作者:來自 Elastic Kirti Sodhi
學習如何利用LangChain和Elasticsearch構建一個代理性Rag新聞助手,用自適應路由回答關於文章的查詢。
《Agent Builder》現已作為技術預覽版上線。開始 Elastic Cloud 試用,並查看 Agent Builder 的文檔。
這篇博客深入探討了 agentic RAG 工作流,解釋了它們的關鍵特性和常見設計模式。它進一步展示瞭如何通過一個使用 Elasticsearch 作為向量存儲、使用 LangChain 構建 agentic RAG 框架的實踐示例來實現這些工作流。最後,文章簡要討論了設計和實現此類架構的最佳實踐和相關挑戰。你可以通過這個Jupyter notebook跟着一起創建一個簡單的 agenticRAG管道。
Agentic RAG 簡介
檢索增強生成(RAG)已成為基於 LLM 的應用程序的基石,它通過根據用户查詢檢索相關上下文,使模型能夠提供最佳答案。RAG 系統通過利用來自 API 或數據存儲的外部信息來增強 LLM 響應的準確性和上下文,而不是受限於預訓練 LLM 的知識。另一方面,AI agents 能夠自主運行,做出決策並採取行動以實現其既定目標。
Agentic RAG 是一個將檢索增強生成和 agentic 推理優勢統一起來的框架。它將 RAG 集成到 agent 的決策過程中,使系統能夠動態選擇數據源、優化查詢以獲得更好的上下文檢索、生成更準確的響應,並應用反饋循環來持續改進輸出質量。
Agentic RAG 的關鍵特性
Agentic RAG 框架是對傳統 RAG 系統的一次重大提升。它不是遵循固定的檢索流程,而是利用能夠實時規劃、執行和優化結果的動態 agents。
下面來看一些使 agentic RAG 管道與眾不同的關鍵特性:
- 動態決策:agentic RAG 使用推理機制來理解用户意圖,並將每個查詢路由到最相關的數據源,從而生成準確且具有上下文意識的響應。
- 全面的查詢分析:agentic RAG 深入分析用户查詢,包括子問題及其整體意圖。它評估查詢的複雜性,並動態選擇最相關的數據源來檢索信息,以確保響應準確且完整。
- 多階段協作:該框架通過一個專業 agents 網絡實現多階段協作。每個 agent 處理一個更大目標中的特定部分,可以順序或同時工作,以實現統一的結果。
- 自我評估機制:agentic RAG 管道使用自我反思來評估檢索到的文檔和生成的響應。它可以檢查檢索的信息是否完全回答了查詢,然後審核輸出的準確性、完整性和事實一致性。
- 與外部工具集成:該工作流可以與外部 API、數據庫和實時信息源交互,整合最新信息並根據不斷變化的數據動態適應。
Agentic RAG 的工作流模式
這些工作流模式定義了 agentic AI 如何以可靠且高效的方式構建、管理和編排基於 LLM 的應用程序。LangChain、LangGraph、CrewAI和LlamaIndex等多個框架和平台都可以用來實現這些 agentic 工作流。
- 順序檢索鏈:順序工作流將複雜任務拆分為簡單且有序的步驟。每一步都會改進下一步的輸入,從而得到更好的結果。例如,在創建客户檔案時,一個 agent 可能從 CRM 中提取基本信息,另一個從交易數據庫中檢索購買歷史,最後一個 agent 將這些信息合併,生成用於推薦或報告的完整檔案。
- 路由檢索鏈:在這種工作流模式中,一個路由 agent 會分析輸入並將其指向最合適的流程或數據源。當存在多個彼此重疊很少的不同數據源時,這種方法特別有效。例如,在客户服務系統中,路由 agent 會對接收到的請求進行分類,如技術問題、退款或投訴,並將其路由到適當的部門以高效處理。
- 並行檢索鏈:在這種工作流模式中,多個獨立的子任務會同時執行,隨後它們的輸出會被聚合來生成最終響應。這種方法能顯著減少處理時間並提高工作流效率。例如,在客户服務的並行工作流中,一個 agent 檢索類似的歷史請求,另一個諮詢相關的知識庫文章。一個聚合器隨後將這些輸出合併,以生成全面的解決方案。
- 編排者—工作者鏈:這種工作流由於利用了獨立子任務,與並行化相似。然而一個關鍵區別在於其引入了一個編排者 agent。這個 agent 負責分析用户查詢,在運行時動態地將其分解為子任務,並識別生成準確響應所需的合適流程或工具。

從零構建一個 agentic RAG 管道
為了説明 agentic RAG 的原理,我們來設計一個使用 LangChain 和 Elasticsearch 的工作流。該工作流採用基於路由的架構,多個 agents 協同工作來分析查詢、檢索相關信息、評估結果並生成連貫的響應。你可以參考這個Jupyter notebook跟着示例操作。
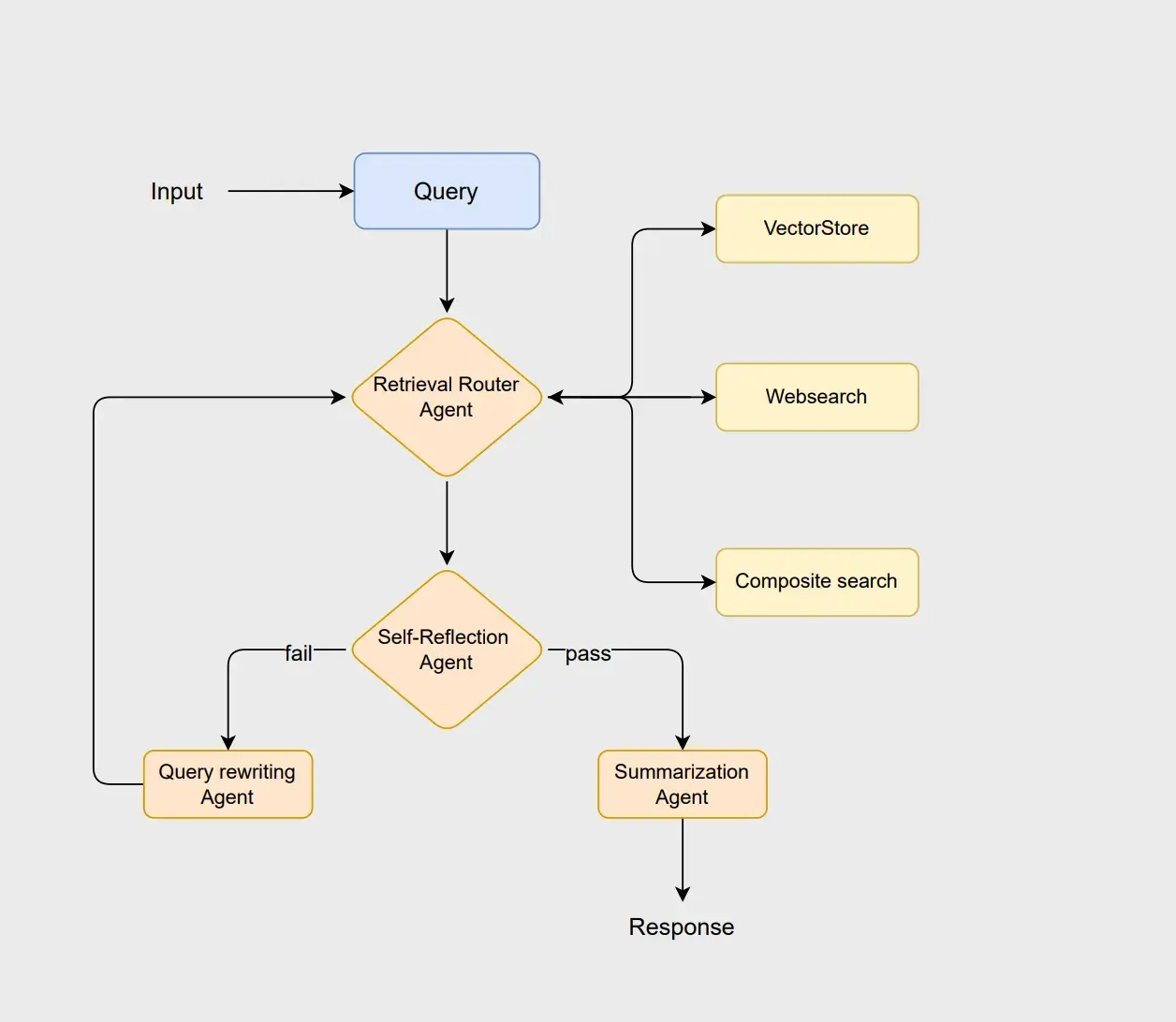
工作流從 router agent 開始,該 agent 分析用户的查詢以選擇最優的檢索方法,即使用 vectorstore 、 websearch 或 composite 方法。 vectorstore 負責傳統基於 RAG 的文檔檢索, websearch 獲取未存儲在 vectorstore 中的最新信息,而 composite 方法在需要來自多個來源的信息時將兩者結合。
如果文檔被認為合適, summarization agent 會生成清晰且符合上下文的響應。然而,如果文檔不足或不相關, query rewriting agent 會重寫查詢以改進搜索。然後該修訂後的查詢會重新啓動路由流程,使系統能夠改進搜索並提升最終輸出質量。
先決條件
此工作流依賴以下核心組件來有效執行示例:
- Python 3.10
- Jupyter notebook
- Azure OpenAI
- Elasticsearch
- LangChain
在繼續之前,你會被提示為此示例配置以下所需的環境變量。
AZURE_OPENAI_ENDPOINT="Add your azure openai endpoint" AZURE_OPENAI_KEY="Add your azure openai key" AZURE_OPENAI_DEPLOYMENT="gpt-4.1" AZURE_OPENAI_API_VERSION="Add your azure openai api version" ES_ENDPOINT = "Add your Elasticsearch ENDPOINT" ES_API_KEY = "Add your Elasticsearch API KEY"
數據源
此工作流使用 AG News 數據集的一個子集進行演示。該數據集包含來自多個類別的新聞文章,如 International、Sports、Business 和 Science/Technology。
dataset = load_dataset("ag_news", split="train[:1000]")
docs = [
Document(
page_content=sample["text"],
metadata={"category": sample["label"]}
)
for sample in dataset
]
我們使用 langchain_elasticsearch 的ElasticsearchStore 模塊作為向量存儲。在檢索時,我們實現了 SparseVectorStrategy ,使用 ELSER,這是 Elastic 的專有嵌入模型。在啓動向量存儲之前,必須確認 ELSER 模型已在你的 Elasticsearch 環境中正確安裝和部署。
elastic_vectorstore = ElasticsearchStore.from_documents(
docs,
es_url=ES_ENDPOINT,
es_api_key=ES_API_KEY,
index_name=index_name,
strategy=SparseVectorStrategy(model_id=".elser_model_2"),
)
elastic_vectorstore.client.indices.refresh(index=index_name)
Web 搜索功能使用 LangChain 社區工具中的DuckDuckGoSearchRun實現,它允許系統高效地從網絡檢索實時信息。你也可以考慮使用其他可能提供更相關結果的搜索 API。選擇此工具的原因是它允許無需 API key 即可進行搜索。
duckduckgo = DuckDuckGoSearchRun(description= "A custom DuckDuckGo search tool for finding latest news stories.", verbose=True)
def websearch_retriever(query):
results = duckduckgo.run(f"{query}")
return results
Composite retriever 設計用於需要組合多種來源的查詢。它通過同時從網絡檢索實時數據和從向量存儲查詢歷史新聞,提供全面且符合上下文的準確響應。
def composite_retriever(query):
related_docs = vectorstore_retriever(query)
related_docs += websearch_retriever(query)
return related_docs
設置 agents
下一步,定義 LLM agents,以在該工作流中提供推理和決策能力。我們將創建的 LLM chains 包括: router_chain 、 grade_docs_chain 、 rewrite_query_chain 和 summary_chain 。
router agent 使用 LLM assistant 來在運行時確定給定查詢的最合適數據源。grading agent 評估檢索到的文檔的相關性。如果文檔被認為相關,它們會被傳遞給 summary agent 生成摘要。否則,rewrite query agent 會重寫查詢並將其發送迴路由流程進行另一輪檢索。你可以在notebook的 LLM chains 部分找到所有 agents 的説明。
class RouteQuery(BaseModel):
datasource: Literal["vectorstore", "websearch", "composite"] = Field(
...,
description="Choose to route the query to web search, vectorstore or composite."
)
router_prompt = ChatPromptTemplate.from_template("""You are an assistant that decides the best data source for questions based on news articles.
Choose one of the following options:
- 'vectorstore': for general, background, or historical news articles.
- 'websearch': for recent discoveries, 'latest', 'current', or '2025' type queries.
- 'composite': when the question needs both historical and current knowledge on news articles.
Question: {query}
Return one word: 'vectorstore', 'websearch', or 'composite'.
""")
router_structured = llm.with_structured_output(RouteQuery)
router_chain: RunnableSequence = router_prompt | router_structured
llm.with_structured_output 將模型的輸出限制為遵循 RouteQuery 類下 BaseModel 定義的預定義 schema,確保結果的一致性。第二行通過將 router_prompt 與 router_structured 連接,組成一個 RunnableSequence ,形成一個管道,其中輸入的 prompt 會被語言模型處理,以生成結構化、符合 schema 的結果。
定義圖節點
這一部分涉及定義圖的狀態,這些狀態表示系統不同組件之間流動的數據。清晰地指定這些狀態可以確保工作流中的每個節點都知道它可以訪問和更新哪些信息。
class RAGState(TypedDict):
query: str
docs: List[Document]
router: str
summary: str
self_reflection: bool
retry_count: int = 0
在定義狀態之後,下一步是定義圖的節點。節點就像圖的功能單元,對數據執行特定操作。我們的管道中有 7 個不同的節點。
def router(state: RAGState):
router = router_chain.invoke({'query': state["query"]})
logger.info(f"Router selected the datasource: {router.datasource}")
logger.info(f"User query: {state['query']}")
return {"router": router.datasource}
def vectorstore(state: RAGState):
return {"docs": vectorstore_retriever(state["query"])}
def websearch(state: RAGState):
return {"docs": websearch_retriever(state["query"])}
def composite(state: RAGState):
return {"docs": composite_retriever(state["query"])}
def self_reflection(state: RAGState):
evaluation = grade_docs_chain.invoke(
{"query": state["query"], "docs": state["docs"]}
)
if evaluation.binary_score:
logger.info(f"Self-reflection passed -- binary_score={evaluation.binary_score}")
else:
logger.info(f"Self-reflection failed -- binary_score={evaluation.binary_score}")
return {
"self_reflection": evaluation.binary_score,
}
def query_rewriter(state: RAGState):
retry_count = state.get("retry_count", 0) + 1
new_query = rewrite_query_chain.invoke({"query": state["query"]})
logger.info(f"Query rewritten: {new_query}, retry_count: {retry_count}")
return {
"query": new_query,
"retry_count": retry_count,
}
def summarize(state: RAGState):
summary = summarize_chain.run(
query=state["query"],
docs=state["docs"],
)
return {"summary": summary}
query_rewriter 節點在工作流中有兩個作用。首先,當 self-reflection agent 評估的文檔被認為不足或不相關時,它使用 rewrite_query_chain 重寫用户查詢以改進檢索。其次,它作為一個計數器,跟蹤查詢被重寫的次數。
每次調用該節點時,會增加存儲在工作流狀態中的 retry_count 。此機制防止工作流進入無限循環。如果 retry_count 超過預定義閾值,系統可以回退到錯誤狀態、默認響應或你選擇的任何其他預定義條件。
編譯圖
最後一步是定義圖的邊並在編譯之前添加必要的條件。每個圖必須從指定的起始節點開始,該節點作為工作流的入口點。圖中的邊表示節點之間的數據流,可以分為兩種類型:
- 直線邊:定義從一個節點到另一個節點的直接、無條件流。當第一個節點完成任務後,工作流會沿着直線邊自動繼續到下一個節點。
- 條件邊:允許工作流根據當前狀態或節點計算結果進行分支。下一個節點會根據條件動態選擇,例如評估結果、路由決策或重試次數。
graph.add_edge(START, "router")
def after_router(state: RAGState):
route = state.get("router", None)
if route == "vectorstore":
return "vectorstore"
elif route == "websearch":
return "websearch"
else:
return "composite"
def after_self_reflection(state: RAGState):
if state["self_reflection"]:
return "summarize"
return "query_rewriter"
def after_query_rewriter(state: RAGState):
while state['retry_count'] <= 3:
return "router"
raise RuntimeError("Maximum retries (3) reached -- evaluation failed.")
graph.add_conditional_edges(
"router",
after_router,
{
"vectorstore": "vectorstore",
"websearch": "websearch",
"composite": "composite"
}
)
graph.add_edge("vectorstore", "self_reflection")
graph.add_edge("websearch", "self_reflection")
graph.add_edge("composite", "self_reflection")
graph.add_conditional_edges(
"self_reflection",
after_self_reflection,
{
"summarize": "summarize",
"query_rewriter": "query_rewriter"
}
)
graph.add_conditional_edges("query_rewriter", after_query_rewriter, {"router": "router"})
graph.add_edge("summarize", END)
agent=graph.compile()
至此,你的第一個 agentic RAG 管道已準備就緒,可以使用已編譯的 agent 進行測試。
result = agent.invoke({"query": query1})
logger.info(f"\nFinal Summary:\n: {result['summary']}")
測試 agentic RAG 管道
我們現在將使用以下三種不同類型的查詢來測試此管道。注意,結果可能會有所不同,下列示例僅展示一種可能的結果。
query1="What are the latest AI models released this month?" query2="What technological innovations are discussed in Sci/Tech news?" query3="Compare a Sci/Tech article from the dataset with a current web article about AI trends."
對於第一個查詢,router 選擇 websearch 作為數據源。該查詢未通過 self-reflection 評估,隨後被重定向到 query rewriting 階段,如輸出所示。
INFO | __main__:router:11 - Router selected the datasource: websearch INFO | __main__:router:12 - User query: What are the latest AI models released this month? INFO | __main__:self_reflection:31 - Self-reflection failed -- binary_score=False INFO | __main__:query_rewriter:40 - Query rewritten: query='Which AI models have been officially released in June 2024?', retry_count: 1 INFO | __main__:router:11 - Router selected the datasource: websearch INFO | __main__:router:12 - User query: query='Which AI models have been officially released in June 2024?' Dream Machine is a text-to-video model created by Luma Labs and launched in June 2024 . It generates video output based on user prompts or still images. Dream Machine has been noted for its ability to realistically capture motion... Released in June 2023. In June 2024 , Baidu announced Ernie 4.0 Turbo. In April 2025, Ernie 4.5 Turbo and X1 Turbo were released . These models are optimized for faster response times and lower operational costs.[28][29]. The meaning of QUERY is question, inquiry. How to use query in a sentence. Synonym Discussion of Query. QUERY definition: 1. a question, often expressing doubt about something or looking for an answer from an authority.... Learn more. Query definition: a question; an inquiry.. See examples of QUERY used in a sentence. INFO | __main__:self_reflection:29 - Self-reflection passed -- binary_score=True INFO | __main__:<module>:2 - Final Summary: : In June 2024, two AI models were officially released: Dream Machine, a text-to-video model launched by Luma Labs, and Ernie 4.0 Turbo, announced by Baidu, which is optimized for faster response times and lower operational costs.
接下來,我們來看一個使用 vectorstore 檢索的示例,通過第二個查詢演示。
INFO | __main__:router:11 - Router selected the datasource: vectorstore INFO | __main__:router:12 - User query: What technological innovations are discussed in Sci/Tech news? INFO | __main__:self_reflection:29 - Self-reflection passed -- binary_score=True INFO | __main__:<module>:2 - Final Summary: : Recent Sci/Tech news highlights several technological innovations: NASA is collaborating with Silicon Valley firms to build a powerful Linux-based supercomputer to support theoretical research and shuttle engineering; new chromatin transfer techniques have enabled the cloning of cats; cybersecurity advancements are being discussed in relation to protecting personal technology; Princeton University scientists assert that existing technologies can be used immediately to stabilize global warming; and a set of GameBoy micro-games has been recognized for innovation in game design.
最後的查詢被引導到 composite retrieval,該方法同時使用 vectorstore 和 web search。
INFO | __main__:router:11 - Router selected the datasource: composite INFO | __main__:router:12 - User query: Compare a Sci/Tech article from the dataset with a current web article about AI trends. Atlas currently only available on macOS, built on Chromium with planned features like ad-blocking still in development. OpenAI's Atlas browser launched with bold promises of AI -powered web browsing, but early real-world testing reveals a different story. Career-long data are updated to end-of-2024 and single recent year data pertain to citations received during calendar year 2024. The selection is based on the top 100,000 scientists by c-score (with and without self-citations) or a percentile rank of 2% or above in the sub-field. In this article I list 45 AI tools across 21 different categories. After exploring all the available options in each category, I've carefully selected the best tools based on my personal experience. Reading a complex technical article ? Simply highlight confusing terminology and ask "what's this?" to receive instant explanations. compare browsers. Comparison showing traditional browser navigation versus OpenAI Atlas AI -powered workflows. After putting Gemini, ChatGPT, Grok, and DeepSeek through rigorous testing in October 2025, it's clear that there isn't one AI that reigns supreme across all categories. INFO | __main__:self_reflection:29 - Self-reflection passed -- binary_score=True INFO | __main__:<module>:2 - Final Summary: : A Sci/Tech article from the dataset highlights NASA's development of robust artificial intelligence software for planetary rovers, aiming to make them more self-reliant and capable of decision-making during missions. In contrast, a current web article about AI trends focuses on the proliferation of AI-powered tools across various categories, including browsers like OpenAI Atlas, and compares leading models such as Gemini, ChatGPT, Grok, and DeepSeek, noting that no single AI currently excels in all areas. While the NASA article emphasizes specialized AI applications for autonomous robotics in space exploration, the current trends article showcases the broadening impact of AI across consumer and professional technologies, with ongoing competition and rapid innovation among major AI platforms.
在上述工作流中,agentic RAG 能智能地確定在檢索用户查詢信息時使用哪個數據源,從而提高響應的準確性和相關性。你可以創建更多示例來測試 agent 並查看輸出,以判斷是否產生有趣的結果。
構建 agentic RAG 工作流的最佳實踐
現在我們瞭解了 agentic RAG 的工作原理,讓我們來看一些構建這些工作流的最佳實踐。遵循這些指南可以幫助系統保持高效並易於維護。
- 準備回退方案:提前為工作流中任何步驟失敗的場景規劃回退策略。這些策略可以包括返回默認答案、觸發錯誤狀態或使用替代工具。這樣可以確保系統在遇到故障時仍能優雅處理,不破壞整體工作流。
- 實現全面日誌記錄:嘗試在工作流的每個階段實現日誌記錄,例如重試、生成輸出、路由選擇和查詢重寫。這些日誌有助於提高透明度、便於調試,並隨着時間推移優化 prompts、agent 行為和檢索策略。
- 選擇合適的工作流模式:根據你的用例選擇最適合的工作流模式。順序工作流適用於逐步推理, 並行工作流適用於獨立數據源,編排者—工作者模式適用於多工具或複雜查詢。
- 納入評估策略:在工作流的不同階段整合評估機制。這可以包括 self-reflection agents、對檢索文檔的評分或自動質量檢查。評估有助於驗證檢索文檔的相關性、響應的準確性以及複雜查詢的各個部分是否被覆蓋。
挑戰
雖然 agentic RAG 系統在適應性、精確性和動態推理方面具有顯著優勢,但在設計和實施階段也存在需要解決的挑戰。一些關鍵挑戰包括:
- 複雜工作流:隨着更多 agent 和決策點的加入,整體工作流變得越來越複雜,這可能導致運行時錯誤或失敗的概率增加。儘可能通過消除冗餘 agent 和不必要的決策點來優先簡化工作流。
- 可擴展性:將 agentic RAG 系統擴展以處理大型數據集和高查詢量可能具有挑戰性。需採用高效的索引、緩存和分佈式處理策略以保持規模下的性能。
- 編排和計算開銷:執行包含多個 agent 的工作流需要高級編排,包括仔細的調度、依賴管理和 agent 協作,以防止瓶頸和衝突,這些都會增加系統複雜性。
- 評估複雜性:評估這些工作流存在固有挑戰,每個階段都需要不同的評估策略。例如,RAG 階段需評估檢索文檔的相關性和完整性,而生成的摘要需檢查質量和準確性。同樣,查詢重寫的有效性需要單獨的評估邏輯來判斷重寫後的查詢是否改進了檢索結果。
結論
在這篇博客中,我們介紹了 agentic RAG 的概念,並強調了它通過引入 agentic AI 的自主能力增強了傳統 RAG 框架。我們探索了 agentic RAG 的核心特性,並通過一個實踐示例展示了這些特性 —— 使用 Elasticsearch 作為向量存儲,並用 LangChain 構建 agentic 框架,創建了一個新聞助手。
此外,我們討論了設計和實施 agentic RAG 管道時應考慮的最佳實踐和關鍵挑戰。這些見解旨在指導開發者創建穩健、可擴展且高效的 agentic 系統,有效結合檢索、推理和決策能力。
接下來
我們構建的工作流較為簡單,還有很大的改進和實驗空間。我們可以通過嘗試不同的嵌入模型和優化檢索策略來增強它。此外,集成一個 re-ranking agent 來優先排序檢索到的文檔可能會有幫助。另一個探索方向是為 agentic 框架開發評估策略,特別是識別可在不同類型框架中通用的常用方法。最後,可以在更大和更復雜的數據集上實驗這些框架。
與此同時,如果你有類似的實驗想分享,我們很樂意瞭解!歡迎通過我們的社區Slack 頻道或討論論壇提供反饋或交流。
資源
- Self-RAG: 通過自我反思學習檢索、生成和評估
- Agentic Retrieval-Augmented Generation: 關於 agentic RAG 的綜述
原文:https://www.elastic.co/search-labs/blog/agentic-rag-news-assistant-langchain-elasticsearch
