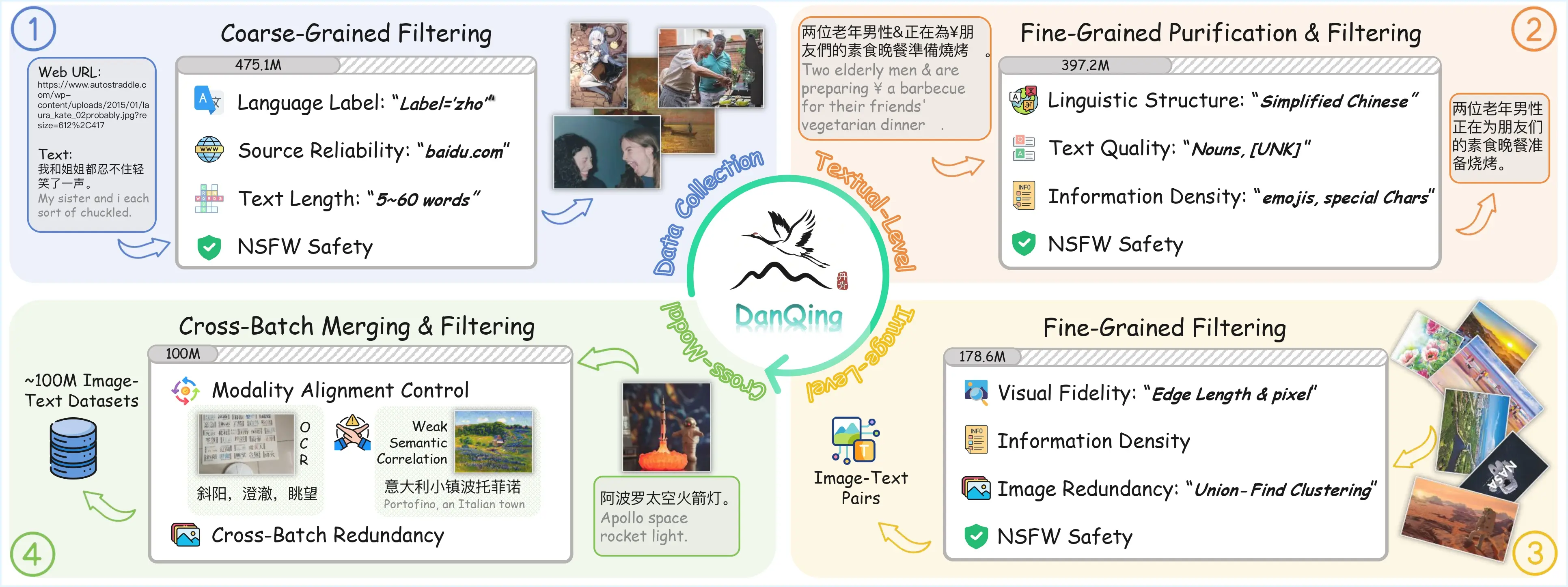
格靈深瞳發佈大規模中文視覺語言預訓練數據集“丹青”(DanQing),包含1億組圖文配對數據,基於2024–2025年網絡數據構建。該數據集採用更嚴格的篩選機制,研究團隊基於SigLIP2模型實驗表明,其在零樣本分類、跨模態檢索及大型多模態模型評測等任務中表現優異。
據介紹,團隊實現了一個基於BERTopic 的主題建模流程。他們隨機抽取了1000萬個圖像-文本對,並使用Chinese-CLIP-L/14提取文本嵌入。為了解決高維聚類問題,團隊應用UMAP進行降維,然後使用HDBSCAN識別語義簇,最小簇大小為1000,以提高穩定性並降低噪聲。最後使用基於類別的TF-IDF為每個主題提取代表性關鍵詞。

丹青數據集官網:https://deepglint.github.io/DanQing/
