Mistral AI 宣佈開源 Mistral3 系列模型,包括3B、8B、14B 三個小型密集模型及迄今為止功能最強大的 Mistral Large3,一款稀疏混合專家模型,使用 410 億個活躍參數和 6750 億個總參數進行訓練。所有模型均以 Apache 2.0 許可證發佈,覆蓋從邊緣設備到企業級推理的全場景需求。
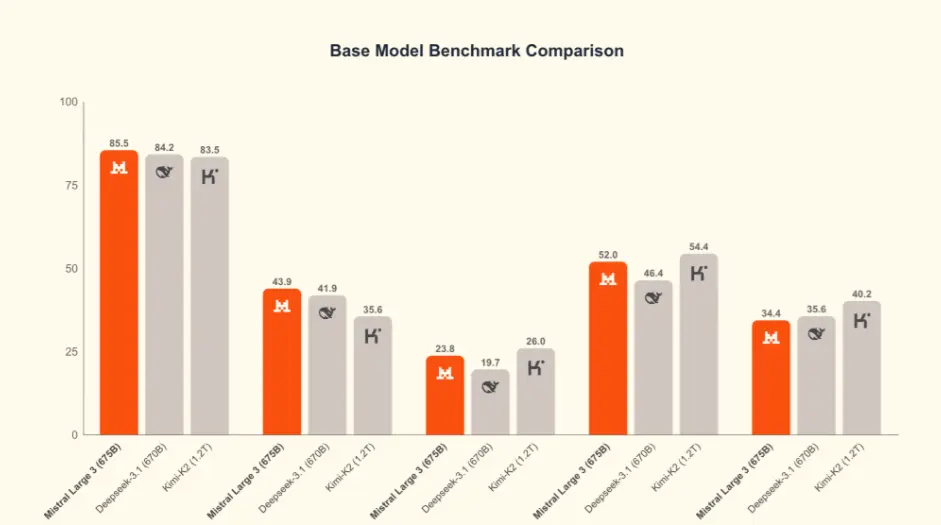
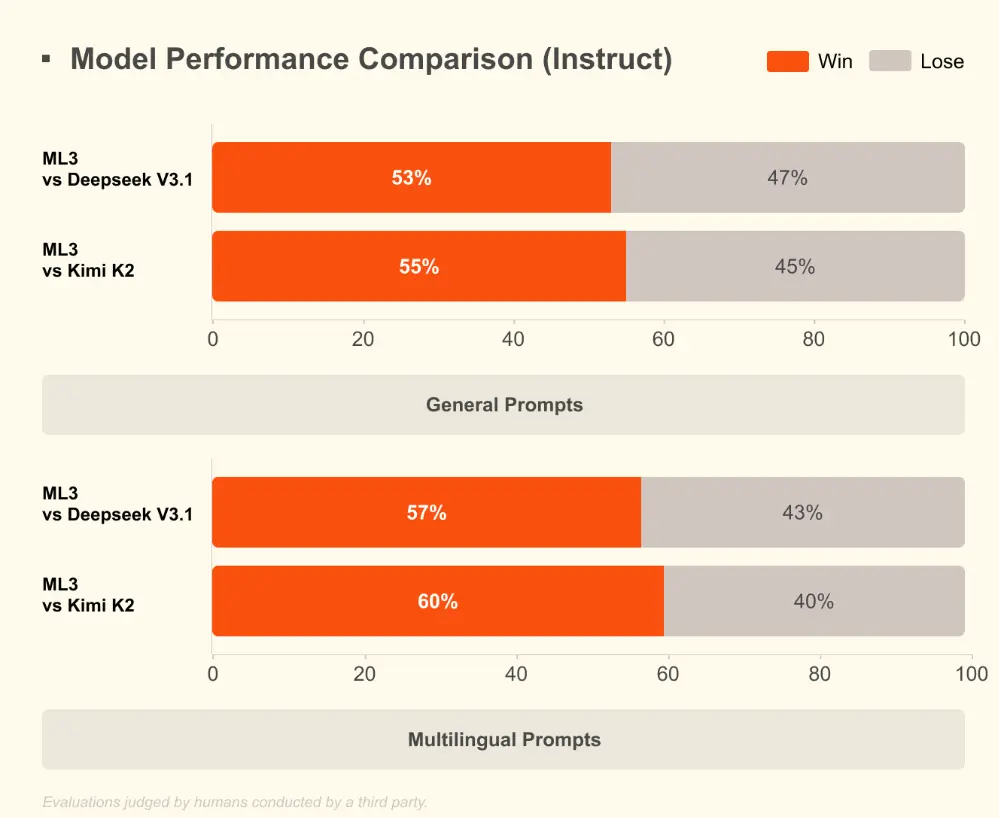
公告稱,Mistral Large 3 是目前世界上最好的開放權重模型之一,它完全基於 NVIDIA 的 3000 個 H200 GPU 從零開始訓練而成。Mistral Large 3 是 Mistral 自開創性的 Mixtral 系列以來推出的首個專家混合模型,代表了 Mistral 在預訓練方面的重大進步。經過後訓練,該模型在通用提示上的表現與市面上最好的指令調優開放權重模型不相上下,同時還展現出卓越的圖像理解能力,並在多語言對話(例如,非英語/中文)方面取得了一流的性能。

Mistral Large 3 與 vLLM 和 Red Hat 協同工作,對開源社區非常友好。Mistral AI 發佈了一個使用llm-compressor構建的 NVFP4 格式的 checkpoint。這個優化後的 checkpoint 使用户能夠在 Blackwell NVL72 系統以及使用vLLM 的單個 8×A100 或 8×H100 節點上高效運行 Mistral Large 3 。
所有的全新 Mistral 3 模型,從 Large 3 到 Ministral 3,均在 NVIDIA Hopper GPU 上進行訓練,以充分利用高帶寬 HBM3e 內存來處理前沿規模的工作負載。NVIDIA 工程師為整個 Mistral 3 系列模型啓用了對TensorRT-LLM和SGLang 的高效推理支持,從而實現高效的低精度執行。
針對 Large 3 的稀疏 MoE 架構,NVIDIA 集成了最先進的 Blackwell 注意力機制和 MoE 內核,增加了對預填充/解碼解耦服務的支持,並與 Mistral 合作開發了推測性解碼,使開發者能夠在 GB200 NVL72 及更高級別的設備上高效地處理長上下文、高吞吐量的工作負載。在邊緣端,NVIDIA 提供了在DGX Spark、RTX PC 和筆記本電腦以及Jetson 設備上優化部署 Ministral 模型的方案,為開發者提供了一條從數據中心到機器人運行這些開放模型的一致且高性能的路徑。

Mistral AI 聲稱,Ministral 3 在所有開源軟件模型中實現了最佳的性價比。在實際應用場景中,生成的 token 數量和模型大小同樣重要。Ministral 指令模型在性能上與同類模型持平甚至更勝一籌,同時生成的 token 數量通常卻少一個數量級。
目前,Mistral Large3已在公司官方平台 Le Platforme 上線 API,定價為每百萬 token 輸入0.8美元、輸出2.4美元,約為 GPT-4o 的一半,並支持微調與私有部署。
更多詳情可查看官方公告:https://mistral.ai/news/mistral-3
