編者按: 當大模型的算力需求呈指數級增長,GPU 還是唯一答案嗎?在 AI 硬件軍備競賽愈演愈烈的今天,是否存在更高效、更專精、甚至更具顛覆性的替代方案?
我們今天為大家帶來的文章,作者的核心觀點是:AI 硬件生態正在迅速多元化,除了廣為人知的 CPU、GPU 和 TPU 之外,一系列新興架構 ------ 如 ASIC、NPU、IPU、FPGA 乃至存內計算與神經形態芯片,正從不同維度重塑 AI 的算力未來。
文章系統梳理了三大經典處理單元(CPU、GPU、TPU)的原理與侷限,並深入剖析了包括 Cerebras 晶圓級引擎、AWS Trainium/Inferentia、AMD APU、NPU 在內的專用芯片設計思路;進而拓展至 IPU、RPU、FPGA 等前沿架構,揭示它們如何針對稀疏計算、圖神經網絡、邊緣推理或存算一體等特定場景提供突破性性能。
作者 | Ksenia Se and Alyona Vert
編譯 | 嶽揚
目錄
01 CPU、GPU、TPU -- 三種核心硬件架構
1.1 中央處理單元(Central Processing Unit, CPU)
1.2 圖形處理單元(Graphics Processing Unit, GPU)
1.3 張量處理單元(Tensor Processing Unit, TPU)
02 專用集成電路(Application-Specific Integrated Circuits, ASICs)
2.1 Cerebras 晶圓級引擎(Wafer-Scale Engine, WSE)
2.2 AWS Trainium 與 AWS Inferentia
2.3 加速處理單元(Accelerated Processing Unit, APU)
2.4 神經網絡處理單元(Neural Processing Unit, NPU)
03 其他有前景的替代架構
3.1 智能處理單元(Intelligence Processing Unit, IPU)
3.2 阻變處理單元(Resistive Processing Unit, RPU)
3.3 現場可編程門陣列(Field-Programmable Gate Arrays, FPGAs)
04 新興架構(Emerging Architectures)
4.1 量子處理器(Quantum Processors)
4.2 存內計算(Processing-in-Memory, PIM)與基於 MRAM 的芯片
4.3 神經形態芯片(Neuromorphic Chips)
05 結語(Conclusion)
如今連小孩子都知道 GPU(圖形處理單元)是什麼了 ------ 這得歸功於 AI,也歸功於英偉達(Nvidia),它始終在不遺餘力地推進自家芯片的發展。當然,硬件既是絆腳石,也是推動模型運行及其技術棧的引擎。但為什麼人們討論的焦點只集中在 GPU 上呢?難道沒有其他競爭者可能塑造 AI 硬件的未來嗎?CPU 和 TPU 當然算 ------ 但僅此而已嗎?
今天,讓我們跳出 GPU 的思維繭房,將視線拓展到 GPU、CPU、TPU 這"老三樣"之外。全球開發者一直在探索各類替代設計方案,每一種都承諾帶來可觀的效率提升和全新的創新路徑。
我們希望能各位讀者打造一份完整的 AI 硬件指南,因此先從這三大巨頭講起,再轉向那些雖不主流卻內有乾坤的方案:例如 Cerebras WSE 和 AWS 自研的定製 ASIC;還有 APU、NPU、IPU、RPU 以及 FPGA。我們會幫你釐清這些術語,讓你全面掌握 AI 硬件的完整圖景。這篇文章必將讓你收穫滿滿!
01 CPU、GPU、TPU -- 三種核心硬件架構
在探討其他替代方案之前,先來剖析一下這些我們耳熟能詳的 CPU、GPU 和 TPU 到底是什麼。
這三大巨頭都屬於處理單元(Processing Units,簡稱 PUs) ------ 即專門用於執行軟件程序指令、進行計算的電子電路。許多人稱它們為計算機系統的"大腦"。PUs 執行各類算術、邏輯、控制以及輸入/輸出操作,將原始數據處理成有用的信息。
不同類型的 PU 針對不同的工作負載進行了優化 →
1.1 中央處理單元(Central Processing Unit, CPU)
中央處理單元(CPU)專為通用計算和順序任務執行而設計。
CPU 是三者中最古老的。其前身的故事始於 1945 年 ------ 約翰·莫奇利(John Mauchly)與 J. 普雷斯珀·埃克特(J. Presper Eckert Jr.)推出了 ENIAC(Electronic Numerical Integrator and Computer)。這是世界上第一台可編程、電子式、通用型的數字計算機,能通過重新編程解決多種數值問題,使用了約 18,000 個真空管。
同年,約翰·馮·諾依曼(John von Neumann)發表了《First Draft of a Report on the EDVAC》,提出將數據和指令存儲在同一內存中。這一"存儲程序"模型成為現代 CPU 的設計藍本。
到了 1950 年代中期,真空管被晶體管取代。從那時起,處理器開始由大量基於晶體管的元件組成,並安裝在電路板上,使計算機變得更小、更快、更省電。
1960 年代,集成電路(ICs)出現,將多個晶體管集成到單塊硅片上。最終在 1971 年,英特爾(Intel)推出了 4004 ------ 全球首款商用微處理器,即一顆集成在單一芯片上的 4 位 CPU。這標誌着現代 CPU 的真正誕生。
Intel 8086 是如今 x86 CPU 架構的始祖,而目前提升效率的主流方案則是多核處理器 ------ 將多個 CPU 核心集成在單一芯片上。
那麼,現代 CPU 內部究竟包含什麼?它們又是如何工作的?
CPU 的核心是控制單元(control unit),它包含複雜的電路,通過發出電信號來控制整台計算機,並將數據和指令引導至正確的位置。算術邏輯單元(ALU)負責執行數學與邏輯運算,而寄存器(registers)和高速緩存(cache)則提供了極小但極快的存儲空間,用於存放處理器頻繁需要的數據。
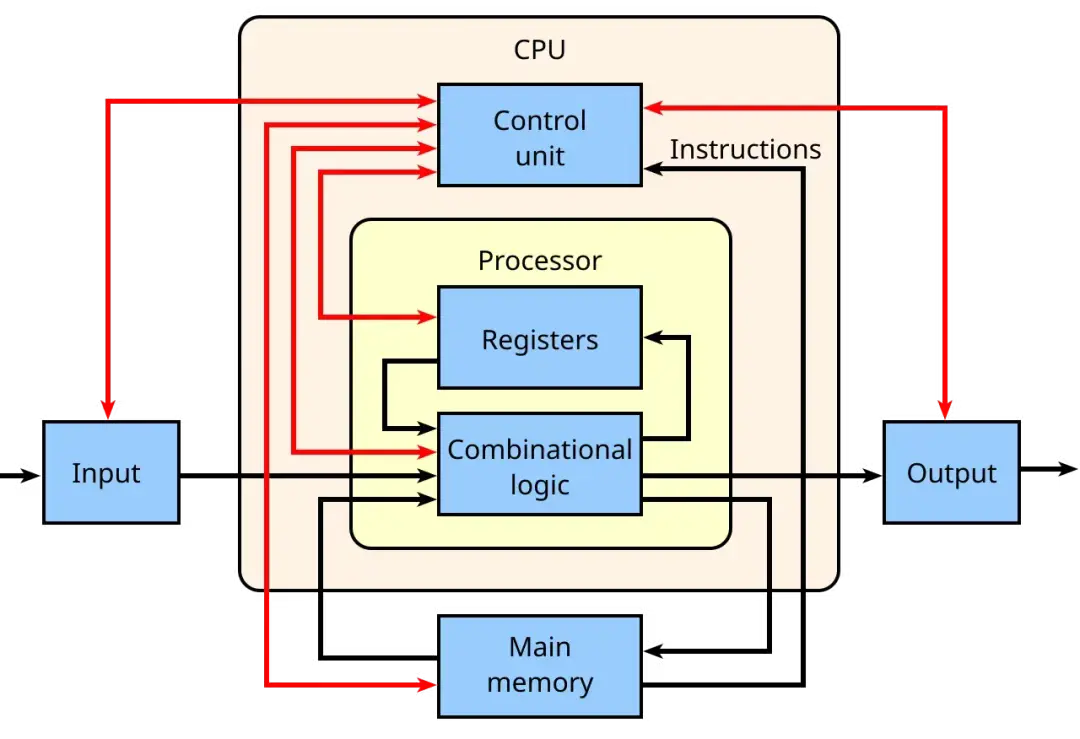
Image Credit: Wikipedia
CPU 還包含核心(cores) ------ 即 CPU 內部的處理單元,每個核心都能獨立處理指令;以及線程(threads),允許一個核心同時處理多條指令流。這些組件都按照時鐘信號(clock)的節拍運行,時鐘提供了同步整個系統所需的節拍。此外,還有總線(buses,用於數據傳輸)、指令寄存器(instruction register)和指令指針(instruction pointer,用於追蹤下一步要執行的內容)等輔助組件,將整個系統緊密連接,使指令能順暢地從一個步驟流轉到下一個。
CPU 的工作遵循一個簡單卻強大的循環:取指(fetch)→ 譯碼(decode)→ 執行(execute) 。
- 它從內存中取指數據或指令,
- 將它們譯碼為硬件能理解的信號,
- 然後執行所需的操作(例如計算、數值比較,或將數據發送到其他地方)。
在現代處理器中,這一過程每秒可發生數十億次,多個核心與線程並行工作提升性能,使 CPU 如同一個高度協同的組件團隊。CPU 核心數量較少(例如 1 到 2 個)時,通常更注重能效(即單位功耗下完成更多有效工作),適合輕量或日常任務,而核心數量較多的 CPU 則用於支撐高性能、高負載的任務。
如今的 CPU 主要來自以下廠商:
- Intel,產品包括 Core 系列(消費級)、Xeon(服務器/工作站)、Pentium 和 Celeron(入門級)芯片;
- AMD,提供 Ryzen(消費級/高性能)和 EPYC(服務器)處理器,以及 APU(Accelerated Processing Unit),它將 CPU 和 GPU 集成在同一顆芯片上(我們稍後會詳細討論)。
CPU 用於 AI 時面臨的主要問題是:它針對的是順序執行的通用任務,而非大規模並行的矩陣運算,因此在速度和能效上遠遜於 GPU 或專用芯片。
接下來,讓我們轉向介紹第二款芯片 ------ 著名的 GPU。
1.2 圖形處理單元(Graphics Processing Unit, GPU)
圖形處理單元(GPU)專為高吞吐量的大規模並行數據處理而優化。GPU 最初被髮明用於加速圖像和視頻中的計算機圖形渲染,但後來人們發現它在非圖形計算任務中同樣大有用武之地。如今,GPU 被廣泛應用於可並行化的工作負載,例如處理數據密集型任務和訓練 AI 模型。
如今,GPU 是推動 AI 性能提升的核心力量,也是衡量 AI 計算能力的一項關鍵指標。
"圖形處理單元"(GPU)這一術語由 NVIDIA 於 1999 年正式提出,隨 GeForce 256 顯卡一同發佈。NVIDIA 稱其為全球首款 GPU,其官方定義為:"集成變換、光照、三角形設置/裁剪及渲染引擎的單芯片處理器。"
那麼,這款傳奇的 GPU 究竟是如何工作的?→
GPU 內部是一塊硅芯片,上面蝕刻着數十億個微型晶體管,被組織成數千個輕量級處理核心。這些核心通過複雜的佈線相互連接,並由高帶寬內存和緩存提供支持,使數據能在核心之間高速流動。整個芯片被封裝在保護材料中,並配有散熱系統來維持穩定運行。
(瞭解芯片歷史的最佳讀物之一是克里斯·米勒(Chris Miller)所著的《芯片戰爭:世界最關鍵技術的爭奪戰》(Chip War: The Fight for the World's Most Critical Technology),強烈推薦。)
與 CPU 不同,GPU 專為並行計算而生 ------ 它會將一項大型任務拆分成成千上萬個更小、彼此獨立的子任務,並將它們分發到各個核心上同步計算。正因如此,GPU 非常適合訓練和運行 AI 模型,因為這些模型涉及對海量數據集進行重複的矩陣與張量運算。得益於 GPU 的並行架構,原本需要數月的訓練如今幾天就能完成,推理速度也足以支撐實時應用 ------ 比如聊天機器人。
全球 GPU 生產的領軍者是 NVIDIA,它打造了完整的並行計算平台 CUDA(Compute Unified Device Architecture),將 GPU 硬件能力釋放到通用計算領域,大幅降低了 GPU 編程的門檻。
NVIDIA 面向 AI 基礎設施和行業應用的主要 GPU 產品包括:
- V100(Volta 架構) -- 專為深度學習加速而設計,首次引入 Tensor Core(張量核心) ------ 專用於加速 AI 訓練中矩陣運算的硬件單元。
- A100(Ampere 架構) -- 擁有更多 Tensor Core、更高內存帶寬,並支持多實例 GPU(MIG)技術,可將一塊物理 GPU 劃分為多個邏輯 GPU,提升資源利用效率。
- H100、H200(Hopper 架構) -- 當前 AI 領域的行業標準。H 系列支持 Transformer Engine、超大內存帶寬,以及極致的訓練與推理速度。
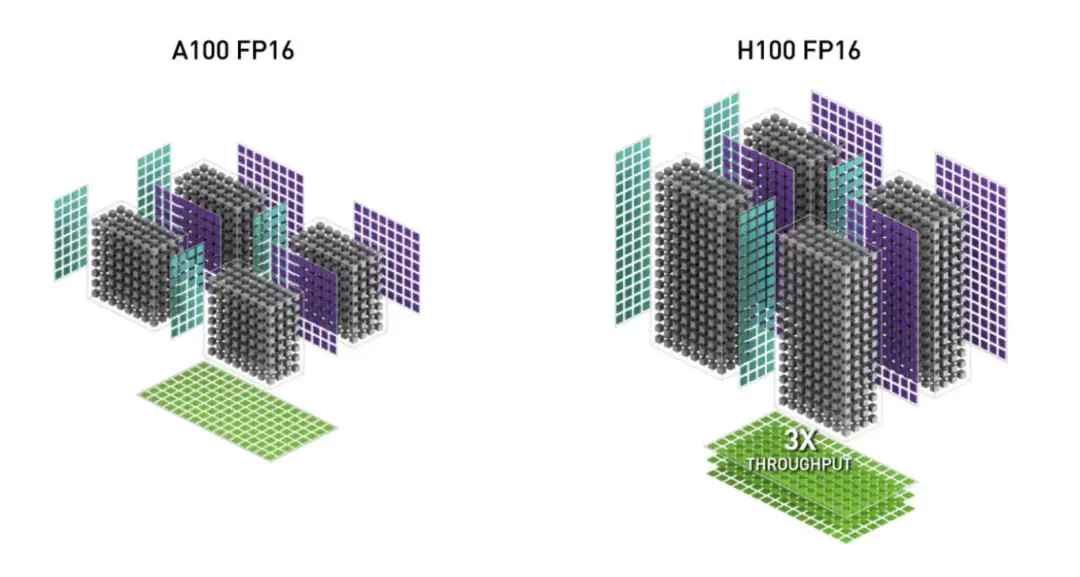
圖片來源:NVIDIA H100 NVL GPU 產品文檔
- Blackwell(例如 B200 和 GB200 Grace-Blackwell "超級芯片") 專為下一代擁有數萬億甚至十萬億級參數的 AI 模型而設計。作為 Hopper 架構的繼任者,它引入了 FP4 精度,並在推理吞吐量上實現了大幅提升,尤其針對超大規模 Transformer 工作負載。
隨着行業對 AI 專用處理器的需求日益增長,第三類核心硬件 ------ TPU 應運而生。
1.3 張量處理單元(Tensor Processing Unit, TPU)
張量處理單元(TPU)是由 Google 專為加速神經網絡運算(尤其是矩陣乘法與機器學習工作流)定製的芯片。它最初在 2016 年 Google I/O 大會上亮相,屬於 ASIC(Application-Specific Integrated Circuits,專用集成電路)類別。TPU 的基本架構如下:
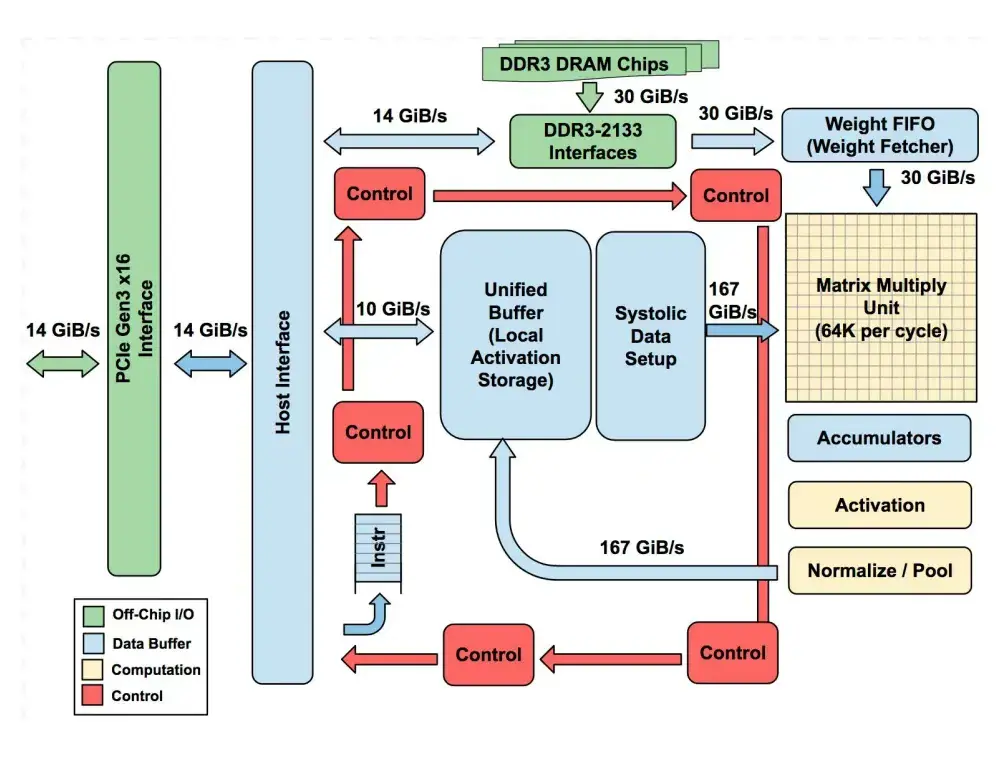
圖片來源:論文《In-Datacenter Performance Analysis of a Tensor Processing Unit》
- 其核心組件是矩陣乘法單元(Matrix Multiply Unit) ------ 一個巨大的 256×256 乘加單元(MAC)陣列,採用脈動陣列(systolic array)結構,數據以"波"的形式在網格中流動。
- TPU 還配備了大容量片上存儲器:
<!-- -->
-
- 統一緩衝區(Unified Buffer,24 MB):用於存放中間激活值;
- 權重存儲器/ FIFO(Weight Memory/FIFOs):用於存儲神經網絡權重;
- 累加器(Accumulators,4 MB):用於收集求和結果。
- 控制邏輯、PCIe 接口和激活單元(用於 ReLU、sigmoid 等函數)為矩陣引擎提供支持,但芯片的大部分面積都用於原始計算和高速數據傳輸。
TPU 的主要特點是作為協處理器工作:
- 主機 CPU 通過 PCIe 向 TPU 發送指令,TPU 直接執行這些指令。
- 其指令集非常精簡(僅約十幾條指令),硬件通過流水線設計確保矩陣單元始終處於忙碌狀態。
- 像 TensorFlow 這樣的框架會將模型編譯成這些底層指令。
256 個小型片上存儲器(分佈式累加器 RAM)用於收集部分和,而脈動陣列則執行乘加(MAC)運算。通過將權重和數據持續流入脈動陣列,並在片上緩衝區中本地複用,TPU 最大限度地減少了對片外內存的訪問。因此,大部分計算任務(逐層進行)都能直接在芯片上完成。
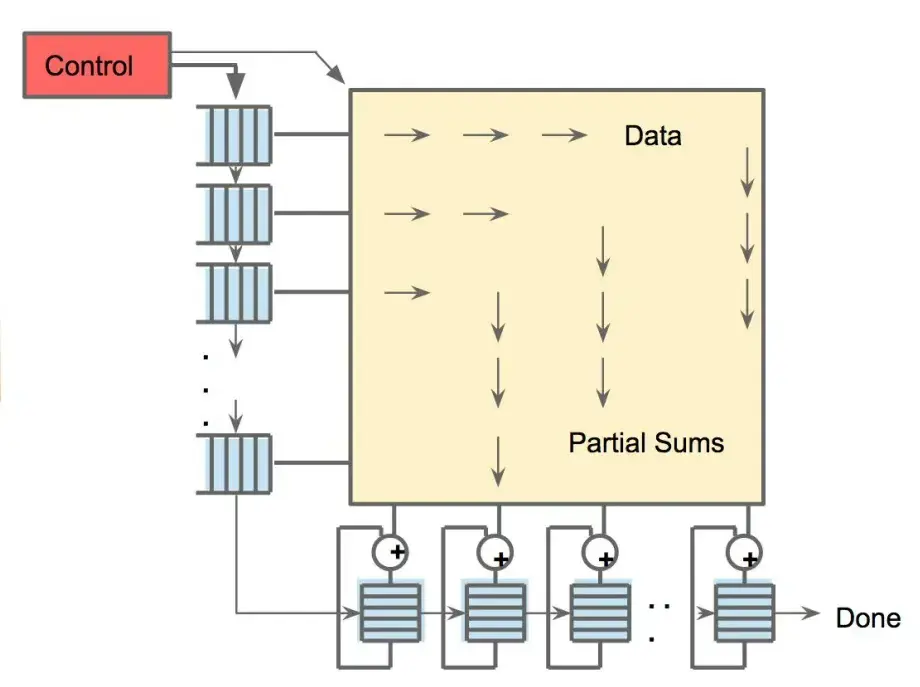
圖片來源:論文《In-Datacenter Performance Analysis of a Tensor Processing Unit》
總結來説,TPU 中的每個單元執行小規模計算,並將部分結果傳遞下去,從而節省功耗,並極大加快 AI 模型背後的數學運算速度。 這正是 TPU 在相同任務中能實現高吞吐量,同時功耗遠低於 CPU/GPU 的原因。根據 Google 2017 年的分析,TPU 在能效比(每瓦性能)上比同期 CPU 和 GPU 高出約 30--80 倍(在推理任務中,拿 TPU 和 K80 這類 GPU 做能效對比)。
然而,僅靠這三種硬件(CPU、GPU、TPU),我們仍無法全面理解驅動 AI 發展的全部技術力量。因此,我們還需梳理整個領域還有哪些技術可供選擇。由於 TPU 屬於 ASIC 類 AI 芯片,我們將從這一類別出發,探索更多強有力的替代方案。接下來,讓我們來深入看看它們如何構想未來 →
02 專用集成電路(Application-Specific Integrated Circuits, ASICs)
ASIC 是完全定製的硅芯片,專為某一種特定的 AI 工作負載而設計。這類芯片既包括雲服務巨頭的自研芯片,也涵蓋初創企業打造的專用 AI 硬件。在這一領域,我們不得不提及......
2.1 Cerebras 晶圓級引擎(Wafer-Scale Engine, WSE)
Cerebras 將未來押注於晶圓級芯片。其最新款 Cerebras WSE-3 芯片實際上是史上尺寸最大的 AI 芯片之一 ------ 面積高達 46,255 mm²。其核心技術在於:Cerebras 將整片硅晶圓直接製成一顆芯片,而不是像傳統 CPU 或 GPU 那樣將晶圓切割成數百個小處理器。
WSE-3 包含 4 萬億個晶體管、90 萬個專為 AI 優化的核心,以及 44 GB 片上 SRAM 內存。每個核心都配備有獨立的本地內存,並通過橫跨整個晶圓的超高帶寬互連網絡(fabric)彼此連接,從而大幅縮短計算單元與內存之間的距離。
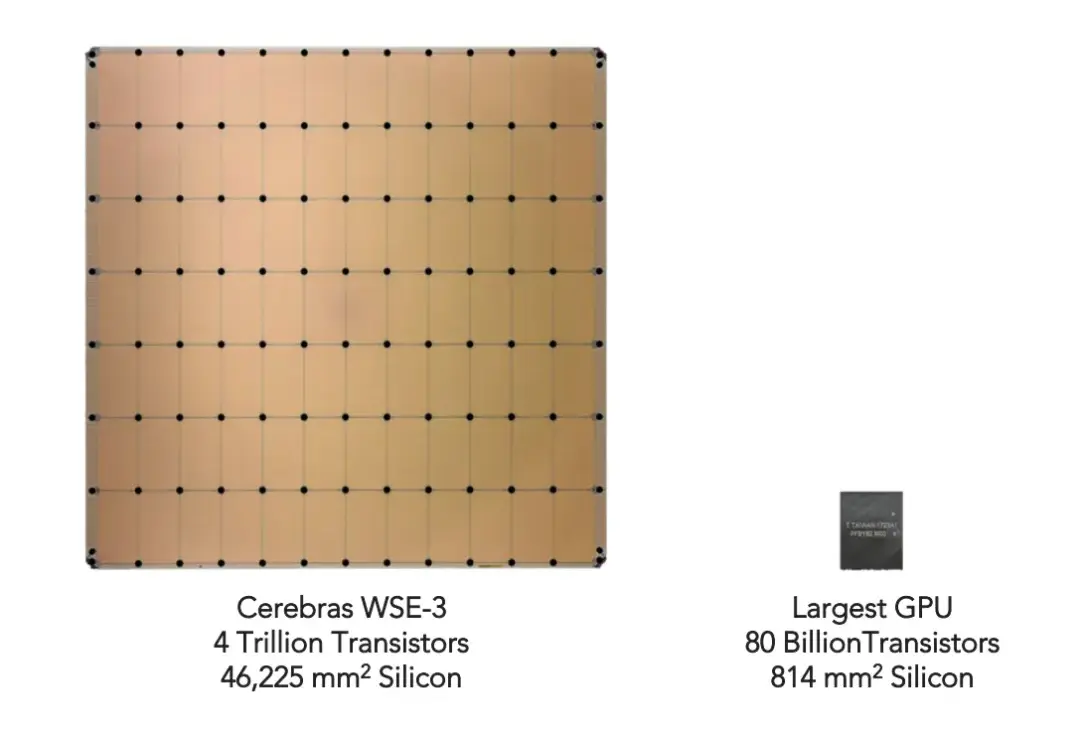
圖片來源:Cerebras Wafer-Scale Engine (WSE) 產品手冊
Cerebras 的晶圓級理念帶來了令人矚目的成果:
- 單顆 WSE-3 可提供 125 petaFLOPS 的 AI 算力。
- 據 Cerebras 聲稱,將 WSE-3 組合成晶圓級集羣(Wafer-Scale Cluster, WSC),並集成 MemoryX(用於存儲超大模型權重的片外存儲)和 SwarmX(用於在節點間廣播權重並聚合梯度),即可高效支持數萬億參數模型的訓練,且幾乎能隨硬件規模線性提升性能,同時規避傳統 GPU 集羣中複雜的通信開銷。
目前有哪些模型已在 Cerebras WSE 上運行? 以下是兩個典型示例:
1)阿里巴巴的 Qwen3 Coder 480B Instruct,推理速度達到 每秒 2,000 個 token。
2)混合專家模型(Mixture-of-Experts, MoE):Cerebras 使其大規模訓練變得更加簡單高效。這類模型可在單個設備上完成訓練,無需模型並行(而使用 GPU 時通常必須依賴模型並行)。Cerebras 採用的注意力批處理分塊(Batch Tiling on Attention, BTA)技術,解決了稀疏 MoE 模型的計算效率問題 ------ 它將注意力層與專家層的批處理需求解耦:注意力層在較小的"分塊"(tiles)上運行,以降低內存壓力;專家網絡則處理更大的有效批次,確保其核心始終處於高利用率狀態。
由此可見,這是一項以規模製勝的強大技術。
2.2 AWS Trainium 與 AWS Inferentia
亞馬遜同樣推出了突破 GPU 壟斷的替代方案,並形成了自己對高效硬件的獨特構想。其兩款自研芯片專為 AI 工作負載設計,並深度集成於 AWS 生態系統之中。
AWS Trainium 專用於模型訓練,AWS Inferentia 則面向推理任務。這兩款芯片內部均採用定製的 NeuronCore、高帶寬內存(HBM),以及用於張量運算、集合通信和稀疏性加速的專用引擎。
配備 64 顆 Trainium 2 芯片的 Trainium 2 UltraServer 服務器,在處理稀疏模型時,最高可提供 83.2 petaflops 的 FP8 算力;在處理稠密模型時,FP8 算力約為 20.8 petaflops。相比之下,單顆 NVIDIA H100 GPU 的 FP8 算力大約只有 4 petaflops。
AWS Inferentia 2 支持大規模部署大語言模型(LLM)和擴散模型(diffusion models),其每瓦性能比基於 GPU 的同類 EC2 實例(例如 G5 系列)提升約 50 %。
因此,AWS 硬件為生成式 AI 的需求提供了在規模、性能與成本效益三者之間高度平衡的解決方案。
在瞭解了這些定製化的高效 ASIC 的案例後,我們再回到那些名字中帶有 "..PU" 的硬件新鋭。接下來是......
2.3 加速處理單元(Accelerated Processing Unit, APU)
如前文所述,AMD 開發了一種混合型處理單元架構,將 CPU 與 GPU 的能力融合進單一芯片封裝中,由此誕生了加速處理單元(APU)。這種設計消除了在獨立處理器之間來回傳輸數據所帶來的性能瓶頸。
迄今為止,該理念的最大代表作是 AMD Instinct MI300A。它集成了 24 個 "Zen 4" CPU 核心、228 個 GPU 計算單元,以及高達 128 GB 的 HBM3 內存。
其內部採用 AMD 的 chiplet(小芯片)與 3D 堆疊技術打造。MI300A 的內存能夠在 CPU 和 GPU 之間共享,峯值帶寬高達 5.3 TB/s。其多芯片架構通過 chiplet 與裸片堆疊,將 CPU 和 GPU 計算單元緊鄰高帶寬內存佈置,並由 AMD 的 Infinity Fabric 與 Infinity Cache 統一互聯。此外,該芯片全面支持主流 AI 數據格式,並具備硬件級稀疏性加速能力。
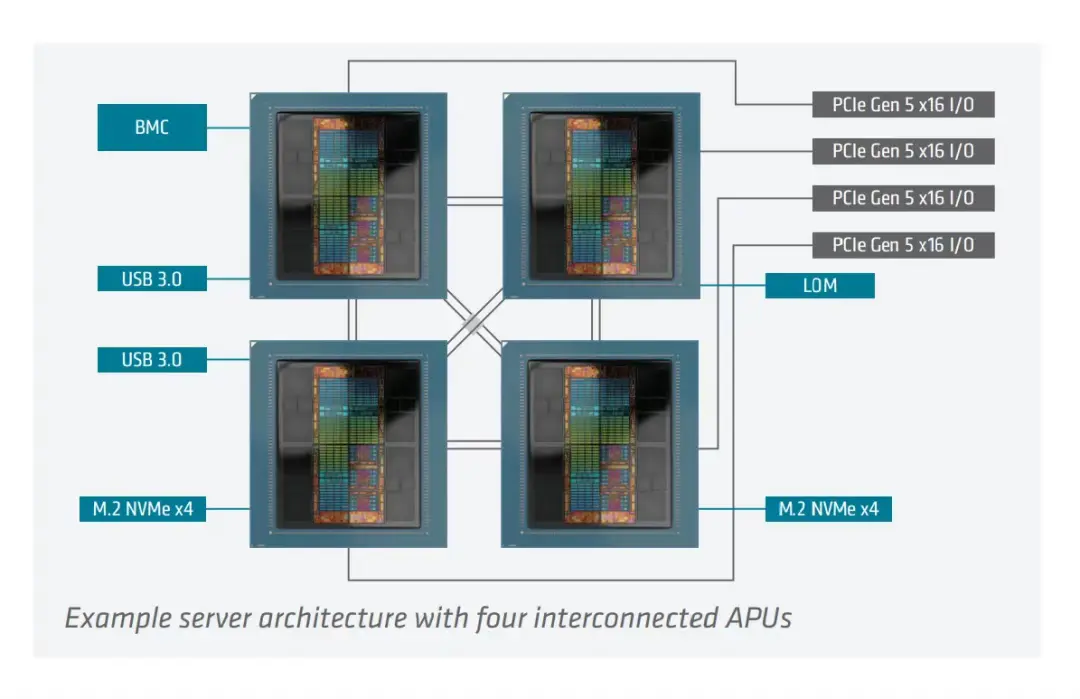
圖片來源:AMD INSTINCT™ MI300A APU 產品手冊
那麼問題來了:既然可以擁有"一體式引擎",又何必在 CPU 和 GPU 之間做選擇?
NVIDIA 也在其 NVIDIA Grace Hopper Superchip 中踐行了類似理念 ------ 這是一款統一模塊,將基於 Arm 架構的 Grace CPU 與 Hopper GPU 通過 NVIDIA 自研的 NVLink-C2C 芯片間互連技術緊密耦合。其核心優勢與 AMD MI300A 高度一致:
- CPU 與 GPU 線程可直接訪問彼此的內存,
- 能夠執行原子操作,
- 並實現更高效的同步管理。
NVIDIA 表示,Grace Hopper Superchip 在圖神經網絡(GNN)訓練上,速度比通過 PCIe 互聯的 H100 GPU 快最多 8 倍;在嵌入向量(embedding)生成任務上,比純 CPU 方案快約 30 倍。
然而,這種 CPU 與 GPU 的融合也帶來了更高的功耗、更低的靈活性以及更復雜的製造工藝。
接下來,我們將轉向一些更小巧的硬件類型。
2.4 神經網絡處理單元(Neural Processing Unit, NPU)
你可以想象一下,在一顆普通芯片內部專門內置一個用於 AI 任務的加速器 ------ 這也正是神經網絡處理單元(NPU)的核心理念。NPU 本質上是現代芯片中專為運行 AI 工作負載而打造的小型引擎,用於處理神經網絡、圖像與語音識別,甚至本地運行的大語言模型(LLM)。通過模擬人腦神經網絡架構,NPU 針對 AI 工作負載的計算模式進行專門優化:大量矩陣乘法、激活函數運算,以及在極低功耗下實現高速數據移動。
以下是一些我們如今能在各種設備中實際找到的 NPU 示例:
- 高通(Qualcomm)Snapdragon 芯片中的 Hexagon NPU,為智能手機、汽車、可穿戴設備等提供 AI 功能支持。
- Apple Neural Engine:首次亮相於 2017 年的 A11 Bionic 芯片,如今已集成於所有搭載 Apple Silicon 的 iPhone、iPad 和 Mac 中,用於驅動 Face ID、圖像處理和 Sir 等功能。
- 英特爾 NPU(搭載於新一代酷睿 Ultra AI PC 處理器,如 Lunar Lake、Arrow Lake),專為在本地運行 Windows Copilot+ 功能而設計。
- AMD 的 XDNA / XDNA 2 NPU:出現在面向筆記本的 Ryzen AI 處理器中,AI 性能高達 55 TOPS。
NPUs 非常適合端側推理,但尚不足以用於訓練大語言模型或運行極高負載的任務。 此外,它們也無法取代 CPU 或 GPU 來執行通用計算任務。 如果你運行的不是神經網絡類負載,NPU 甚至無法正常發揮作用。正是這種高度專精的特性,使 NPU 在眾多"PU"中獨樹一幟。
03 其他有前景的替代架構
3.1 智能處理單元(Intelligence Processing Unit, IPU)
Graphcore 開發的 IPU 是一款具備 1,472 個獨立處理器核心的大規模並行處理器,可同時運行近 9,000 個並行線程,並緊密耦合 900 MB 高速片上內存。這意味着數據可以在存儲位置直接被處理。IPU 專為機器學習工作負載設計,憑藉極高的細粒度並行能力和片上內存架構,它在圖計算方面表現出色,能夠通過並行處理圖中各個節點上的操作,高效應對不規則且稀疏的工作負載。
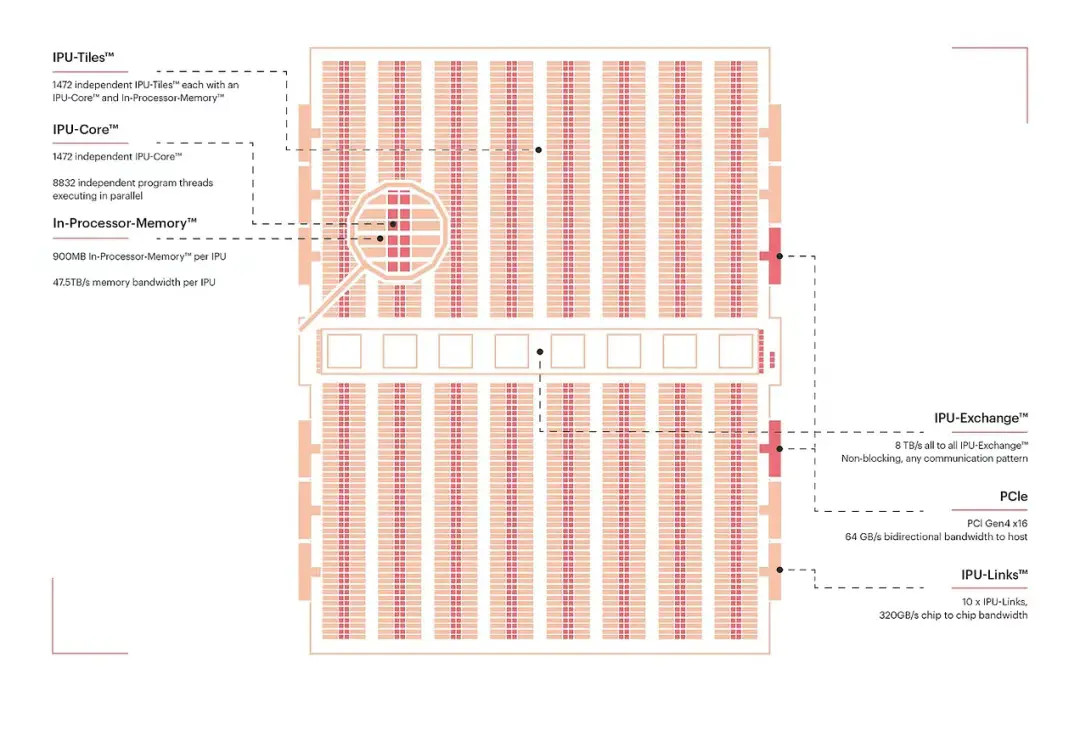
圖片來源:Graphcore IPU 博客,《Colossus™ MK2 GC200 IPU》
3.2 阻變處理單元(Resistive Processing Unit, RPU)
RPU 是一種實驗性的存內計算(in-memory compute)單元,利用阻變存儲器(如憶阻器 memristor 或 RRAM)直接在內存陣列中執行矩陣運算。這種方法極大減少了數據搬運,有望顯著降低能耗與延遲。2025 年,IBM 研究人員展示了基於 ReRAM 的模擬存內 AI 加速器,支持片上訓練與推理,具備低電壓開關特性和多比特存儲能力。
3.3 現場可編程門陣列(Field-Programmable Gate Arrays, FPGAs)
FPGA 在可重構 AI 領域具有重要地位,尤其適合需要完全掌控並行性、內存和延遲的場景。與 GPU 或 ASIC 不同,我們可以根據模型的具體需求定製 FPGA 的硬件邏輯,並在架構變更後重新編程。
典型案例如 AMD Versal™ AI Edge 系列 Gen 2,它屬於 AMD 的自適應 SoC(System-on-Chip)家族。該芯片在傳統 FPGA 可編程邏輯的基礎上,進一步在同一裸片上集成了 Arm CPU 和專用 AI 引擎。
04 新興架構(Emerging Architectures)
4.1 量子處理器(Quantum Processors)
量子芯片使用量子比特(qubits),而非經典比特,利用疊加(superposition)與糾纏(entanglement)等量子特性進行計算。目前,它們正被用於優化、搜索和模擬等任務領域的測試 ------ 這些領域在理論上有望藉助量子力學實現指數級加速。然而,量子比特仍然極其脆弱且易受噪聲干擾,因此當前的量子計算機僅能處理"玩具級"問題。就現階段而言,它仍是一個長期的"登月計劃",尚無法替代 GPU 或 ASIC。
4.2 存內計算(Processing-in-Memory, PIM)與基於 MRAM 的芯片
AI 面臨的一大瓶頸在於內存與計算單元之間的數據搬運。PIM 技術將計算邏輯直接集成到內存陣列中,從而大幅減少這種來回傳輸。MRAM(磁阻隨機存儲器)是一種前景廣闊的非易失性存儲技術,能夠支持這一範式轉變,助力打造更高密度、更節能的 AI 加速器。三星等大廠以及 Mythic 等初創公司已開始試驗相關原型。PIM 並非科幻概念 ------ 未來十年內有望實際進入數據中心與邊緣設備。
4.3 神經形態芯片(Neuromorphic Chips)
神經形態處理器受人腦脈衝神經元(spiking neurons)啓發。與傳統依賴密集的、時鐘驅動的矩陣乘法不同,它們採用稀疏的、事件驅動的脈衝信號進行計算。例如 Intel 的 Loihi 和 IBM 的 TrueNorth,目標是在傳感器、物聯網(IoT)和機器人等場景中實現超低功耗的智能。其主要挑戰在於:脈衝神經網絡(SNN)仍處於早期階段。儘管神經形態硬件在低功耗邊緣 AI 領域潛力巨大,但尚不確定它能否擴展至像大型 Transformer 這類的主流工作負載。
05 結語(Conclusion)
總體而言,各類硬件的定位如下:
- CPU(中央處理單元)------通用處理器。
- GPU(圖形處理單元)------專為並行圖形計算/數學計算優化。
- TPU(張量處理單元)------Google 的 AI 加速器。
- ASICs(專用集成電路)------為特定 AI 工作負載定製的芯片。
- APU(加速處理單元)------AMD 的 CPU + GPU 融合架構。
- NPU(神經網絡處理單元)------專為端側 AI/ML 推理優化的小型芯片。
- IPU(智能處理單元)------提供極高細粒度的並行性與片上內存架構。
- RPU(阻變處理單元)------基於阻變存儲器的存內計算單元。
- FPGAs(現場可編程門陣列)------支持對並行性、內存和延遲的完全控制。
由此可見,如今"PU"家族選項豐富,GPU 之外也涌現出多種替代方案,這使得硬件生態呈現多樣化的態勢,併為未來多方向的突破敞開大門。近期,多家科技巨頭紛紛宣佈正在研發新一代硬件:NVIDIA 正在推進 Rubin 架構,Meta 在測試自研芯片,阿里巴巴及其他中國公司也在開發 AI 推理芯片,以構建自主的硬件生態。這意味着更多全新的技術棧將陸續登場。
若跳出 GPU 和 CPU 的傳統框架,我們能清晰看到一個趨勢:AI 硬件市場正加速碎片化,各大廠商都在推動各自的軟硬一體化生態。 這對開發者和企業而言,既是機遇,也是挑戰 ------ 如何在不斷擴張的硬件版圖中,有效應對兼容性、軟件支持與成本效益等問題,將成為未來的關鍵課題。
END
本期互動內容 🍻
❓AI 硬件生態正加速碎片化,你認為未來是"一超多強"還是"百花齊放"?
原文鏈接:
https://www.artificialintelligencemadesimple.com/p/inside-the-ai-hardware-race-guest
