一、導語
得物社區推薦的實踐中,我們發現用户興趣容易收斂到少數幾個主興趣上,難以做到有效的興趣拓展,通過將大模型與推薦結合的方式,在得物社區的用户興趣拓展方向上切實取得了突破,拿到了顯著的業務收益並推全上線。因此我們將相關工作中採用的核心算法與模型策略總結整理,投稿了AAAI-PerFM,入選了長論文《Enhancing Serendipity Recommendation System by Constructing Dynamic User Knowledge Graphs with Large Language Models》。AAAI Conference on Artificial Intelligence)由人工智能促進會(AAAI)主辦,是人工智能領域歷史最悠久的國際學術會議之一。以下內容為正文的詳細介紹。
二、背景介紹
得物社區作為得物的首tab,滿足得物用户分享生活、發現好物的內容生產消費需求。跟其他內容平台一樣,得物的社區推薦系統也存在“推薦 → 用户反饋 → 再推薦”的反饋閉環問題,系統會越來越傾向於推送相似內容,導致推薦結果收斂、同質化,進而形成信息繭房,降低用户的新鮮感與滿意度。
同時隨着大語言模型(LLM)的發展,世界知識提取的效率逐漸得到提升,為打破信息繭房,提高用户內容消費的新鮮感帶來了新的機遇。我們提出用大語言模型(LLM)來動態構建用户知識圖譜(User Knowledge Graph),並在知識圖譜上進行更可控的推理來挖掘用户“潛在興趣”,再把這些潛在興趣以工程可落地的方式接入工業推薦鏈路,在得物社區業務場景取得了顯著的消費指標收益。
得物App的社區頁示例:
三、問題與挑戰
1.為了打破信息繭房並提升用户體驗,新穎性推薦應該給用户推薦意料之外的物品,並且吸引用户點擊,即同時具備意外性和相關性。但受限於意外發現數據的稀缺性,近些年的研究往往只能採用較小的模型,或者在有偏差的推薦數據的基礎上進行數據擴充,這可能反而會強化反饋循環,增大打破信息繭房和識別新穎性物品的難度。
2.雖然大語言模型擁有豐富的世界知識,並展現出卓越的理解和推理能力。但在將大模型推理落地到推薦系統的實踐中,依然發現大模型難以通過單跳推理正確生成複雜問題的答案。
3.工業推薦系統對實時性有要求,通常響應時間在100ms內。基於大模型的新穎性推薦有較高的延遲,計算成本高昂。
4.當推理生成出用户潛在興趣後,在推薦系統中如何高效地召回相關候選item,既要保證item與用户潛在興趣的相關性,又要兼具高消費效率的特性(比如擁有更好的點擊率,保護用户消費體驗),是能否在工業場景取得收益的關鍵。
四、優化方案
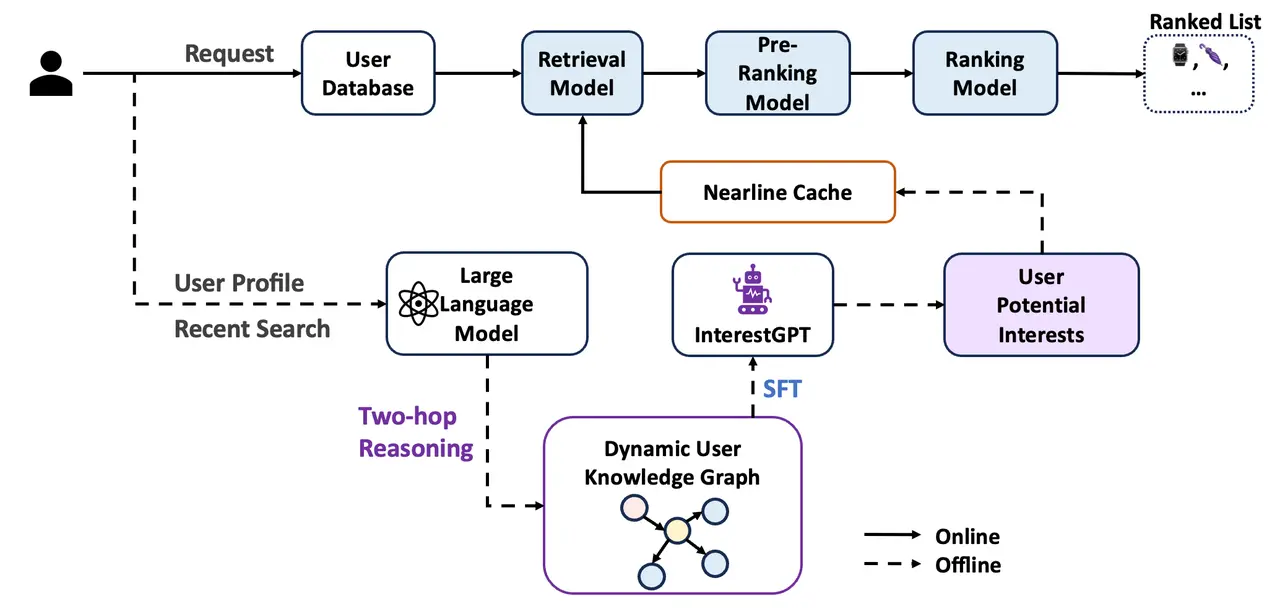
整體框架如上圖所示:
1.採用大語言模型替代傳統小模型,從用户行為中提取潛在興趣,從而緩解顯式興趣發現數據稀缺的問題。
2.通過兩跳推理與多智能體多輪辯論機制,提升大模型在興趣推理中的準確性與穩定性,保障輸出質量。
3.採用近線召回架構進行工程部署,緩解大模型推理時延較高的挑戰,實現推薦系統的實時響應。
4.引入對比學習,將大模型提取的興趣與推薦系統內現有用户興趣表徵進行對齊,確保召回內容既符合用户潛在偏好,又具備高相關性與高消費轉化效率的特點。
基於LLM大模型興趣提取過程:
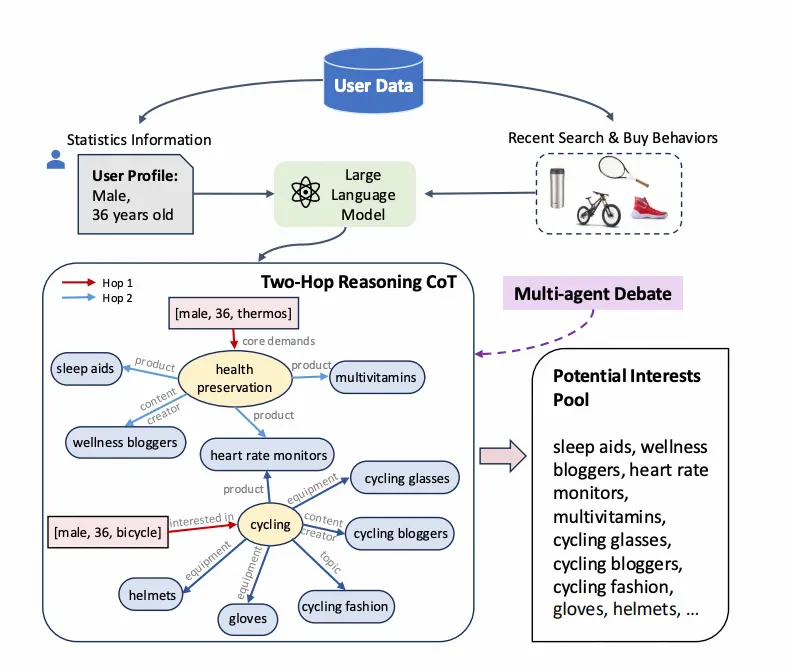
用户的靜態畫像(年齡、性別)以及用户的歷史行為(過去30天的搜索詞)作為初始輸入節點,大模型作為用户動態圖譜構建工具:
將大模型作為知識圖譜構建器,動態構建節點和關係 G=(V,E),其中 V 是實體集合,E 是關係集合。給定兩個實體 v1 和 v3,目標是通過兩跳推理判斷它們之間是否存在潛在興趣關係。
- 第一步: 從 用户靜態畫像和搜索詞v1 出發,找到滿足上位關係的節點v2。
<!---->
- 即找到所有滿足 (v1,v2)∈E 的 v2。
- v2是v1的核心述求和動機。
<!---->
- 第二步: 從 v2 出發,找到所有滿足用户核心訴求的同位或者下位的節點 v3。
<!---->
- 即找到所有滿足 (v2,v3)∈E 的 v3。
- 為了避免不相關的輸出並減少幻覺v3限制在商品、商品類目、話題範圍。
多智能體多回合辯論
通過提示工程根據用户靜態畫像和用户行為構建用户動態畫像及完成兩跳推理,會出現推理路徑錯誤及潛在興趣不相關問題。在本文中,我們採用了一種互補方法來改進推理過程和輸出響應,其中多個語言模型實例在多個回合中提出和辯論其各自的響應和推理過程,以得出共同的最終答案。 我們發現,這種方法顯著增強了任務的兩跳推理能力。同時這種方法還提高了生成內容的事實有效性,減少了當代模型容易出現的謬誤答案和幻覺。
具體來説,我們首先提示每個代理獨立解決給定的問題或任務。 在每個代理生成回覆後,我們向每個代理提供一個共識提示,如圖 所示,其中每個代理被指示根據其他代理的回覆更新其回覆。 然後可以使用每個代理的更新回覆反覆給出此生成的共識提示。

SFT
為了降低部署成本,我們先使用參數量較大的推理模型deepseek-r1構建户動態圖譜(思考過程)和生成潛在興趣作,然後蒸餾到參數量更小的模型qwq-32b。將思考過程和潛在興趣轉換為文本化的SFT數據集D,其中每個條目是一個元組(x,y)。 這裏,y 指的是輸出,代表思考過程和潛在興趣,而x 代表輸入提示,輸入和輸出如圖接下來,遵循如下公式,對qwq-32b進行監督微調得到interestGPT,以提高其生成期望回答的概率。
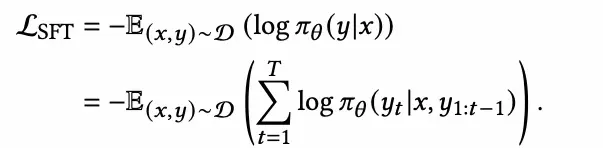
大模型興趣在推薦系統中的應用
為了兼顧i2i召回和u2i召回的優點,我們設計了一種兼具i2i召回能力的u2i召回模型。具體而言,雙塔召回模型是多任務目標,在傳統雙塔u2i的BCE-Loss基礎上,在user塔中引入了基於興趣對齊的對比學習損失,通過最大化相同興趣下用户嵌入與物品嵌入之間的相似性,同時最小化不同興趣下用户嵌入與物品嵌入之間的相似性,從而在預估階段能夠基於用户新興趣生成與之高相關度的user-embedding。這樣得到的embedding用於向量檢索召回,召回得到的item集合不僅與新興趣保持了高度的相關性,同時保持了u2i召回的消費效率高的優點。
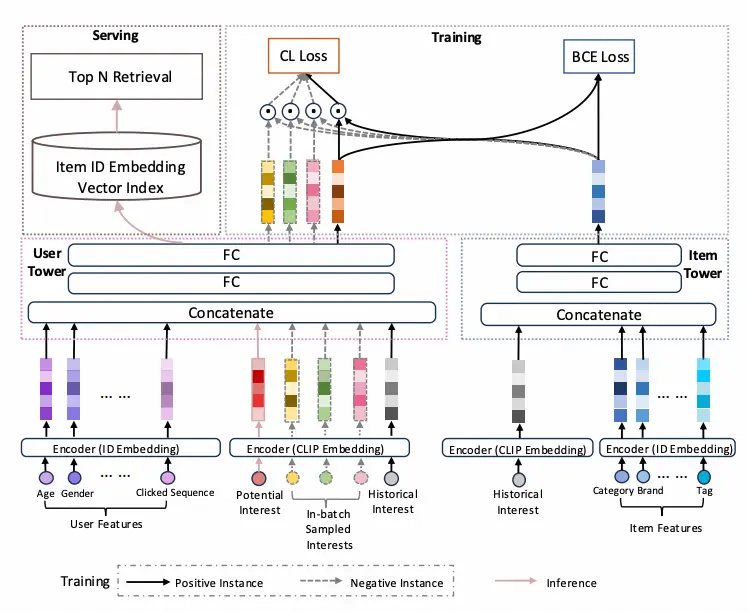

用户塔的輸入特徵包括:用户靜態畫像如:年齡、性別等,用户歷史交互物品序列特徵如類目、品牌、標籤等,這些特徵通過id-emddding的方式表徵為fᵘ;用户興趣,用户興趣通過文本編碼器獲得
embedding
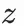
。在訓練階段,用户興趣正樣本是用户點擊過的物品,用户興趣負樣本是batch內採樣的其他物品,在推理階段,用户興趣是通過兩跳推理生成的潛在新興趣。文本編碼器可以選擇 CLIP、BERT、USE、BGE 等模型, 在我們的實驗中,我們選擇了 CLIP 作為編碼器。值得注意的是,大模型推理出來的新興趣只在推理的時候使用,而不參與到訓練過程中。
雙塔模型
物品塔的輸入包含:物品的靜態特徵,如:類目體系、品牌、標籤等,這些特徵用id-embdedding進行表徵
用户塔:將用户特徵fᵘ
和歷史興趣
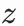
拼接,通過兩層全連接層得到
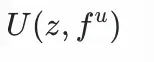
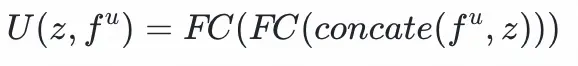
物料塔:將物品特徵fᵘ
和歷史興趣
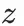
拼接,通過兩層全連接層得到
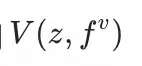
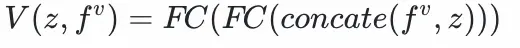
訓練階段
通過雙塔模型來訓練用户點擊樣本同時,我們希望對於同一用户,不同的z輸入user塔後得到的興趣表徵具有較大的區分度:
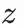
興趣下的用户興趣表徵
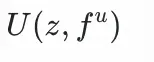
要與同為
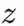
興趣
的物品表徵更加相關,他們之間的關聯度要大於其他
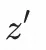
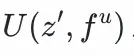
與
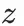
興趣的物品表徵。這樣就能儘可能做到,輸入用户的潛在興趣給到user towel的時候,就能獲取到用户新穎性興趣的表徵而不至於與已有的興趣混淆。
因此,我們引入了對比學習
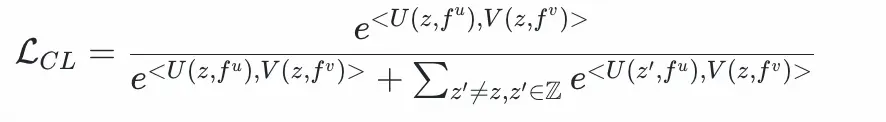
綜合以上考慮,我們採用多目標聯合訓練的方法,採用multi-task loss,由對比學習損失和二分類交叉熵損失構成:
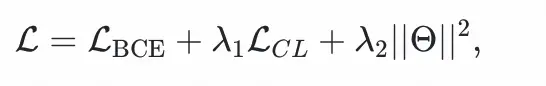

是模型的參數集合,
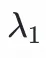
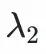
是超參數。
另外交叉熵損失用於建模用户對歷史物品的點擊偏好,其公式為:
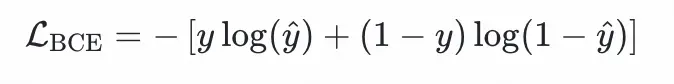
其中,
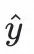
是對物品
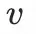
的點擊概率的預測值。
預估階段
在預估階段,首先將用户的某個潛在新興趣
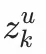
(1<=k<=n,n為用户u潛在新興趣總數)連同用户特徵一起輸入user塔,獲得用户新興趣表徵向量
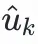
。利用
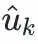
進行ann檢索得到物品集合,作為潛在興趣
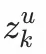
的召回結果。將用户所有的潛在新興趣的召回結果歸併在一起,與其他召回通道內容一同給到後續的推薦鏈路中。
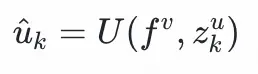
五、實驗效果
我們在得物App(Dewu)上進行實驗,得物App是一個擁有數千萬用户的潮流電子商務平台。我們隨機選取了得物社區10%的流量來進行A/B實驗,目標是基於用户歷史搜索詞和靜態畫像,生成用户潛在興趣,併為其推薦意外物品。我們選擇得物原有的社區推薦召回系統作為基線,使用CLIP模型作為興趣文本encoder,在此基礎上為新穎性推薦新增了一個召回渠道。
我們使用8個指標來衡量在線性能:人均時長(AVDU),UVCTR,人均閲讀量(ACR),UV互動滲透(ER),人均一級類目點擊數(ACC-1),人均三級類目點擊數(ACC-3),一級類目新穎性曝光佔比(ENR)和一級類目新穎性點擊佔比(CNR)。其中人均一級類目點擊數,人均三級類目點擊數是用於評估多樣性的指標。我們將一級類目新穎性定義為:當某物品的一級類目不在用户最近200次點擊記錄的一級類目集合內時,該物品的曝光或點擊即具有一級類目新穎性。通過計算一級類目新穎性曝光佔所有曝光的比例,以及一級類目新穎性點擊佔所有點擊的比例,評估推薦系統的新穎性表現。
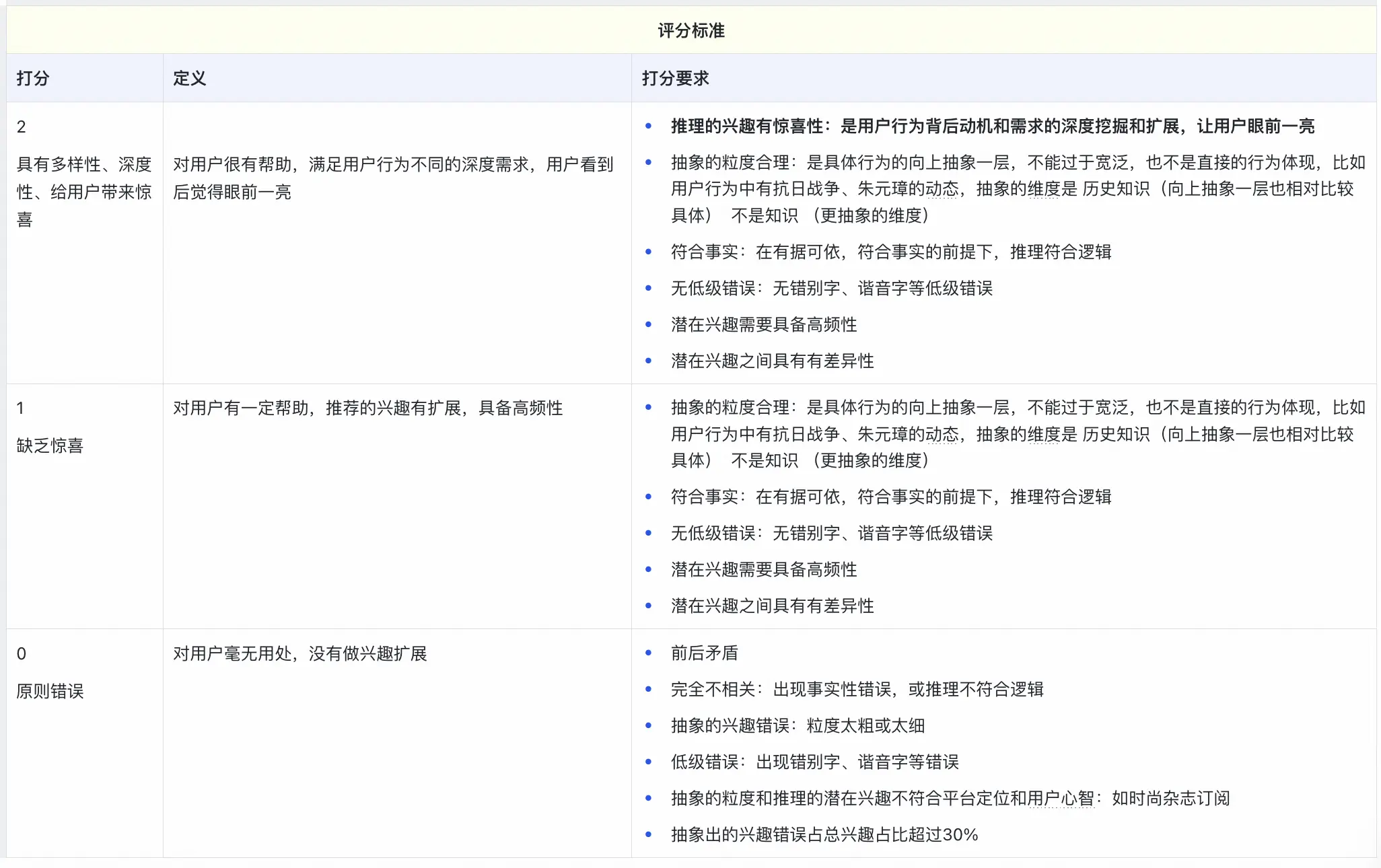
我們用deepseek-r1生成的3萬條數據做標註樣本,對qwq-32b模型經過sft後得到模型interestGPT,使用離線評估標準對interestGPT在1萬條測試集上評估,抽樣1000個用户評估結果如下: 0分佔比:1%,1分佔比:3%,2分佔比:96%。
為了評估我們方法的在線效果,我們隨機選取了大盤10%的流量進行A/B測試。我們在基線的基礎上,為新穎性推薦新增了一個召回渠道。在新穎性召回渠道中,我們基於用户最近30天的用户搜索行為進行潛在興趣拓展,每個用户最多選擇16個潛在興趣,每個興趣召回40個對應的item。然後將這一路召回與其他渠道融合得到最終的召回結果。
最終的線上實驗效果如下:

和baseline相比,我們的方法顯著提升了推薦結果的多樣性和新穎性。我們的方法在AVDU上相對提升0.15%。 UVCTR、ACR和ER分別提升了0.07%,0.15%,0.3%。在多樣性方面,ACC-1 和ACC-3分別取得了0.21% 和0.23%的提升。對於新穎性,ENR和CNR分別取得了4.62%和4.85%的顯著提升。
新穎性召回渠道對於推薦內容多樣性和新穎性的改善是持續的。對照組的曝光新穎率為14.24%,實驗組中新穎性召回通道的召回新穎率為26.53%,其他通道的召回新穎率為16.17%。這説明,當新穎性召回引入了新的信號,用户進行了新的交互,產生了和新興趣有關的訓練數據之後,其他召回通道也能夠迅速捕捉到用户的新興趣信號,從而打破反饋循環現象,衝破推薦繭房。
六、結論
這項工作通過提出利用大模型構建用户動態知識圖譜並通過兩跳推理來解決推薦系統中的信息繭房問題。 它包括兩個階段:兩跳推理,通過大語言模型將用户靜態畫像和歷史行為動態構建用户知識圖譜,在構建的圖譜上進行兩跳推理;近線自適應,用於高效的工業部署。 同時設計了一種兼具i2i召回能力的u2i模型,召回得到的item集合不僅與新興趣保持了高度的相關性,同時保持了u2i召回的item消費效率高的優點。
並部署了訓練推理解耦的召回模型,利用大模型產出的新興趣,生成對應的多興趣user-embedding,將用户潛在興趣召回結果集成到推薦系統中。無論是離線還是在線實驗都取得了顯著收益,完全可以在大規模工業系統上部署並拿到收益。
七、總結與展望
目前,我們主要基於得物App中的用户搜索行為構建興趣挖掘模型。由於搜索行為本身具有較高的稀疏性,未來將引入點擊、瀏覽、收藏等更豐富的交互行為,以探究在多行為數據融合下大語言模型對用户潛在興趣的刻畫能力,並驗證興趣建模是否存在與數據規模相關的擴展規律。在系統應用層面,除了在召回環節引入用户新興興趣外,還可進一步將興趣表徵融合至粗排、精排及重排等排序階段,從而提升新興趣場景下的物品評分準確性。此外,也可結合推薦場景中的實時用户反饋數據,對模型輸出的多元興趣進行動態校準,避免興趣過度發散,確保其與用户真實需求的相關性。在大模型生成式架構基礎上,我們同步探索並構建了生成式召回模型,目前已取得初步成果,並在得物推薦場景中全面上線應用。未來,我們將持續加大該方向的研發投入。
每一次技術迭代,其最終目標始終是服務於用户體驗的提升。正如得物始終秉持的初心——我們希望通過智能推薦技術的持續進化,助力每一位用户更精準、更愉悦地「得到美好事物」。
往期回顧
1.Galaxy比數平台功能介紹及實現原理|得物技術
2.得物App智能巡檢技術的探索與實踐
3.深度實踐:得物算法域全景可觀測性從 0 到 1 的演進之路
4.前端平台大倉應用穩定性治理之路|得物技術
5.RocketMQ高性能揭秘:承載萬億級流量的架構奧秘|得物技術
文 /流煜曦
關注得物技術,每週更新技術乾貨
要是覺得文章對你有幫助的話,歡迎評論轉發點贊~
未經得物技術許可嚴禁轉載,否則依法追究法律責任。
