字節跳動 Seed 團隊發佈最新研究成果 GR-RL,着力於拓展 VLA 模型在長時程精細靈巧操作方面的能力邊界。

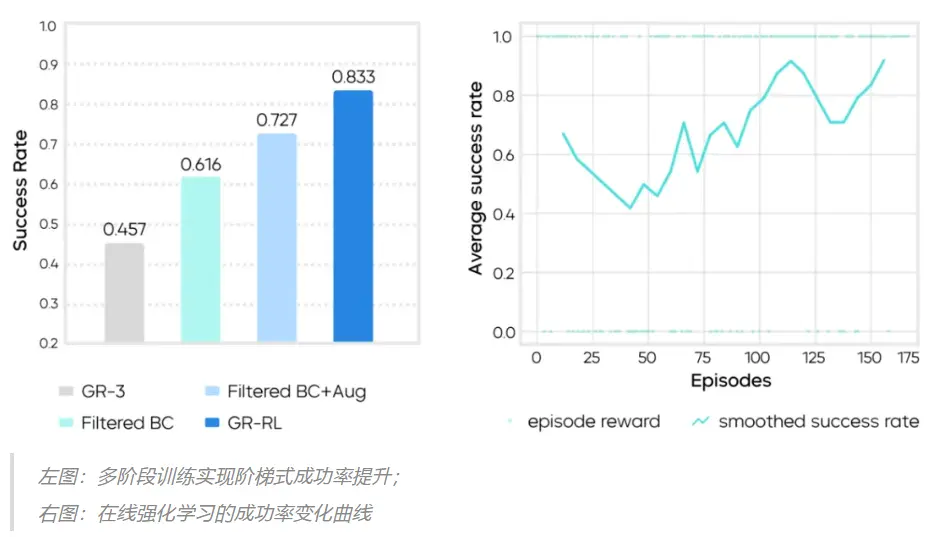
GR-RL 提出了一套從離線數據篩選到在線真機微調的強化學習框架,在業界首次實現“讓機器人給整隻鞋連續穿鞋帶”。相較前作監督學習模型 GR-3,GR-RL 在穿鞋帶任務上將成功率從 45.7% 提升至 83.3%,減少了近 70% 的失敗情況。
根據介紹,在原有的 VLA 基礎上,GR-RL 引入了一個額外的判別器網絡(Critic Transformer),用於衡量機器人動作的質量,對動作序列中每個時刻的動作都進行一次打分。具體而言,GR-RL 採用了值分佈強化學習,將判別器輸出假設為一個離散概率分佈,以更魯棒地捕捉真實環境中存在的噪聲。

基於此架構,GR-RL 設計了一套從經驗中篩選、在實踐中進化的多階段訓練框架。該框架包含三個核心環節:離線強化學習、數據增強以及在線強化學習。
在雙臂輪式機器人 ByteMini-v2 上,團隊基於“穿鞋帶”任務對 GR-RL 進行了全流程驗證。該機器人配備了獨特的球形腕部關節設計,能夠像人類手腕一樣靈活轉動,在精細靈巧任務中獨具優勢。
實驗結果表明,純模仿學習基線(GR-3)的成功率僅為 45.7%,難以應對精細操作。GR-RL 通過多階段訓練框架實現了性能的階梯式跨越,三個核心組件都對成功率的提升有重要貢獻:
- 數據過濾:剔除次優數據後,離線數據過濾將成功率提升至 61.6%;
- 數據增強:引入鏡像數據擴充,成功率可提升至 72.7%;
- 在線強化學習:以增強後的離線學習模型作為在線強化學習的起點,經過約 150 條軌跡的真機閉環探索與修正,GR-RL 的成功率最終上升至 83.3%。