谷歌 DeepMind 最新發布了名為 D4RT(Dynamic 4D Reconstruction and Tracking)的 AI 模型,突破了傳統 AI 對視頻感知的限制,使機器能夠像人類一樣“看到”並理解動態世界——不僅是空間的 3 維,還包括時間這一第四維度。
據介紹,D4RT 是一個統一、高效的 AI 模型,能夠從普通 2D 視頻中重建 3D 場景和物體隨時間的運動軌跡。傳統技術通常需要多個獨立組件分別處理深度估計、運動跟蹤、相機位姿等任務,這不僅複雜且運算量大。D4RT 則將這些功能整合到一個 Transformer 架構中,通過一種靈活的查詢機制統一完成。
其核心思想是:
系統可以被問一個關鍵問題——某個像素在某一時刻、某一視角下的 3D 位置在哪裏?
然後通過高效的查詢機制快速給出答案。
D4RT 的表現遠超現有方法:
-
通過統一的架構和並行查詢處理,它在多個 4D 場景重建任務中表現優異。
-
在標準數據集上,它比傳統技術快 18× 到 300×,例如處理 1 分鐘視頻只需約 5 秒(而以前的模型可能需要數分鐘)。
-
即使當物體暫時被遮擋或離開畫面,D4RT 也能準確預測其運動軌跡。
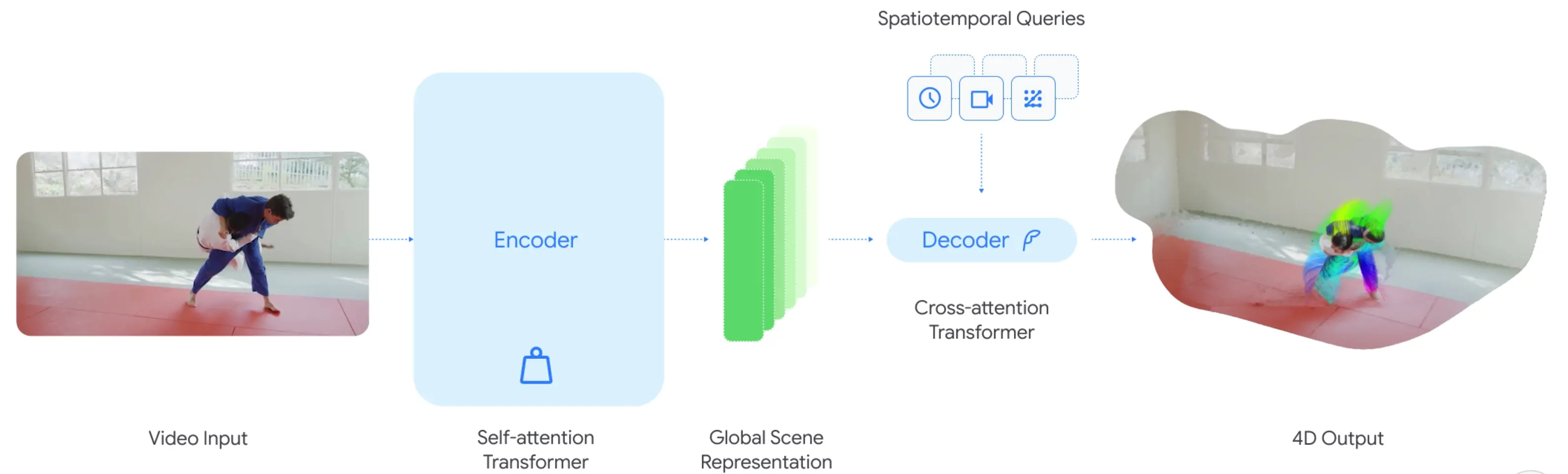
D4RT 不僅是理論模型,還具備實際應用價值:
- 點追蹤(Point Tracking):可從視頻中追蹤像素在 3D 空間中隨時間的移動軌跡。
- 點雲重建(Point Cloud Reconstruction):能在任意時間下生成完整的 3D 結構。
- 相機位姿估計(Camera Pose Estimation):重建相機路徑和姿態,無需額外外部信息。
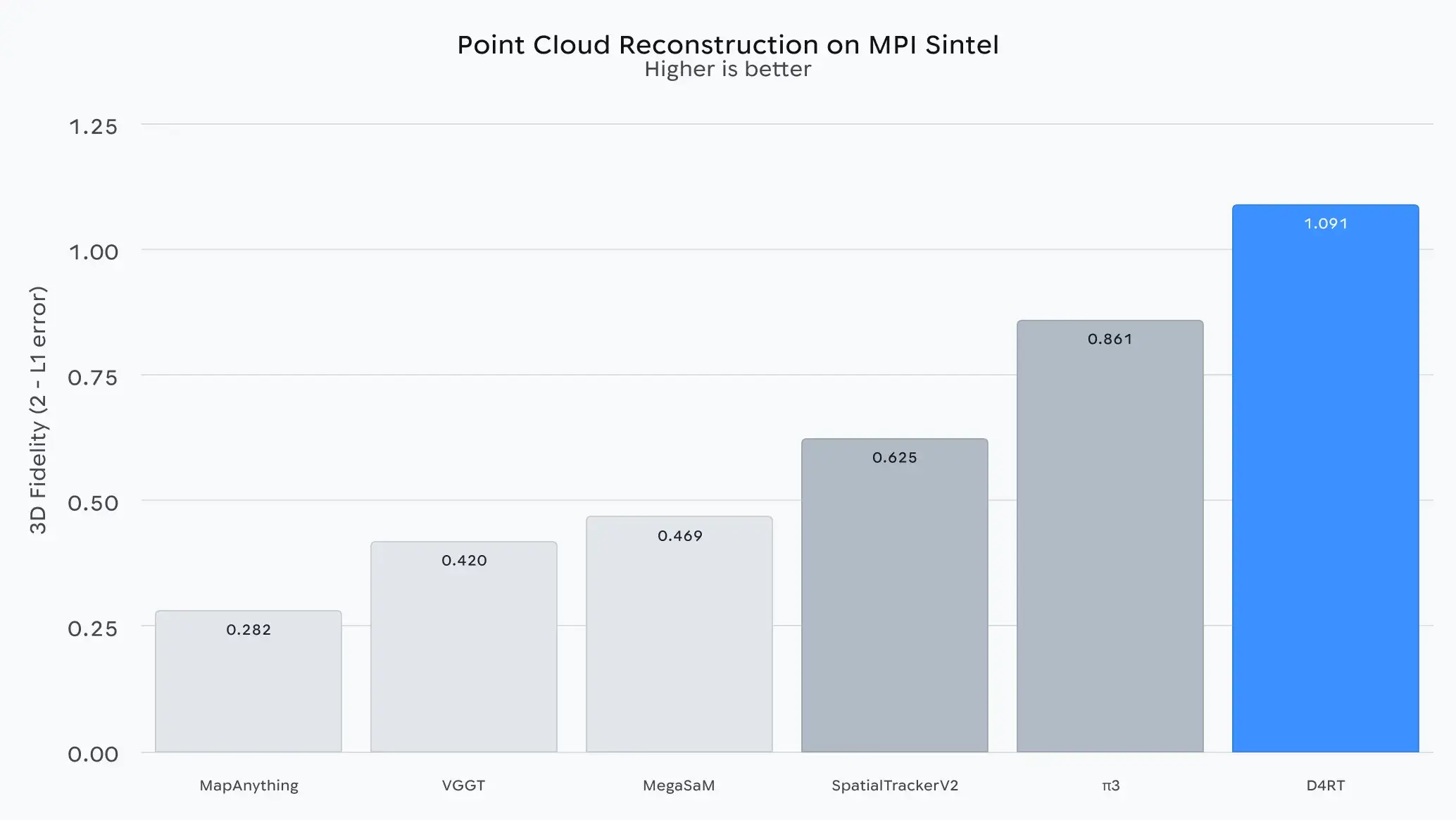
D4RT 的技術突破不僅提升了 4D 場景理解的速度與準確性,還意味着 AI 系統可以更接近真實世界感知能力:
- 機器人:實時感知動態環境,有助於導航與操作。
- 增強現實(AR):可為 AR 設備提供低延遲、精確的空間理解。
- “世界模型”:幫助 AI 更好地理解物體、相機與時間之間的關係,是通向更高級智能的一步。
谷歌 DeepMind 表示,D4RT 將視覺理解從傳統的二維視頻分析推進到了真正的“四維時空感知”。其統一而高效的架構不僅突破了性能瓶頸,還在真實應用場景中展現出強大潛力,為下一代智能機器感知動態現實奠定了基礎。
