本文轉載自:https://mp.weixin.qq.com/s/s13YBYD9R8y-PK7FO3Suyw
作者:OpenBMB開源社區
近日,字節跳動發佈的豆包手機助手在業內激起了廣泛討論。這不僅是一款新智能硬件的亮相,更標誌着大模型應用範式的一次重要躍遷——從“Chat(對話)”真正邁向“Action(行動)”。作為長期深耕大模型領域的研究者,我們將豆包手機助手定義為行業首款系統級 GUI Agent。它不再是一個孤立的智能應用,而是深度耦合於操作系統底層、具備跨應用感知與操作能力的“超級中樞”。
如何看待豆包手機助手的當下與未來?藉此機會,我們希望與大家分享我們眼中的手機助手,以及端側智能的演進願景與路線圖。
豆包手機助手關鍵技術解析與研判
GUI Agent 無疑是豆包手機助手的核心技術。為透視豆包手機助手的技術本質,我們有必要先回顧 GUI Agent 技術從實驗室走向產業界的演進脈絡。2023 年至 2025 年間,GUI Agent 技術經歷了從“外掛式框架”到“模型原生智能體”的根本性範式轉變:
GUI Agent 發展的最早期階段(2023‑2024)採用外掛式框架,其核心思路是不改變大模型本身,而是通過提示工程將界面轉化為模型可讀的文本和函數接口(如 HTML/DOM 樹,代表工作有 OSU 的 Mind2Web、騰訊的 AppAgent)或帶數字標記的截圖(Set‑of‑Mark,如阿里的 Mobile‑Agent‑v1)。這一階段的智能體能力上限受限於提示詞設計與外部工具(OCR、檢測模型)的精度,模型並未真正“看見”GUI 環境,更多是在進行文本邏輯推理。
後來,模仿學習驅動的視覺語言模型方案代替出現(2024)。隨着視覺語言模型能力提升,技術路徑轉向模型內生。智譜的 CogAgent、我們的 GUICourse [1]、上交&MIT 的 OS‑Atlas 等工作摒棄了對 XML/DOM 等底層數據的依賴,直接基於像素輸入理解界面,並輸出座標。這一階段實現了感知層面的“原生化”,模型開始像人類一樣通過“看”屏幕來理解界面佈局,顯著提升了對非結構化 GUI 的適應能力。
目前,強化學習驅動的視覺語言模型成為主流(2024‑2025)。其核心突破在於引入強化學習以解決複雜決策問題。伯克利的 DigiRL 首次驗證了利用強化學習構建 GUI Agent 的可行性。在此基礎上,智譜的 AutoGLM 和我們的 AgentCPM‑GUI [2] 進一步在大規模 GUI 任務中驗證了強化學習的有效性。字節的 UI‑TARS 工作則引入大規模在線強化學習,使得智能體能在與 OS 環境的持續交互中優化策略,學會錯誤修正、長程規劃與泛化應對。至此,GUI Agent 真正具備了在動態環境中自主執行任務的能力,而豆包手機助手正是這一技術路線的集大成者。
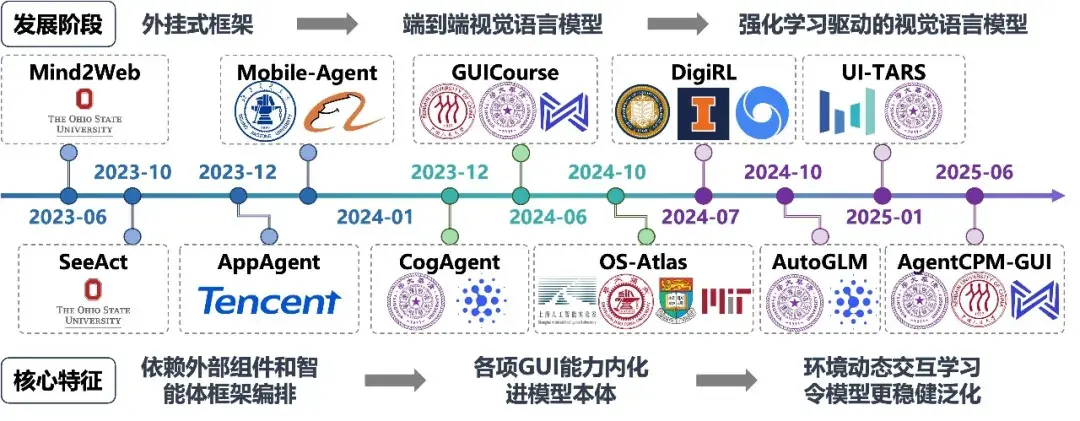
GUI Agent 的發展歷程
而為何之前的 GUI Agent 多停留於 Demo 階段,而豆包手機助手卻接近了實用臨界點?通過技術覆盤,我們認為其在工程側與模型側完成了關鍵突破:
在工程側,以往的 GUI Agent 方案多依賴 Android 無障礙服務或 ADB 調試,存在權限易屏蔽、高延遲以及“搶佔前台焦點”干擾用户等致命缺陷。豆包手機助手憑藉定製 OS 的優勢,實現了“非侵入式”的系統級接管。據我們研判,其工程實現包含兩大核心要素:
-
GPU Buffer 直讀:繞過傳統截圖接口,在系統底層直接讀取屏幕渲染緩衝區的數據,大幅降低了視覺信號獲取的延遲。
-
虛擬屏幕後台進程:這是一個巧妙的工程技巧。為避免智能體操作搶佔用户焦點,系統內部構建了第二塊虛擬屏幕,AI 在後台不可見的虛擬屏幕上執行點擊與滑動,而前台用户仍可正常使用。
而在模型側,綜合現有使用體驗與技術特徵判斷,豆包手機助手採用端雲協同的模型架構:
-
端側模型:主要負責意圖識別與任務路由。對於調節音量、亮度等簡單任務,直接通過端側模型調用本地系統 API 完成,實現毫秒級響應。
-
雲側模型:處理多步驟、跨應用的複雜任務(如跨 APP 訂票)。該模型內部區分“思考”與“非思考”兩種模式:非思考模式下以低時延直接執行;思考模式下會先進行任務拆解、流程規劃與需求澄清,再進入執行階段,以平衡響應速度與任務成功率。
-
RL 數據飛輪:其核心護城河在於建立了基於強化學習的數據閉環。通過高保真 OS 沙盒環境,模型經歷了數百萬次軌跡的探索與優化,高質量數據用於下一輪 SFT 訓練,低質量數據回收至持續預訓練階段。這種工業級數據規模使其泛化能力顯著優於學術界開源模型。
豆包手機助手的出現,標誌着 GUI Agent 終於走出實驗室的“玩具”階段,開始具備實用價值。它揭示了一個事實:大模型不僅是大腦,更能接管屏幕、模擬觸控,成為連接數字世界的“萬能接口”。當然,若我們將目光投向更長遠的未來,GUI 操控或許並非端側智能的終局。 目前的 GUI Agent 本質上是一種“兼容舊生態”的過渡方案——它不得不通過模擬人類的視覺和觸控,去適應那些並非為 AI 設計的圖形界面。這種方式雖然通用,但鏈路過長、依賴屏幕渲染。 我們認為,隨着端側生態的成熟,手機助手的操控方式可能進一步兼容“APP/系統工具調用”與“生態級智能協同”:
-
APP/系統接口調用:相比於模擬點擊,直接調用 APP 或系統的接口(API)具備更高的準確率和更短的執行鏈路。事實上,豆包手機助手在調節音量、亮度等系統級任務上,正是通過直接調用系統接口實現了毫秒級的零失誤響應。雖然目前第三方 APP 廠商開放接口的意願受限於商業博弈,但隨着 AI 手機滲透率的提升,高頻功能(如支付、打車、預訂)必將從“視覺組件”封裝為“語義接口”,供智能體高效調度。
-
APP 即智能體:目前的架構中,手機助手作為“大腦”需要承擔極其沉重的認知負荷,它必須理解成千上萬個 App 內部的微觀邏輯。未來的 APP 或許不再僅僅是等待被操作的“工具”,而是演化為具備獨立能力的“子智能體”。對於“規劃差旅”這種超長程任務,主智能體僅需向下分發子任務,而具體的比價、選座、風控核驗等繁瑣步驟由 App 內部的子智能體在應用內自主閉環。這種分層協作模式將極大降低主智能體的認知負荷,通過生態級的智能分工,顯著提升複雜任務的執行泛化性與魯棒性。
豆包手機助手雖然目前主要依賴 GUI 技術,但其在系統層面的深度整合,實際上也為未來向 API 調用和多智能體協同演進展示了可能性。
豆包手機助手的技術侷限性分析與展望
豆包手機助手讓大眾看到了端側智能的潛力。但從性能評測與應用生態來看,以它為代表的端側智能體要想真正服務數十億用户的智能化生活,仍需攻克三大方向難題:
首先,終端調用雲側模型存在安全風險。豆包手機雖採用端雲協同架構,但絕大多數屏幕理解與操作任務仍嚴重依賴雲側 GUI 模型,這相當於將用户的數字生活全面映射至雲端。“雲側接管一切”的模式在隱私安全、網絡依賴和算力成本上均面臨可持續性挑戰,也觸及了應用廠商將用户行為數據視為核心資產的紅線。其直接後果是,豆包手機助手在市場博弈中已陸續暫停對微信、淘寶等核心應用的智能操作支持。我們判斷,未來的 AI 手機生態不應是“雲側通吃”,而應遵循端雲結合原則:雲側模型處理通用邏輯與專業需求;涉及用户隱私、實時交互的私有數據必須在端側閉環。當前“端側過輕”的架構缺陷,亟需通過構建本地“安全屋”來化解。
其次,智能體自主完成任務能力不足。我們在豆包手機助手發佈後第一時間進行了高難度測評,並同時開展智譜 AutoGLM 的測評作為參照。結果顯示,豆包手機助手在 59.86% 的複雜任務上取得成功,AutoGLM 等開源方案則成功率更低。失敗案例覆盤顯示,核心問題集中在四方面:
-
生態覆蓋有限:面對小紅書、美團、淘寶等高頻應用,智能體常因無法精準調起原生應用,被迫降級為網頁搜索或通用問答,“服務直達”退化為“內容檢索”。
-
複雜指令解析精度不足:模型對含多參數(時間、地點、價格)、多對象(私聊 vs 羣聊)的複合指令理解存在缺陷,難以精準提取關鍵槽位信息。
-
動態環境執行魯棒性缺失:面對網絡波動、權限彈窗及風控校驗時,模型缺乏中斷恢復與替代方案規劃能力,易因單點受阻陷入死循環。
-
長程交互上下文管理混亂:在多輪交互中,模型易受歷史信息干擾,導致“最近”“附近”等時空約束被錯誤覆蓋。
最後,個性化與主動服務能力不足。目前的豆包手機助手本質仍是“用户下令‑智能體執行”的被動工具。大模型擁有全人類通用知識,卻唯獨缺少對“你”的深度理解。它不知道你下班的習慣路線、點咖啡的糖度偏好,也無法在開會時自動攔截騷擾電話。真正的個人助理必須是“千人千面”的,這要求智能體能夠利用端側數據進行持續學習,形成專屬用户的個性化記憶。當前的豆包手機助手仍偏向傻瓜式任務自動化,遠未達到個性化主動服務的階段。
綜上所述,為應對隱私安全、環境感知、複雜任務決策與個性化服務四大挑戰,未來的 AI 手機技術體系必須向 端側智能(隱私安全)、全模態智能(環境感知)、自主智能(複雜決策)與 主動智能(個性化服務)四個方向持續演進。
端側智能:以端側模型實現安全可控的智能應用
現代移動操作系統的安全基石是“沙盒機制”,即應用間數據隔離、互不干擾。然而,系統級 GUI Agent的出現,本質是賦予了一個超級進程一把打開所有沙盒的“萬能鑰匙”。豆包手機助手的實踐揭示了一個根本性矛盾:系統級智能體為實現“萬能操作”所必需的全局視野,與用户對隱私和數據主權的根本訴求之間,存在着天然張力。而解決這一矛盾,是端側智能走向普及的前提。
儘管廠商採用了“端雲協同”架構,並宣稱對密碼輸入等極端敏感場景進行本地處理,但在絕大多數日常場景下,海量用户行為數據的流向與控制權依然是一個不透明的“黑盒”。這導致了便利性與數據主權之間的根本博弈:如果每一次點擊、每一屏瀏覽都需要經過雲端審視,用户實際上是在向服務商讓渡自己的“數字主權”。一旦這個超級智能體被攻破,後果將不堪設想。
正是基於對上述矛盾的深刻認識,我們認為,未來的AI手機生態絕不能是“雲側通吃”,而必須確立 “端側原生、端雲協同” 的根本原則,建立清晰的分工體系。端側是 隱私的“守門人”與體驗的“基石”:涉及用户隱私、實時交互、個人習慣的所有“私有域”數據與操作,必須在端側形成閉環。用户是數據的唯一持有者,端側模型充當隱私的“守門人”。這不僅是保護數據主權,也是實現毫秒級極致響應、提供“類人”交互體驗的物理基礎。雲側是專業的“智庫”與廣域的“連接器”,涉及海量知識、複雜邏輯推理或需要廣泛互聯的“專業域”任務,則可路由至雲側專家模型處理。雲側憑藉其參數規模、知識廣度與互聯網連接,充當專業的智庫。這一分工的改進是 將數據主權和安全閉環堅定地錨定在端側。當智能真正在用户設備內部運行時,人機之間更容易建立起堅實的信任契約,這也是我們團隊堅持“端側原生”路線的根本原因。
將大模型能力裝入邊緣設備,面臨功耗、存儲和算力的多重約束。我們團隊並未盲目追逐參數規模,而是圍繞 “端側、高效” 構建全棧技術壁壘,核心是提升模型的“能力密度”——即單位參數內藴含的智能水平。因此,我們提出 “能力密度法則” :大模型能力密度每 3.5 個月翻倍。這意味着,技術創新的目標是以更小的模型實現更強的性能,這一規律反映了大模型發展從"尺度驅動"向"能效驅動"的必然轉變。圍繞這一法則,我們構建了“模型架構-數據治理-學習方法”的高能力密度製備技術體系,其中以模型架構技術為例,w在 稀疏模型架構 和 軟硬協同的極限壓縮與加速 兩方面的工作,驗證了這一技術發展方向的可行性:
-
稀疏模型架構:我們研發瞭如 BlockFFN [3] 和 InfLLM-V2 [4] 等技術,摒棄傳統 Transformer 的全參數激活模式,實現計算資源的“按需分配”。在推理時僅激活極少部分相關神經元,尤其在處理長文本時,能將計算複雜度從二次方降低至線性,實現超高稀疏度,讓端側設備“跑得動、不發燙”。
-
軟硬協同加速:針對“內存牆”瓶頸,我們融合投機採樣與極低比特量化技術。通過“小模型起草、大模型驗證”的協同解碼,以及將參數壓縮至 4 比特乃至更低,大幅降低內存帶寬佔用。我們開源的輕量端側模型 MiniCPM 系列,累計下載超 1700 萬次,並已落地眾多主流終端設備。
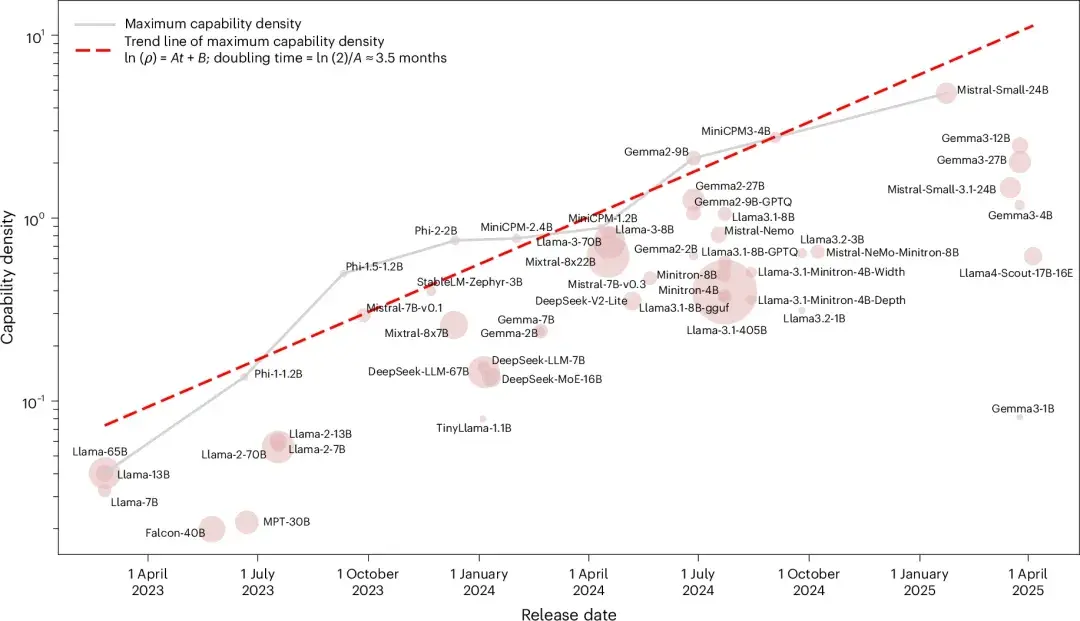
大模型的能力密度在不斷增強[7]
端側智能不僅僅是技術路徑的選擇,更是價值取向的錨定。它通過將隱私閉環於設備、將響應提速至毫秒、將算力負擔優化至可持續,從根本上解決了智能普及中的信任、體驗與成本問題,是構建未來個人化、可信賴數字伴侶的必由之路。
全模態智能:能聽會看的全模態感知能力
包括豆包手機助手在內的當前 GUI Agent,在感知層面仍主要依賴“截圖+上傳”的靜態處理模式。要實現真正的“類人”助手體驗,智能體必須突破傳統視覺語言模型的模態壁壘,具備在端側深度處理文本、圖像、視頻、音頻等多模態信息的能力。我們認為,下一代端側智能感知將圍繞 “統一架構下的全模態融合” 與 “實時流式的動態交互” 兩個維度演進。
第一,架構演進需要從“多模態”走向“全模態”。當前主流多模態模型本質仍是“拼接式”架構,即通過連接器淺層對齊視覺/音頻編碼器與語言模型。這種範式限制了對跨模態細微關聯(如語音語調與面部表情的同步性)的捕捉能力。隨着 GPT‑4o 及 Gemini 系列模型的發佈,全模態(Omni)正成為新前沿。這類模型旨在底層打通不同模態的表徵空間,實現原生的理解與生成。在端側算力受限的挑戰下,我們的 MiniCPM‑o 系列模型驗證了這一路徑的可行性:我們摒棄臃腫的外部組件堆疊,通過統一建模將語音理解生成、視覺理解與文本處理集成到高效端側基座中。這種架構統一不僅顯著降低推理開銷,更使智能體能像人類一樣綜合處理並行信號,為未來覆蓋觸覺、温度等更廣泛物理信號奠定基礎。我們相信,全模態感知能力是大模型走出屏幕、走進物理世界,支撐具身智能、自動駕駛等關鍵應用的重要基礎。
第二,交互演進需要從“靜態採樣”走向“動態流式”。真實世界的多模態信息流是動態連續的,而非靜態截圖。當前大部分端側智能體僅能處理離線採樣數據,相當於對真實世界進行“切片”。這種“回合制”交互導致顯著延遲,無法滿足實時翻譯、視頻通話輔助等即時需求。為打破瓶頸,端側感知必須向流式演進。我們研發的 MiniCPM‑o 2.6 通過多路時分複用的流式編碼技術,在端側設備上實現了對動態信息流的實時響應。模型無需等待語音説完或視頻錄完,而是在接收信息的同時進行增量式理解與決策。這種流式架構不僅大幅降低首 token 延遲,更實現“全雙工”交互——用户可隨時打斷模型,模型也能敏鋭捕捉插話時機。此外,針對流式處理可能丟失細節的問題,我們在底層融合了 LLaVA‑UHD [5] 的高分辨率處理技術,通過自適應切片策略,實現對任意長寬比圖像的低功耗、低延遲高清編碼。“流式傳輸+高清編碼”的組合,讓端側智能體既能流暢“看”視頻,也能精準捕捉一閃而過的文字細節(如屏幕報錯代碼),真正將電影《Her》中全天候、實時響應的智能伴侶帶入現實。
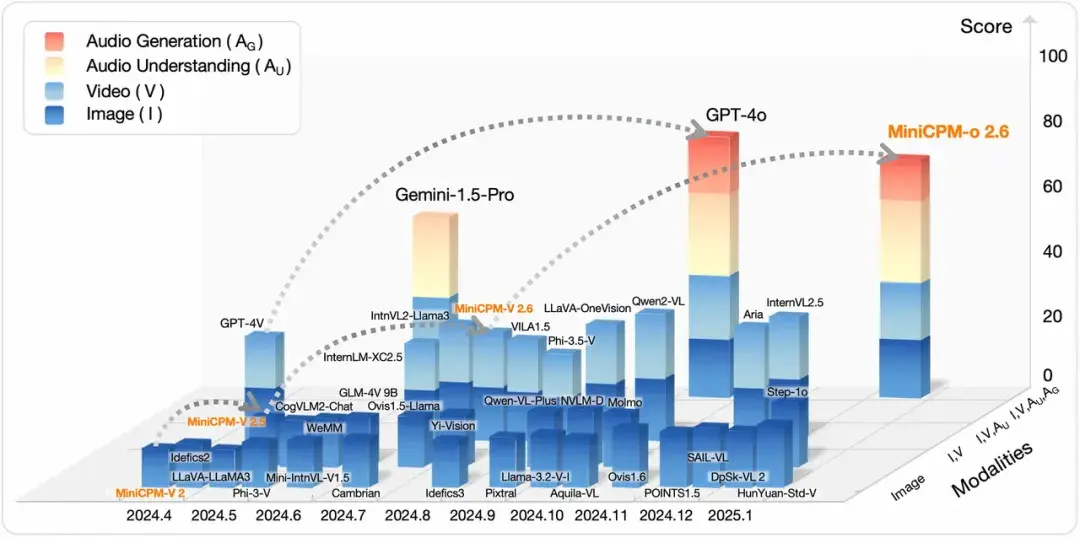
大模型多模態能力的發展歷史可視化
自主智能:大模型智能體的下一個技術突破
豆包手機助手的發佈向行業展示,當大模型擁有足夠數據與參數時,其在 GUI 上的擬人化表現可令人驚歎。然而,現階段的端側智能體(包括豆包、AutoGLM 等)在面對未見過的複雜場景時,成功率仍會明顯下降。要讓 AI 手機從“嚐鮮”走向“常用”,除了堆疊數據,我們必須在智能體的 泛化性、自主性與長程性 這三個維度上實現機制級突破。

智能體的三大挑戰
長程性指的是人類使用手機完成任務往往是跨越多個 APP、持續數分鐘甚至數小時的長程交互。例如,“幫我基於這周郵件往來規劃差旅日程並預訂機酒”。這不僅需要跨應用操作,更要求智能體在漫長操作鏈中始終保持對核心目標的專注,不因中間彈窗或無關信息而“迷路”。目前的大模型受限於上下文窗口,往往“健忘”。隨着交互步驟增加,關鍵信息(如出發日期、預算上限)易丟失或被稀釋。真正的長程性需突破上下文窗口限制,引入類人的記憶架構:智能體應能自主決定將哪些關鍵信息寫入長期記憶,哪些保留在工作記憶,並主動遺忘干擾決策的噪音數據,確保在長鏈操作中始終保持目標聚焦。
泛化性指的是智能體在沒有見過的任務上的勝任程度。當前 GUI Agent(如 UI‑TARS)的能力很大程度上依賴於雲側大模型見過的海量 APP 界面截圖與操作軌跡,本質是“基於經驗的泛化”。然而,真實移動互聯網環境高度碎片化且動態變化:APP 每日更新,界面佈局可能進行 A/B 測試,同一 APP 在不同機型上的渲染也不同。若僅依賴雲側模型“背題庫”式訓練,一旦遇到小眾 APP 或新版本界面,智能體便會癱瘓。未來的自主智能需具備 零樣本泛化能力。這意味着智能體應像人類一樣,通過理解 GUI 設計的通用語言(如放大鏡代表搜索)與業務邏輯,在從未見過的全新 APP 中通過自主探索學會使用工具。這要求模型不再簡單記憶像素位置,而是構建對數字世界的“世界模型”,理解操作與環境反饋間的因果關係,從而以更小參數規模實現對陌生環境的適應。
自主性指的是智能體應對動態環境的魯棒性與自我修正的能力。真實端側環境遠比沙盒模擬器複雜。網絡延遲、營銷彈窗、系統權限攔截、頁面加載失敗皆是常態。目前的 Agent 多采用線性“觀察‑思考‑行動”鏈路,一旦某步執行失敗(如網絡卡頓彈出重試窗口、優惠券領取失敗、廣告遮擋),智能體常因環境狀態與預期不符而直接報錯中止。真正擁有自主性的未來自主智能體應具備“反思”機制:
(1)執行驗證:每執行一步後,自主驗證環境反饋是否符合預期;
(2)錯誤恢復:遇到非預期狀態(如誤觸廣告進入第三方頁面)時,具備“回退”與“重新規劃”能力,甚至能通過探索性操作找到新路徑,而非機械請求人類接管。只有具備這種能力,用户才敢真正放心地將手機交給智能體處理充滿不確定性的複雜任務。
上述三大能力的實現,本質上都依賴於同一個底層邏輯——智能體必須在與動態環境的交互中不斷學習和優化。單純的監督微調(SFT)只能模仿人類已有的軌跡,而無法應對未知的變化。因此,自主強化學習 是下一代智能體的核心引擎。在這方面,我們團隊的PRIME工作 [8] 將強化學習與過程獎勵模型相結合,讓智能體不僅關注最終結果,更能獲得每一步推理過程的細粒度反饋,大幅提升了複雜邏輯任務的訓練效率。在此基礎上,團隊的 AgentCPM-GUI、字節的 UI-TARS及智譜的 AutoGLM 均驗證了利用強化學習在 GUI 場景下進行大規模探索學習對GUI Agent 泛化性、自主性提升的有效性。
總的來説,如果豆包手機助手當前的能力來自“讀萬卷書”(海量數據訓練),那麼下一階段的自主智能則需要智能體學會“行萬里路”(在動態環境中自主探索與適應)。只有攻克泛化性、自主性和長程性三大難題,AI 手機才能從“聽話的執行者”進化為真正“可信賴的智能助手”。
主動智能:個性化助手的必備能力
從人機交互視角看,個人助手是否真正具備“輔助價值”,不取決於其功能數量或技術複雜度,而取決於一個核心標準:用户為指導智能體完成任務所付出的精力,必須顯著小於用户親自完成該任務所需的精力。一旦條件不成立,智能體便會從“助手”退化為“負擔”。
目前的豆包手機助手等端側智能體仍遵循“用户下令‑智能體執行”的被動範式。這導致用户在執行復雜任務(如“幫我規劃週末去環球影城的行程”)時面臨巨大認知負荷——需像填表一樣依次確認出發時間、交通偏好、酒店預算和必玩項目。一旦交互成本超過直接操作 APP 的成本,智能體便成為“累贅”。因此,合格的個性化助手必須具備在 最少用户輸入 條件下完成任務的能力。我們認為,下一代端側智能必須完成從 “被動響應”到“主動智能” 的範式躍遷。所謂主動智能,並非簡單“多做事”,而是指智能體能在不頻繁打擾用户的前提下,持續感知環境、積累歷史經驗,並基於這些信息對用户的潛在需求進行預測和準備。
第一,從“被動指令執行”到“主動意圖預測” 。當前助手多停留在字面解析階段,依賴用户給出完整、明確的提示詞。真正的個性化助手需具備“讀心”能力,即基於端側積累的歷史行為、偏好演化及當前環境狀態(時間、位置、屏幕內容),構建高精度用户畫像。智能體不再被動等待喚醒,而是持續在後台進行環境感知與推理。例如,當用户週五晚上搜索“周邊遊”時,模型應結合歷史數據自動識別“喜歡安靜、預算中等、帶寵物”的隱式約束,直接過濾嘈雜的熱門景點。這種從“只聽你説什麼”到“懂你沒説什麼”的跨越,是智能體建立用户信任的基石。
第二,從“分步指導交互”到“預先填充確認” 。為解決“教 AI 做事太累”的痛點,交互必須從費力的“填空題”轉變為輕鬆的“選擇題”。主動智能體基於意圖預判,能自動生成含關鍵參數的預填充指令。例如,在用户打開打車軟件的瞬間,智能體根據日程與當前時間,直接彈出“打車去公司,預計 30 元”的建議卡片。用户只需點擊“確認”,無需手動輸入目的地。這種機制將用户認知負擔從高強度“指導”降至低強度“審閲”。同時,主動性必須嚴守“剋制”原則:僅當預測置信度極高或對用户價值顯著時才主動介入,確保智能體是“默契的伴侶”而非“打擾的彈窗”。
在端側實現這種高水平的主動智能並非遙不可及。我們的研究團隊在 Proactive Agent [6]工作中驗證了其技術可行性。針對主動服務缺乏訓練數據的難題,我們創新構建環境模擬器,通過模擬用户在代碼編寫、文章寫作、智能家居等場景下的交互序列,生成大規模“用户‑環境”交互數據集。實驗證明,基於此數據訓練的端側模型能敏鋭捕捉用户隱式意圖。這表明我們完全有能力在端側打造出具備深度洞察力的下一代個人助手。
綜上所述,主動智能不是個性化助手的“加分項”,而是其走向實用與可信的 基礎能力。只有當智能體能夠以更低交互成本承擔更多決策前與執行中的工作,個人助手才能真正從“會對話的工具”進化為“值得依賴的協作者”。
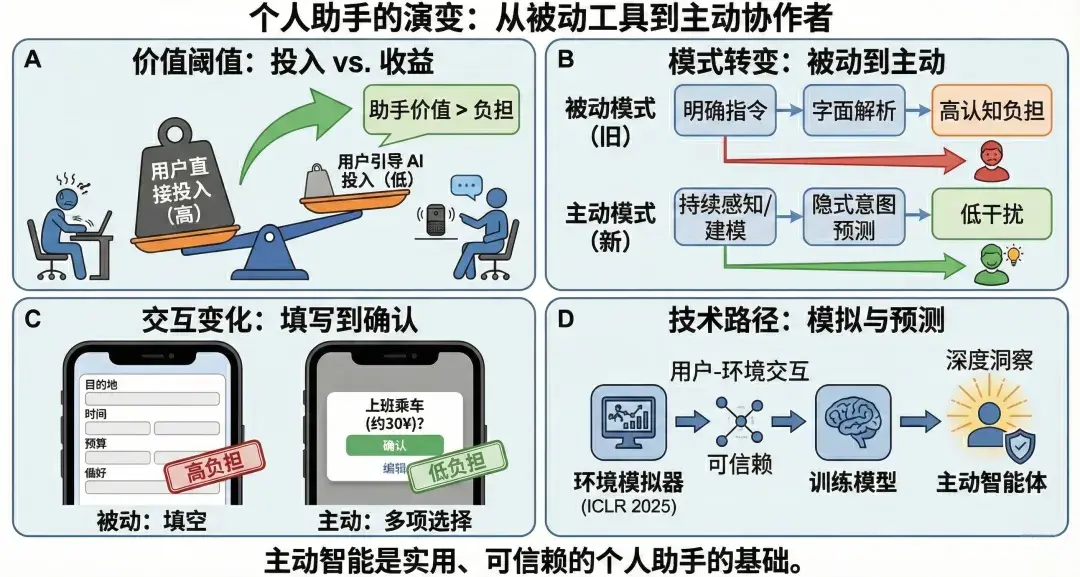
主動智能:從被動響應到主動服務(由 Gemini 生成)
未來展望:手機助手與端側智能體
基於技術成熟度與市場動態,我們對未來短期、中期及長期的行業格局做出如下研判:
在短期(1年內),我們判斷更多手機助手將上市,應用與 OS 的博弈加劇。目前,字節(UI‑TARS)、智譜(AutoGLM)、面壁(AgentCPM‑GUI)等團隊已證明 GUI Agent 具備商業化落地基礎。未來幾個月,我們將看到更多手機助手上市,“軟硬對抗”將全面爆發:互聯網大廠試圖通過“應用層 OS 化”保住流量入口;手機廠商則必會死守 OS 底層權限,推出自研系統級智能體以捍衞主場。這種利益衝突將引發劇烈對抗:應用廠商可能通過加密傳輸、動態 UI 渲染等技術手段,對抗 GUI Agent 的視覺讀取與模擬點擊。傳統 Web 端的“爬蟲與反爬蟲”對抗將在移動終端 GUI 層面重演。此階段競爭將極其激烈,但也會反向推動技術能力爆發式增長。
而到中期(2~3年),自主學習能力將走向成熟,持續成長的“個人專屬助手”形態會逐漸確立。在基礎功能需求滿足後,智能助手真正的差異化壁壘在於 “個性化”。雲側大模型雖強,卻是“千人一面”的通用專家;唯有端側模型能近距離接觸用户全量數據。我們判斷,隨着端側模型測試時學習技術的成熟,智能助手將從“靜態工具”進化為“持續成長的個人專屬助手”。它能基於用户歷史行為數據持續自我迭代——知道你點咖啡的糖度偏好,熟悉你打車時的常用路線。這種“越用越聰明、越用越懂你”的特性只能由端側模型實現,並將成為用户無法遷移的體驗壁壘。
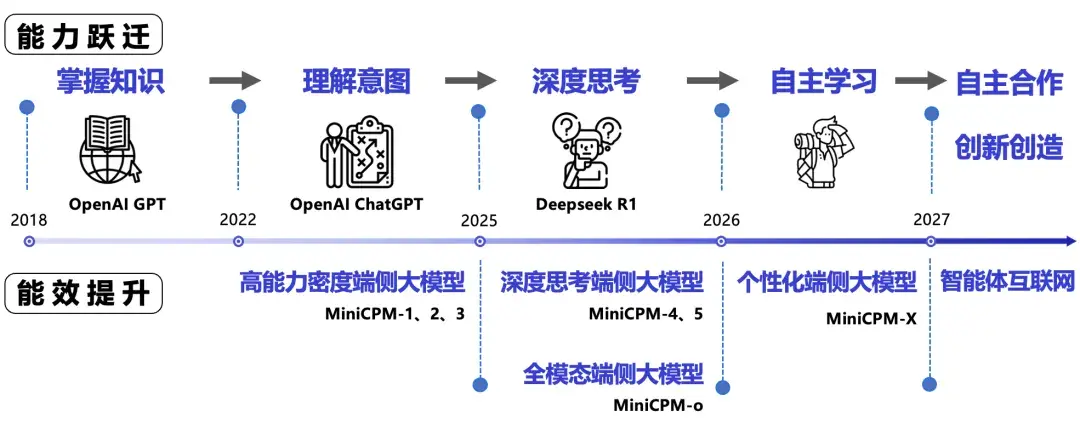
大模型高效發展道路:能力躍遷,能效提升
放眼長期(3‑5 年),端雲協同架構走向終局,AGI 時代的新型端側硬件形態涌現。高隱私操作(聊天、支付、相冊)與高頻輕量任務(定鬧鐘、調亮度)完全由端側模型執行,形成本地閉環,確保數據主權與毫秒級響應。端側算力無法解決的超複雜推理,或需連接廣泛互聯網服務的需求(如“全網比價並下單”),則在用户顯式授權與脱敏後路由至雲側專家模型處理。隨着端側智能與雲側智能深度融合,用户對終端的交互將不再侷限於屏幕,更自然的語音、手勢交互將催生 AGI 時代的新硬件形態。手機可能不再是唯一載體,以智能座艙、AI 眼鏡為代表的新型端側硬件將涌現,承載 AGI 時代的個人助理功能。

AGI 時代必將出現新型智能硬件
結語
豆包手機助手的出現,如同一面鏡子,既映照出 GUI Agent 從實驗室走向實用的技術跨越,也折射出端側智能在隱私、泛化與交互範式上的現實挑戰。它告訴我們:大模型若想真正融入每個人的數字生活,就不能只停留在“對話”,而必須學會“行動”;不能只依賴“雲端”,而必須紮根“端側”。而在互聯網應用市場資源高度整合、手機等硬件巨頭格局森然的當下,創新的出現必然不會一蹴而就,新玩家的入局也必定舉步維艱。我們看到在過去半個月中,一個個 APP 被字節跳動官方宣佈不再被豆包手機助手所支持,用户們最開始的興奮感也逐步消退。然而,現在這並不是結束,甚至不是結束的開始。但,這或許是開始的結束。
OpenBMB 社區長期關注大模型的普惠化發展,MiniCPM 系列端側大模型正是在端側智能的思路牽引下應運而生。目前,MiniCPM 系列端側大模型已經在最具落地條件的智能座艙等領域紮根發展。智能座艙不僅需要毫秒級的響應速度來處理導航、安全預警和娛樂系統,更需要深度學習用户習慣,實現無縫的個性化服務,並對數據隱私和安全性有極高的要求。而在未來,隨着芯片算力的不斷演進、大模型能力密度的不斷增強,AIPC、手機助手乃至具身機器人的智能應用場景都將陸續成熟,端側智能將會成為驅動智能硬件發展的越來越重要的動力,豆包手機助手的下一個形態也將會不再受到如今的質疑和困擾,迎來新生。
未來已來,路仍漫長。從被動執行到主動服務,從單一模態到全息感知,從固定規則到自主進化——端側智能的每一次突破,都將使我們離那個“懂你、護你、助你”的個人超級助手更近一步。這不僅是技術的競賽,更是對信任、隱私與人本價值的迴歸。我們相信,當智能最終在每個人掌心安全、高效且體貼地運行時,那才是人工智能真正閃耀的時刻。
➤ 參考文獻
[1] Chen, Wentong, et al. "GUICourse: From General Vision Language Model to Versatile GUI Agent." Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025.
[2] Zhang, Zhong, et al. "AgentCPM-GUI: Building Mobile-Use Agents with Reinforcement Fine-Tuning." Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. 2025: 155–180.
[3] Song, Chenyang, et al. "BlockFFN: Towards End-Side Acceleration-Friendly Mixture-of-Experts with Chunk-Level Activation Sparsity." Second Conference on Language Modeling.
[4] Zhao, Weilin, et al. "Infllm-v2: Dense-sparse switchable attention for seamless short-to-long adaptation." arXiv preprint arXiv:2509.24663 (2025).
[5] Guo, Zonghao, et al. "Llava-uhd: an lmm perceiving any aspect ratio and high-resolution images." European Conference on Computer Vision. Cham: Springer Nature Switzerland, 2024.
[6] Lu, Yaxi, et al. "Proactive Agent: Shifting LLM Agents from Reactive Responses to Active Assistance." The Thirteenth International Conference on Learning Representations.
[7] Xiao, C., Cai, J., Zhao, W. et al. Densing law of LLMs. Nat Mach Intell7, 1823–1833 (2025).
[8] Cui, Ganqu, et al. "Process reinforcement through implicit rewards." arXiv preprint arXiv:2502.01456 (2025).
