一、新聞
先播放一條最新新聞,通義團隊官宣開源了兩個智能體Alias-Agent和Data-Juicer Agent。
Alias-Agent提供了RaAct,Planner,DeepResearch三種模式,以實現靈活的任務執行。
DataJuicer 智能體是一個數據專員,由數據處理智能體,代碼開發智能體,MCP 智能體,數據分析與可視化智能體,問答智能體五個智能體組成。
看到這裏已經相當炸裂了!可能很多夥伴對智能體(Agent)的範式不熟悉,還不理解ReAct、Planner、反思叭叭這些名詞。那你們就來對了地方,我用最容易理解的方式帶大家一起看下智能體內部是什麼樣子的。
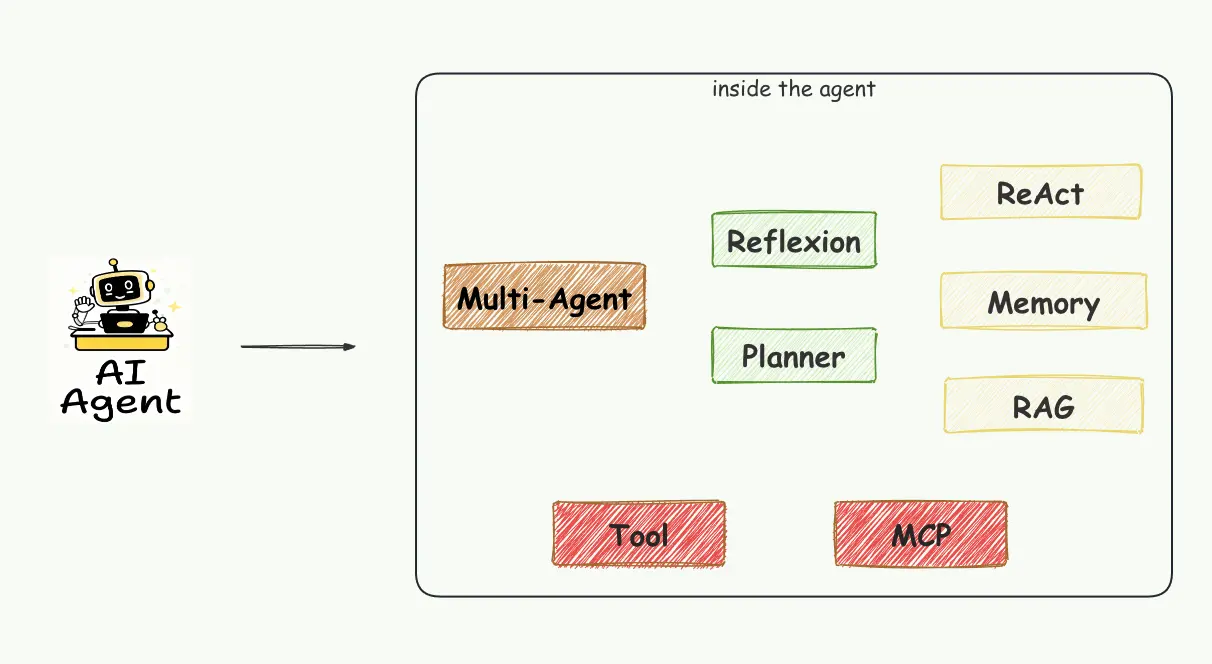
產品化的智能體由多Agent,反思,計劃,推理與行動,記憶,RAG,工具,MCP組成的。首先聊下“Multi-Agent”,它非常好玩!
二、Multi-Agent 的7種設計模式
要讓AI代替人工作,現階段的單體智能體(僅通過系統提示詞賦能的LLM)是很難實現的。我們很快意識到,要構建高效的系統,需要多個專業化智能體協同工作、自主組織。為實現這一目標,AI 智能體領域已涌現出多種架構模式。多個智能體組成實現的,也就是Multi-Agent,發展到現在有7種實現方式。
1. 工作流模式

在《Agentic Design Patterns》中叫Prompt Chaining,每個智能體都逐步地完成輸出,比如一個生成代碼,另一個審核代碼,第三個部署代碼。每一步的輸出作為下一步的輸入。這種信息傳遞建立了依賴鏈,前序操作的上下文和結果會引導後續處理,使 LLM 能夠在前一步基礎上不斷完善理解,逐步逼近目標解。
他非常適合應用在工作流自動化、ETL和多步驟推理pipeline場景。
2. 路由模式

路由模式為智能體的操作框架引入了條件邏輯,使其從固定執行路徑轉變為動態評估標準,從一組可能的後續動作中進行選擇的模式,從而實現一套更靈活,並且具備上下文感知的。一個控制器智能體將任務分配給合適的專業智能體,這是上下文感知智能體路由的基礎,正如在MCP、A2A框架中所看到的那樣。
路由模式的實現有四種:
""" 偽代碼示例 """
router = ReActAgent(
name="Router",
sys_prompt="#角色#你是一個路由智能體。你的目標是將用户查詢路由到正確的後續任務,注意你不需要回答用户的問題。
#任務#選擇正確的後續任務,如果任務太簡單或沒有合適的任務,則選擇 ``None``",
model=ChatModel(
model_name="gpt-4",
api_key="",
stream=False,
)
)
根據Embedding路由,利用嵌入能力,將查詢路由到最相似的路徑上,適用於語義路由,即決策基於輸入的含義而非關鍵詞。
""" 偽代碼示例 """
def __init__(self):
# 使用輕量級的句子編碼模型
self.model = ChatModel( model_name="gpt-4", api_key="", stream=False, )
# 定義不同的路由能力和對應的處理函數
self.routes = {
'code_help': {
'description': '編程,代碼',
'handler': self.handle_code_question
},
'general_chat': {
'description': '聊天,日常對話',
'handler': self.handle_general_chat
}
}
# 預計算所有路由描述的嵌入向量
self.route_embeddings = {}
for route_name, route_info in self.routes.items():
embedding = self.model.encode([route_info['description']])
self.route_embeddings[route_name] = embedding
def route_query(self, user_question):
# 1. 將用户問題轉換為嵌入向量
question_embedding = self.model.encode([user_question])
# 2. 使用餘弦計算與各個路由的相似度
similarities = {}
for route_name, route_embedding in self.route_embeddings.items():
similarity = cosine_similarity(question_embedding, route_embedding)[0][0]
similarities[route_name] = similarity
# 3. 選擇相似度最高的路由
best_route = max(similarities, key=similarities.get)
best_score = similarities[best_route]
# 4. 調用對應的處理器
handler = self.routes[best_route]['handler']
response = handler(user_question)
return {
'route': best_route,
'confidence': best_score,
'response': response
}
....
3. 並行模式

每個智能體負責處理不同的子任務,例如數據爬蟲、網絡檢索和摘要生成,它們的輸出會合併為一個單一結果。非常適合減少高吞吐量管道中的延遲。(如文檔解析或API編排)
4. 循環模式

智能體不斷優化自身輸出,直到達到預期質量。非常適合校對、報告生成或創意迭代,在這些場景中,系統會在確定最終結果前再次思考。反思就是在此模式上進行的優化。
5. 聚合模式

許多智能體生成部分結果,由主智能體將這些結果整合為一個最終輸出。因此,每個智能體都形成一個觀點,而一個Master智能體將這些觀點彙總成共識。在RAG的檢索融合、投票系統等場景中很常見。
6. 網絡模式

這裏沒有明確的層級結構,智能體之間可以自由交流,動態共享上下文。用於模擬、多智能體遊戲以及需要自由形式行為的集體推理系統中。agentscope-samples ,模擬了9個智能體的狼人殺遊戲。
7. 層級模式

一個頂級規劃智能體,將子任務分配給工作智能體,跟蹤它們的進度,並做出最終決策。這和經理及其團隊的工作方式完全一樣(很多中間件的架構也是類似這種模式如Redis、ES、Nocas)。意圖識別就是採用此模式。
小節:
我們一直在思考的一件事,不是哪種模式看起來最酷,而是哪種模式能最大限度地減少智能體之間的摩擦。啓動10個智能體並稱之為一個團隊很容易。難的是設計溝通流程,以確保:沒有兩個智能體會做重複工作。每個智能體都知道何時行動何時等待,使這個系統作為一個整體,比其任何單個部分都更智能。為此我們遵循 building-effective-agents 設計。
三、Multi-Agent 框架
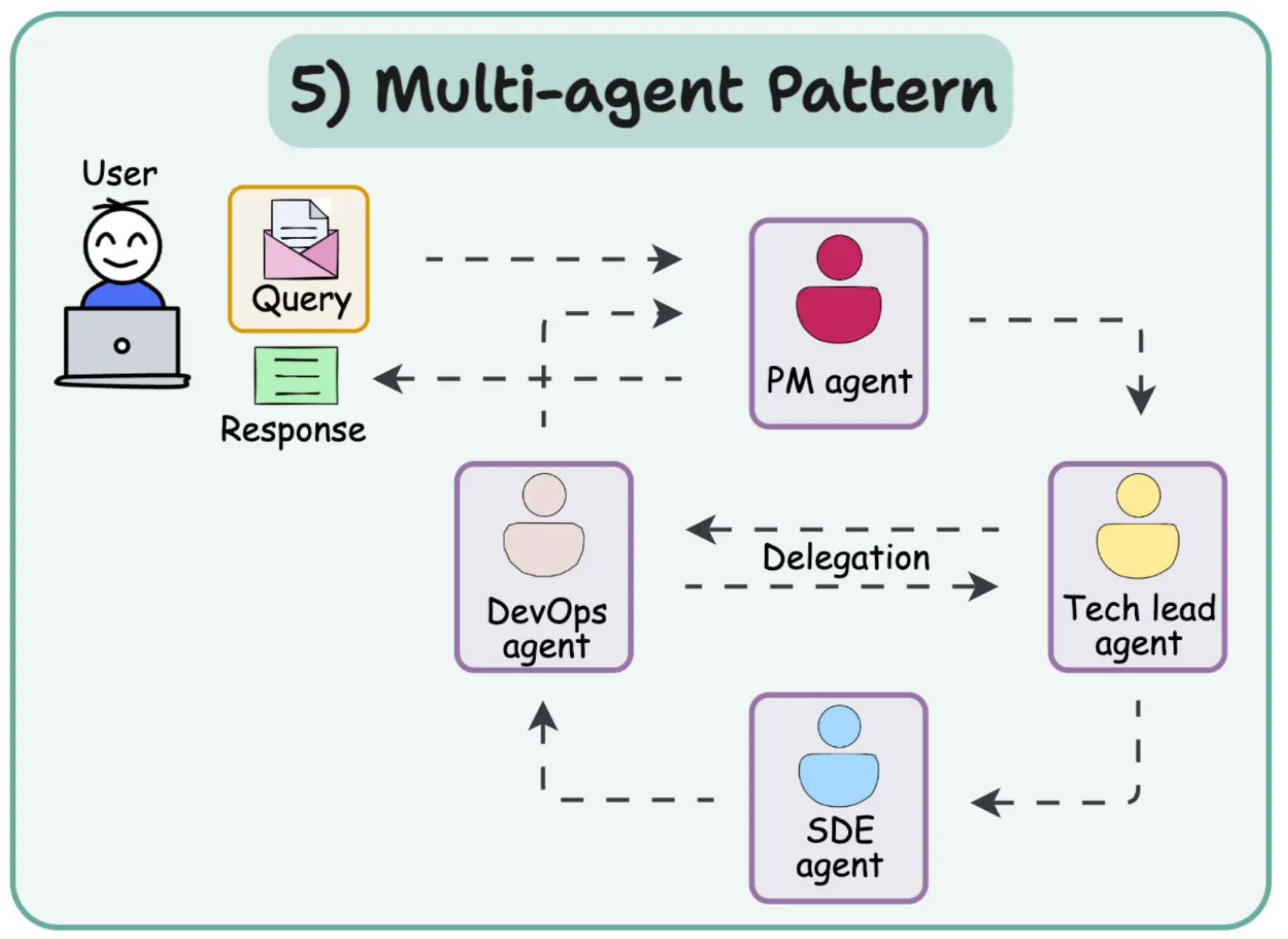
多智能體模式將人工智能工作流構建為一個智能體團隊,它們相互協作,每個智能體都有明確的角色。每個智能體能夠感知輸入、進行推理(通過思維鏈)並執行操作以完成子任務。每個智能體通常都配置有特定角色,並且只能訪問該角色所需的工具或信息。例如,PM AGent負責需求判斷是否需要其他智能體參與,若需要技術決策則聯動Tech lead agent。智能體將循環進行思考(“思考……”)和行動(“行動……”),直到完成其工作部分的任務。如下圖
以上簡單介紹了多智能體的設計模式,那麼當下是不是已經有了成熟的架構供我們使用呢?答案是肯定的!
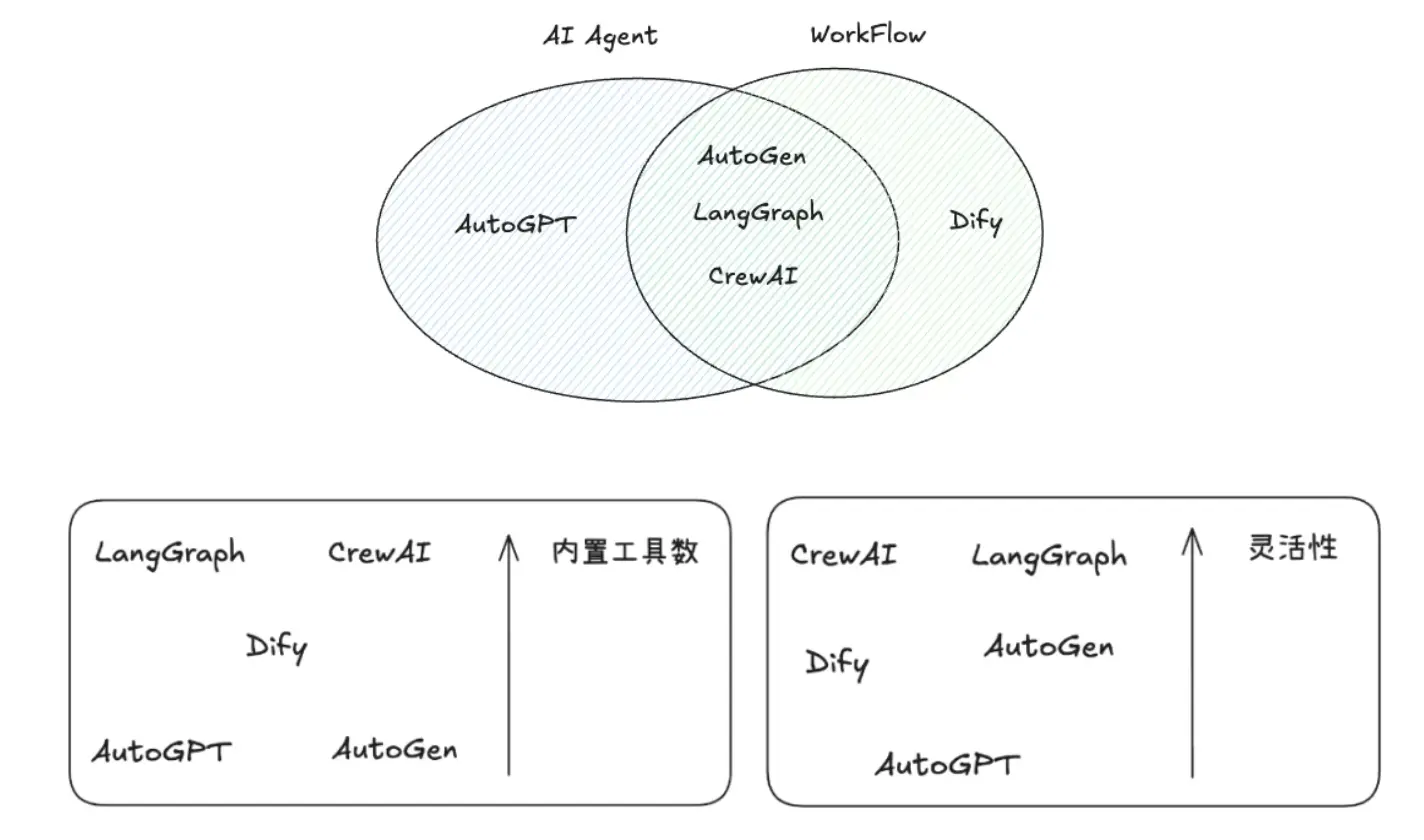
1.AutoGPT:Github 180k Star
2.Dify: Github 118k Star
3.AutoGen: Github 51.4k Star
4.CrewAI:Github 40.1k Star
5.LangGraph: Github 20.6k Star
為什麼需要使用Agent框架?
只要“問題不可完全窮舉、要跨多系統查證、並且需要在對話中澄清、協商、決策”,就更應該用 Agent 框架,而不是純 Workflow。
純 Workflow 的“天花板”
Workflow 在對話中的“澄清—再決策—再行動” 並不天然友好,需要把每一步提問、回答、重試都畫成節點,複雜而脆弱。
場景:用户發起:“我的包裹還沒到,怎麼辦?”
通過Workflow創建如下智能體:(先不期待GPT-6 會自主思考的智能體)
智能體數量✖️物流狀態✖️用户等級✖️物流政策....你的分支會爆炸。所以需要用Dify這類的可以支持動態決策,動態推理和澄清的智能體框架。
Agent 框架解決的核心問題
以 AutoGen、CrewAI 這類 Agent 框架為例,它們把“在對話裏動態規劃與調用工具”作為第一性能力:
場景:用户説“我10.1買的手機現在還沒到,給我退貨!另外,你們的運費險的保賬期是多久?”
一個合格的客服 Agent 團隊會做什麼?
沒有路由決策,首先會動態匹配所有Query,對Query進行改寫成“查詢用户的訂單”,“用户想要退貨”,“運費險的保賬範圍和條款”。
Policy Agent:套用“假期延誤 + Plus + 運費險”的組合條款,評估可給的補償區間、是否觸發風控人工複核。
這些動作裏,很多步驟無法事先“畫”成固定分支,需要在對話上下文裏做決策、需要跨工具動態組合、需要“問一句 → 查一下 → 再決定”,這正是 Agent 的強項。
結尾:
以上是對多智能體的總結,你會了嗎?
