多家研究機構最新發布的 BabyVision 視覺推理基準結果顯示,當前最強多模態模型在視覺推理方面的表現,仍顯著落後於人類兒童水平。
即便是表現最好的 Gemini 3 Pro Preview,其得分也僅略高於 3 歲兒童,與 6 歲兒童仍存在約 20% 的差距,與成年人 94.1% 的水平更是相去甚遠。
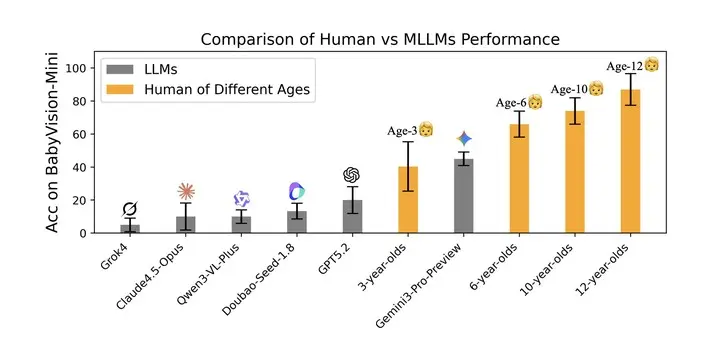
研究來自 UniPat AI、xbench、阿里、月之暗面、階躍星辰等團隊。結果顯示,Gemini 3 Pro Preview 以 49.7% 的成績領跑閉源模型,其後依次為 GPT‑5.2(34.4%)與豆包 Seed‑1.8(30.2%)。
其他模型表現更低,包括 Qwen3‑VL‑Plus(19.2%)、Grok‑4(16.2%)與 Claude 4.5 Opus(14.2%)。在開源模型中,Qwen3VL‑235B‑Thinking 以 22.2% 的成績位列第一,但仍無法與閉源模型競爭。
研究指出,當前多模態大模型普遍採用「視覺轉語言」的推理路徑,即先將圖像壓縮為語言表徵,再依賴語言模型進行推理。
這一架構在處理細粒度幾何、空間關係、路徑連續性等非語言特徵時存在天然瓶頸,導致模型在「找不同」「連線」「空間想象」「視覺規律歸納」等任務中頻繁出錯。
在 BabyVision 的四大能力維度 —— 細粒度辨別、視覺追蹤、空間感知與視覺模式識別中,模型均暴露出明顯短板。
例如,Gemini 3 Pro Preview 在拼圖匹配、路徑連線與三維結構推斷任務中均出現錯誤;Qwen3‑VL‑Plus 在視覺規律歸納任務中也未能給出正確答案。
研究團隊進一步分析了模型在視覺推理中的四類核心挑戰:
- 非言語性精細細節難以保留,導致模型無法區分微小差異;
- 流形一致性缺失,使模型難以在複雜路徑中保持連續追蹤;
- 空間想象能力不足,難以從二維圖像構建穩定的三維表徵;
- 視覺模式歸納能力薄弱,無法從示例中抽象出變化規則。
為突破語言化視覺推理的限制,研究提出兩條潛在路徑:基於可驗證獎勵的強化學習(RLVR)與基於生成模型的視覺推理。
實驗顯示,Qwen3‑VL‑8B‑Thinking 在 RLVR 微調後整體準確率提升約 4.8 個百分點;而在 BabyVision‑Gen 的生成式推理測試中,NanoBanana‑Pro 以 18.3% 的準確率領先 GPT‑Image‑1.5 與 Qwen‑Image‑Edit。
研究認為,未來多模態智能的發展方向,將從「語言驅動」轉向「視覺原生推理」。統一架構(如 Bagel)與具備物理建模能力的生成模型(如 Sora 2、Veo 3)展示了在視覺空間中進行顯式推理的潛力,包括繪製中間步驟、標註關鍵區域或生成物理軌跡等方式。
研究團隊指出,生成過程本身可能成為一種更高級的推理形式。
論文全文:https://arxiv.org/abs/2601.06521
