谷歌宣佈其 AI 模型 Gemini 3 Flash 增加了一個全新的視覺能力模塊 Agentic Vision,旨在讓模型在處理圖像時更像人類專家,而不是靜態“看一眼就猜”。

過去的大多數 AI 視覺模型都是“靜態看圖”:它們接收一張圖片,試着一次性理解內容。但這樣做,若遇到細節極小、信息密集的視覺任務(比如識別微小字符、遠處標誌等),結果往往不夠精確。
Agentic Vision 的核心創新在於引入了一種類似調查式的視覺分析流程 — 讓模型像工程師一樣“思考→操作→觀察”,從而依據視覺證據得出更可靠的結論。
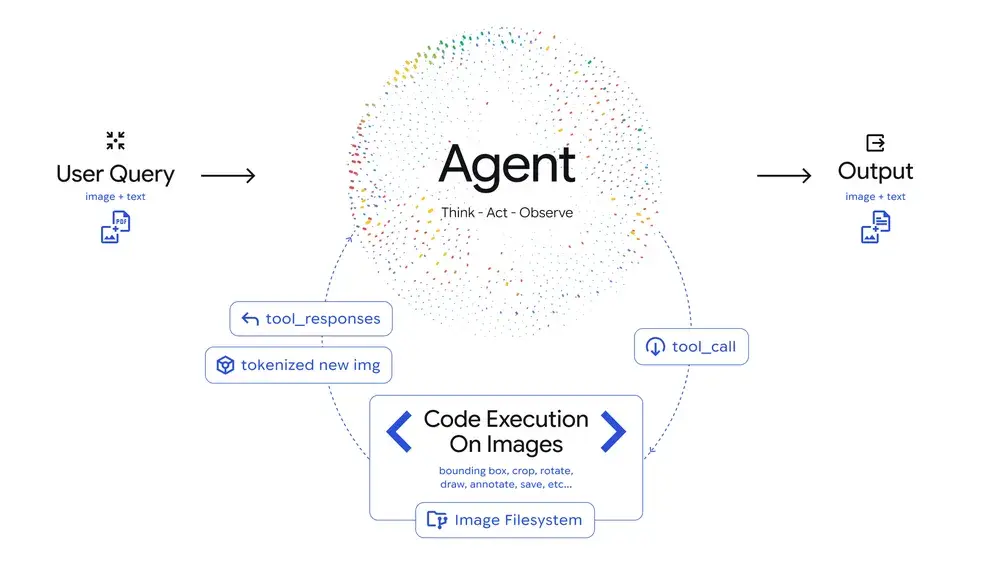
-
Think(思考):模型根據用户提問和初始圖像制定一個多步驟分析計劃。
-
Act(執行):通過自動生成並執行 Python 代碼,模型對圖像進行剪裁、旋轉、標註、計數等操作。
-
Observe(觀察):處理後的圖像被加入上下文,模型在新的視角下重新分析並回答。
這種“看 → 處理 → 再看”的循環式分析,讓 Gemini 在視覺任務的準確性上平均提升 5–10%。
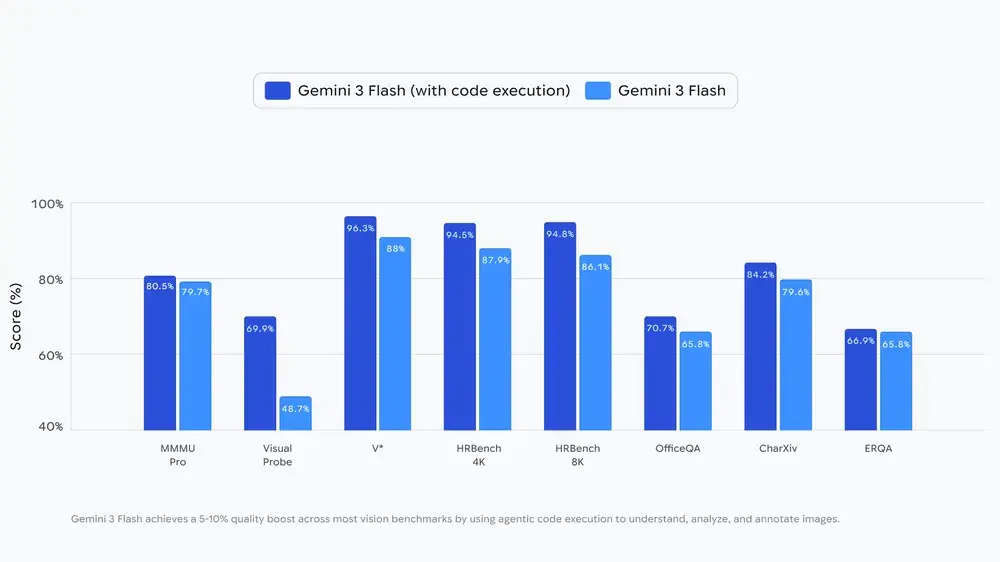
目前 Agentic Vision 能力已經在 Gemini AI Studio、Vertex AI 中通過 Gemini API 提供,未來也將陸續在 Gemini App 的“Thinking 模式”中對用户開放。開發者只需在工具裏啓用“Code Execution”(代碼執行)功能即可調動這個能力。
