美團 LongCat 團隊對外發布並開源 LongCat-Flash-Thinking-2601,同步開放模型權重、推理代碼與在線體驗能力。
根據介紹,作為已發佈的 LongCat-Flash-Thinking 模型的升級版,LongCat-Flash-Thinking-2601在Agentic Search(智能體搜索)、Agentic Tool Use(智能體工具調用)、TIR(工具交互推理)等核心評測基準上,均達到開源模型 SOTA 水平。
該模型尤其在工具調用上表現出卓越的泛化能力,在依賴工具調用的隨機複雜任務中性能超越了 Claude,可大幅度降低真實場景下新工具的適配訓練成本;同時它是首個完整開源並支持在線免費體驗「重思考模式」的模型,同時啓動 8 個大腦飛速運轉,確保思考周全、決策可靠。
模型會把思考過程拆成並行思考和總結歸納兩步來做:
- 並行思考階段,模型會同時獨立梳理出好幾條推理路徑,就跟人面對難題時會琢磨不同解法一個道理,還會特意保證思路的多樣性,生怕漏掉最優解;
- 總結歸納階段,對多條路徑進行梳理、優化與合成,並將優化結果重新輸入,形成閉環迭代推理,推動思考持續深化。
除此之外,項目團隊還專門設計了額外的強化學習環節,針對性打磨模型的總結歸納能力,讓 LongCat-Flash-Thinking-2601 真正實現“想清楚再行動”。
評測結果顯示,LongCat-Flash-Thinking-2601 模型在編程、數學推理、智能體工具調用、智能體搜索維度表現全面領先:
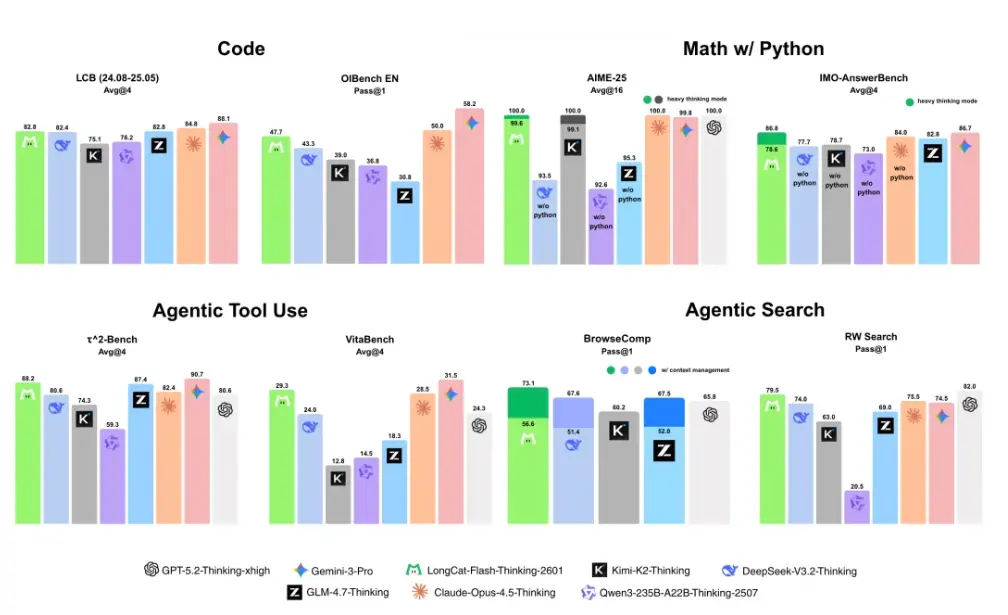
- 編程能力:LongCat-Flash-Thinking-2601 在 LCB 評測中取得 82.8 分,OIBench EN 評測獲 47.7 分,成績處於同類模型第一梯隊,展現出紮實的代碼基礎能力。
- 數學推理能力:在開啓重思考模式後表現突出,LongCat-Flash-Thinking-2601 在 AIME-25 評測中獲 100.0 分(滿分),IMO-AnswerBench 中以 86.8 分達到當前 SOTA。
- 智能體工具調用能力:在 τ²-Bench 評測中拿到 88.2 分,VitaBench 評測中獲得 29.3 分,均獲得開源 SOTA 水平,在多領域工具調用場景下表現優異,適配實際應用需求。
-
智能體搜索能力:在 BrowseComp 任務中取得 73.1 分(全模型最優),RW Search 評測獲 79.5 分,LongCat-Flash-Thinking-2601 具備強勁的信息檢索與場景適配能力,達到開源領先水平。
