阿里通義實驗室推出 Qwen-Image-i2L,能將任意單張圖片瞬間轉化為可微調的LoRA(Low-Rank Adaptation)模型。

無需海量數據集或昂貴計算資源,用户只需上傳一張圖片,即可生成輕量級LoRA模塊,並無縫集成到其他生成模型中,實現高效的“單圖風格遷移”。
Qwen-Image-i2L的核心在於其獨特的圖像分解機制。它採用SigLIP2、DINOv3和Qwen-VL等多模態特徵提取體系,將輸入圖片智能拆解為“風格、內容、構圖、色調”等核心視覺元素。這些可學習特徵隨後被高效壓縮,形成一個體積小巧的LoRA模塊——平均僅需數GB空間,卻能捕捉圖片的精髓。
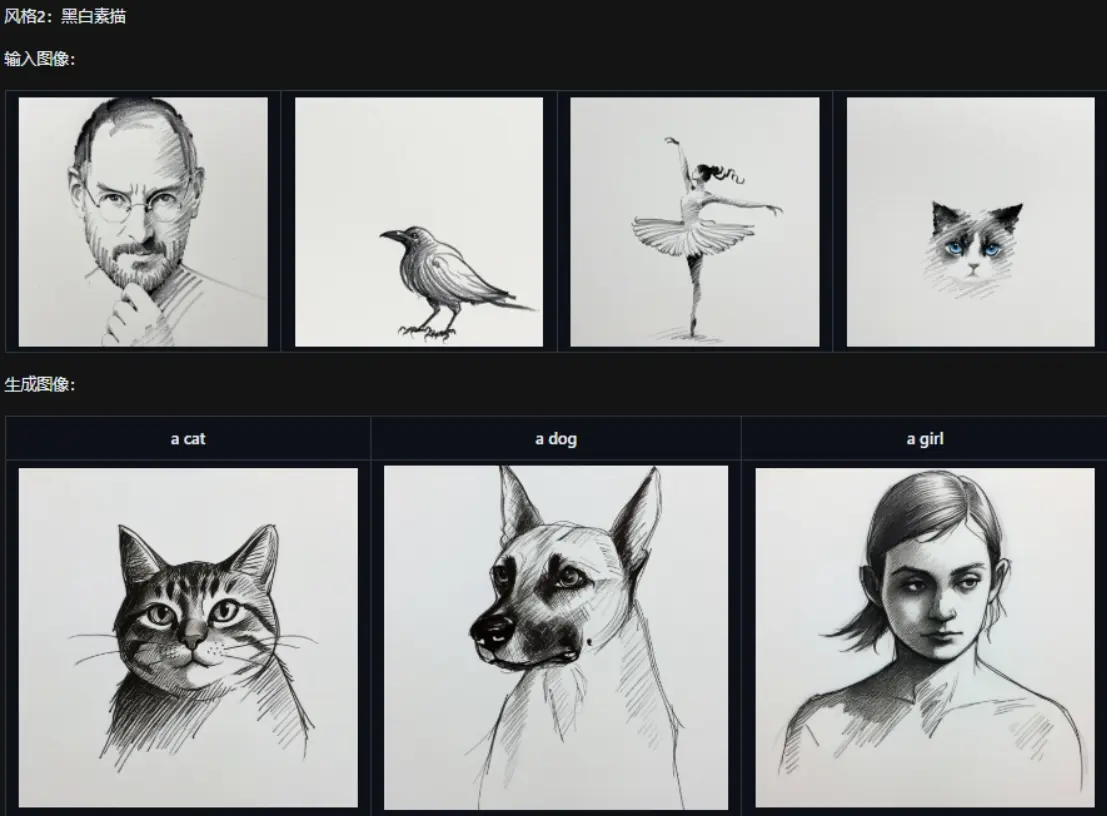
為滿足不同需求,Qwen-Image-i2L提供了四種專屬“模型風格”,每個變體針對特定用途優化:
- 風格模式(2.4B參數):專注純美學提取,理想用於藝術畫風遷移,如將水彩風格注入新圖像。
- 粗粒度模式(7.9B參數):綜合捕捉內容與風格,適合整體場景重構,例如建築或景觀的快速變體生成。
- 精細模式(7.6B參數):支持1024x1024高分辨率細節增強,常與粗粒度模式搭配,提升紋理和邊緣精度。
- 偏見模式(30M參數):確保輸出與Qwen-Image原生風格一致,避免偏差,適用於需要品牌統一性的企業級應用。
這些變體均基於Apache2.0許可開源,測試顯示,在複雜文本渲染和語義編輯基準上,Qwen-Image-i2L超越多數開源競品,與閉源模型不相上下。
