄,並提示 Agent 相應地使用和更新這些記憶來實現這一點。
6️⃣結論
如果構建擁有記憶的 Agent 聽起來很有趣,請嘗試 LangSmith Agent Builder。如果你想幫助我們構建這個記憶系統,我們正在招聘。
