深度求索剛剛發佈最新開源模型: DeepSeek-OCR 2,引入了全新的 DeepEncoder V2 視覺編碼器。該編碼器的架構打破了傳統模型按固定順序(從左上到右下)掃描圖像的限制,轉而模仿人類視覺的「因果流(Causal Flow)」邏輯。

項目地址:https://github.com/deepseek-ai/DeepSeek-OCR-2
模型下載:https://huggingface.co/deepseek-ai/DeepSeek-OCR-2
論文地址:https://github.com/deepseek-ai/DeepSeek-OCR-2/blob/main/DeepSeek_OCR2_paper.pdf
據介紹,DeepEncoder V2 讓 AI 基於圖像含義動態重新排列圖像片段,而非傳統的從左到右剛性掃描。這種方法模仿了人類追隨場景邏輯流的方式。
傳統的 VLMs 通常按固定的光柵掃描順序(從左上到右下)處理圖像,這種僵化的方式不符合我們的視覺感知,人類是基於內容的靈活掃描,而且在處理複雜佈局,如表格、公式、多欄文本時會引入錯誤的信息。
而 OCR 2,就是利用新型編碼器 DeepEncoder V2,給了模型「視覺因果流 Visual Causal Flow」的能力,讓模型能夠根據圖像內容,動態地重新排序視覺 Token。
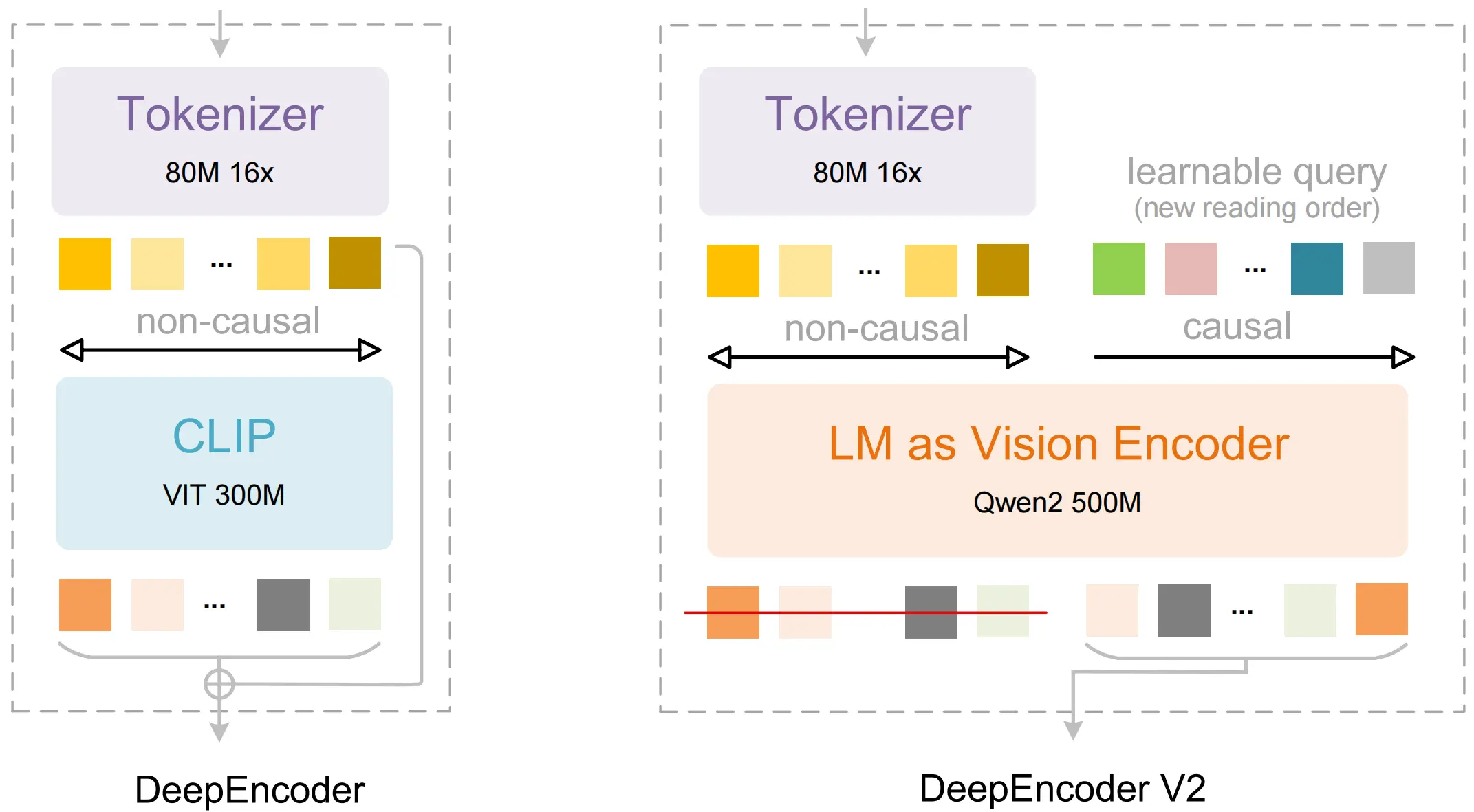
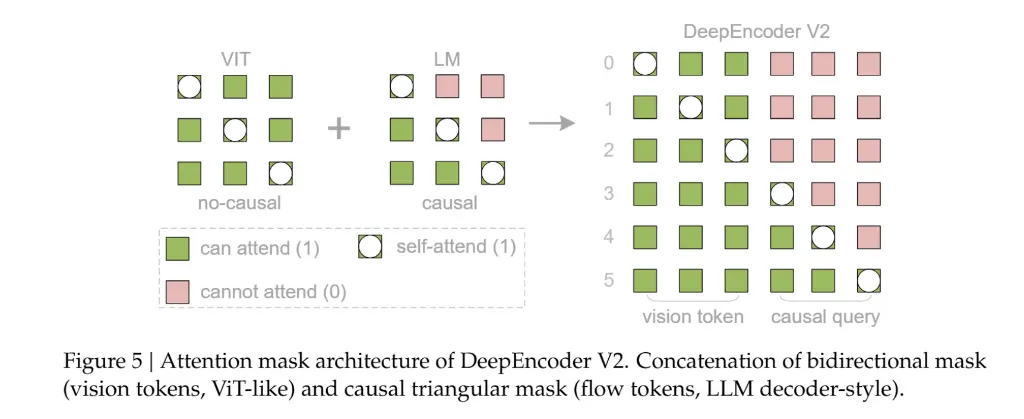
該架構採用了一種定製化的注意力掩碼(Attention Mask)策略:
- 視覺 Token 部分:保留雙向注意力機制,確保模型能夠像CLIP一樣擁有全局感受野,捕捉圖像的整體特徵。
- 因果流 Token 部分:採用因果注意力機制(類似 Decoder-only LLM),每個查詢 Token 只能關注之前的 Token。
通過這種設計,視覺 Token 保持了信息的全局交互,而因果流 Token 則獲得了重排序視覺信息的能力。DeepSeek-OCR 2 採用了多裁剪策略(Multi-crop strategy),根據圖像分辨率不同,最終輸入 LLM 的重排序視覺 Token 總數在 256 到 1120 之間。
DeepSeek 團隊認為,這為邁向統一的全模態編碼器提供了一條有希望的路徑。未來,單一編碼器可能通過配置特定模態的可學習查詢,在同一參數空間內實現對圖像、音頻和文本的特徵提取與壓縮。DeepSeek-OCR 2所 展示的“兩個級聯的 1D 因果推理器”模式,通過將 2D 理解分解為“閲讀邏輯推理”和“視覺任務推理”兩個互補子任務,或許代表了實現真正 2D 推理的一種突破性架構方法。
相關閲讀
DeepSeek 團隊發佈最新開源模型 DeepSeek-OCR
由 DeepSeek-OCR 啓發的新思路:所有輸入給 LLM 的內容都只應該是圖像
