國內AI領域最知名的教授之一 —— 復旦大學計算機學院教授邱錫鵬和他學生創立的公司近期發佈了MOSS-Speech,聲稱是真正的語音到語音(Speech-to-Speech)大模型。

據官方介紹,這款模型標誌着國產AI邁入了“真語音到語音交互”的新階段。它與傳統“語音識別—文本生成—語音合成”的級聯方案不同,MOSS-Speech 實現了直接從語音理解到語音生成,無需文本中介。該模型可在生成回答的同時捕捉語調、情緒、笑聲等非文字信號,使機器“説話”更自然、更具人性。
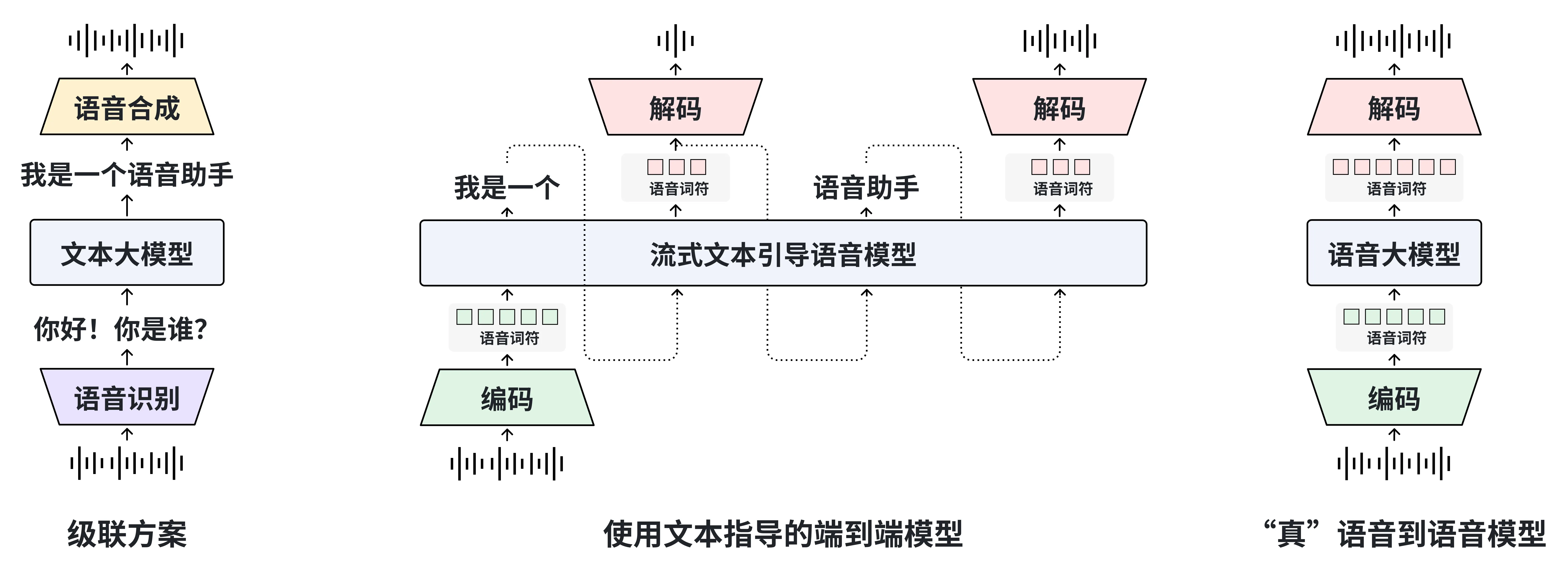
MOSS-Speech 核心特性如下:
- 真正的語音到語音建模:無需文本引導。
- 層拆分架構:在預訓練文本 LLM 的基礎上新增模態特定層。
- 凍結預訓練策略:在保留原 LLM 的能力的同時引入語音理解和生成能力。
- SOTA性能:在語音問答和語音到語音任務中表現出色。
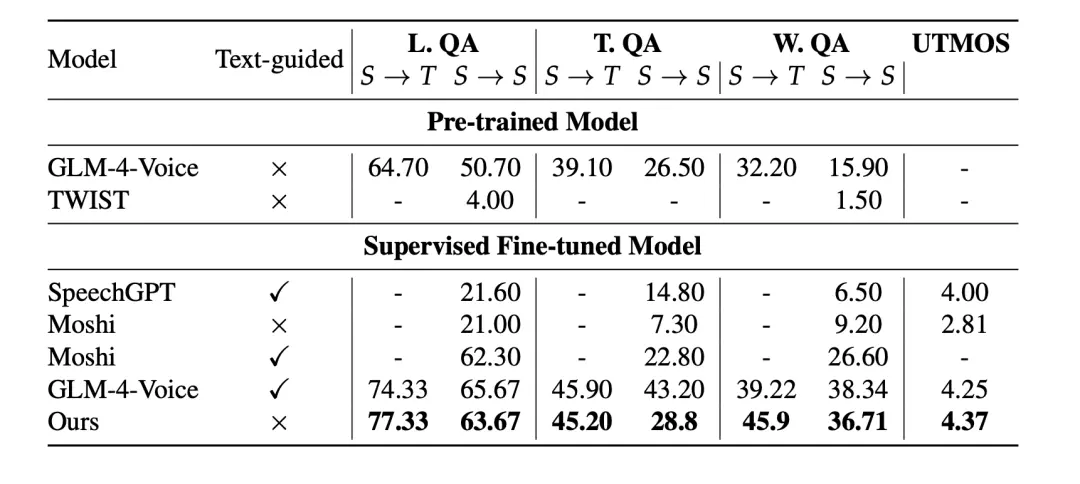
MOSS-Speech 在語音到語音評測指標上取得了 SOTA 成績。
- 預訓練模型評測結果

- 指令微調模型評測結果
更多細節查看 Demo 和技術報告
- 視頻 Demo:https://moss-speech.open-moss.com/
- 在線 Demo:https://huggingface.co/spaces/fnlp/MOSS-Speech
- GitHub 主頁:https://github.com/OpenMOSS/MOSS-Speech
- 技術報告:https://github.com/OpenMOSS/MOSS-Speech/blob/main/papers/MOSS-Speech Technical Report.pdf
