一篇挺有意思的論文,專門討論了人類和大語言模型(LLM)在判斷方式上的差別。
論文原文:osf.io/preprints/psyarxiv/c5gh8_v1

論文指出,在 “怎麼知道、怎麼做判斷” 這件事上,人和 LLM 其實有很大不同。雖然 LLM 給出的答案常常看起來和人類的判斷很像,但這種 “像” 只是表面,背後的判斷機制完全不是一回事。
回顧 AI 的發展,從最早依靠規則和推理的 “符號 AI”,到後來按關鍵詞篩選信息的系統,再到現在這種大規模生成式的 Transformer 模型,LLM 其實並不是那種 “理解了再形成觀點” 的存在。它更像是在龐大的語料庫中學會了語言的規律,然後在上下文裏 “補全” 下一句話。用稍微技術一點但也直觀的説法,LLM 的工作方式更像是在一個高維的 “詞語連接網絡” 裏,根據概率選出下一個詞,而不是像人那樣基於對世界的信念來做判斷。
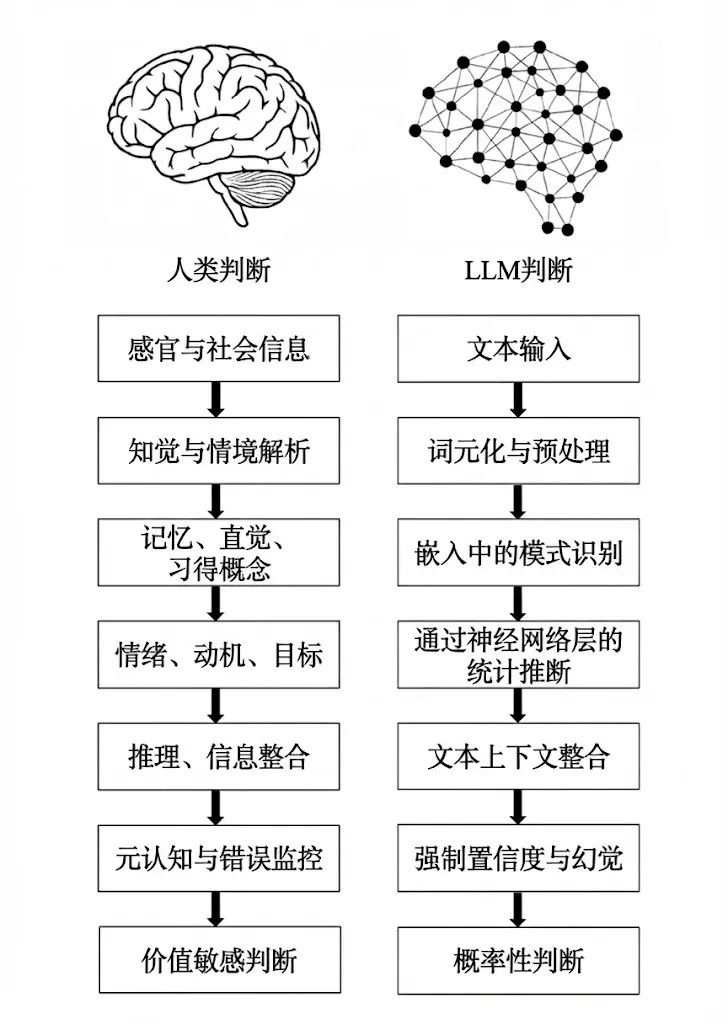
論文裏,兩位作者把人類和 LLM 的判斷流程逐項對比,發現兩者在七個關鍵環節上有着根本的區別:
1. 紮根斷層:人類的判斷是建立在感官、身體體驗和社會經驗之上的,而 LLM 只能靠文本,通過符號間接地 “重建” 意義。
2. 解析斷層:人類理解場景是通過整合感知和概念,LLM 則是把文本分詞、標記,得到的結構雖然方便處理,但語義其實很單薄。
3. 經驗斷層:人類靠情景記憶、直覺物理、心理和習得概念來判斷,LLM 只能依賴嵌入(embeddings)裏編碼的統計關聯。
4. 動機斷層:人類受情緒、目標、價值觀和進化動機影響,LLM 則沒有內在偏好、目標或情感。
5. 因果斷層:人類善於用因果模型、反事實推理來思考,LLM 不會主動構建因果解釋,而是傾向於用表層的相關性來 “拼接” 答案。
6. 元認知斷層:人類可以發現自己的不確定、修正錯誤,甚至暫停判斷,LLM 沒有元認知,必須不斷輸出內容,這也是 “幻覺” 難以避免的根本原因之一。
7. 價值斷層:人類的判斷會反映身份認同、道德和現實利害關係,LLM 只是在預測下一個詞,沒有真正的價值判斷或責任感。
作者還提到,儘管有這些斷層,大家還是很容易被 LLM 的流暢和自信所 “説服”,從而產生過度信任。這背後其實是一種 “可信度偏差”,也就是用漂亮的語言包裝出來的東西看起來就更可信。
他們把這種現象稱為 Epistemia(一種認識幻象或語言性認知錯覺):我們經常會被語言的流暢性誤導,以為自己已經 “知道了”,但其實本質上並沒有真正理解。
針對 Epistemia,論文還提出了三種應對策略:認識性評估(epistemic evaluation)、認識性治理(epistemic governance)和認識性素養(epistemic literacy)。
來源:https://weibo.com/2192828333/QjQJM4J22
