智譜AI剛剛發佈並開源GLM-4.7,新版本面向Coding場景強化了編碼能力、長程任務規劃與工具協同,並在多項主流公開基準測試中取得開源模型中的領先表現。
目前,GLM-4.7已通過BigModel.cn提供API,並在z.ai全棧開發模式 中上線全新Skills模塊,支持多模態任務的統一規劃與協作執行。
Coding能力再提升
GLM-4.7在編程、推理與智能體三個維度實現突破:
- 更強的編程能力:顯著提升了模型在多語言編碼和在終端智能體中的效果;GLM-4.7現在可以在Claude Code、TRAE、Kilo Code、Cline和Roo Code等編程框架中實現“先思考、再行動”的機制,在複雜任務上有更穩定的表現。
- 前端審美提升:GLM-4.7在前端生成質量方面明顯進步,能夠生成觀感更佳的網頁、PPT 、海報。
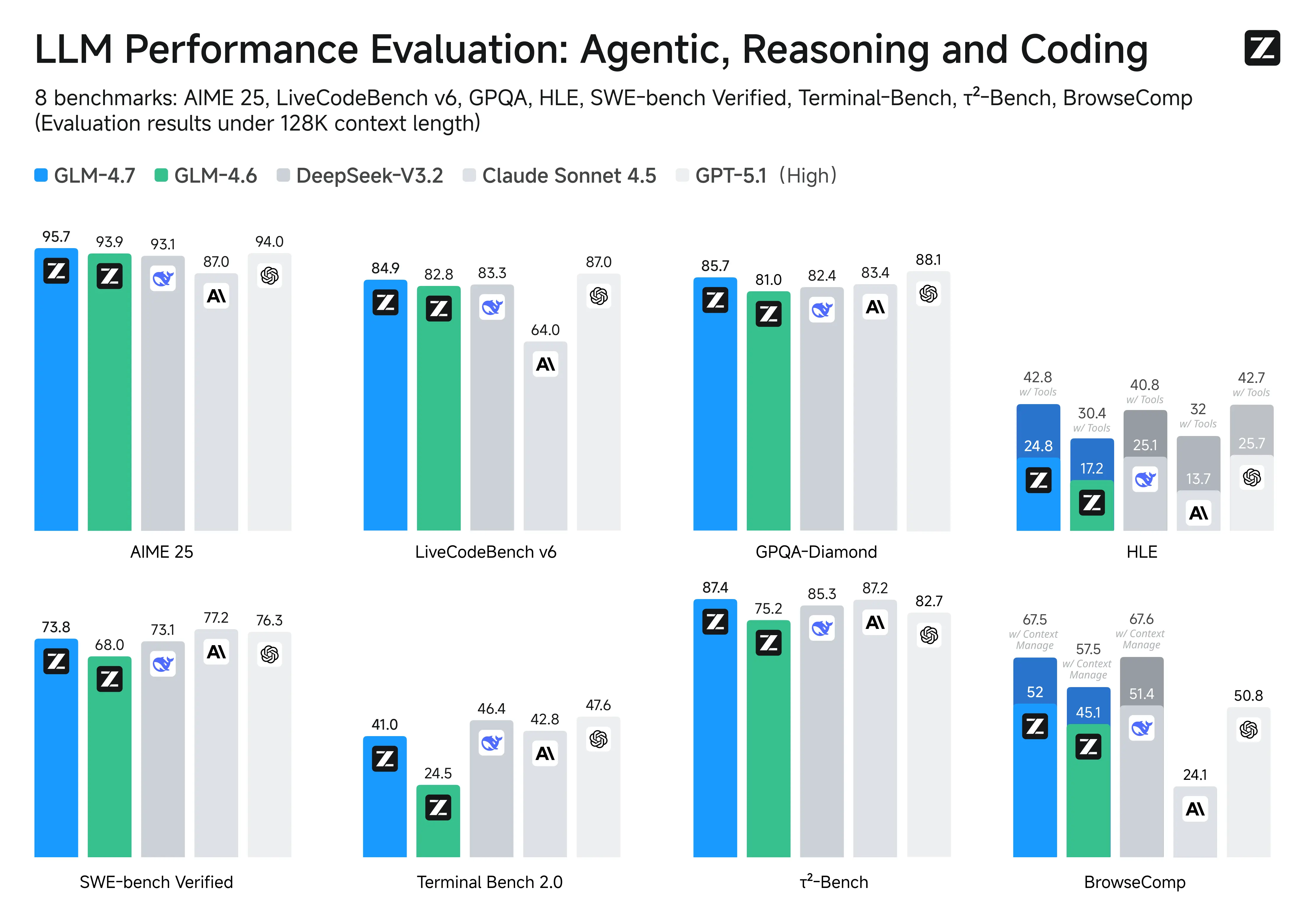
- 更強的工具調用能力:GLM-4.7提升了工具調用能力,在BrowseComp網頁任務評測中獲得67.5分;在τ²-Bench交互式工具調用評測中實現87.4分的開源SOTA,超過Claude Sonnet 4.5。
- 推理能力提升:顯著提升了數學和推理能力,在HLE("人類最後的考試")基準測試中獲得42.8%的成績,較GLM-4.6提升41%,超過GPT-5.1。
- 通用能力增強:GLM-4.7對話更簡潔智能且富有人情味,寫作與角色扮演更具文采與沉浸感。

Code Arena:全球百萬用户參與盲測的專業編碼評估系統,GLM-4.7位列開源第一、國產第一,超過GPT-5.2。
在主流基準測試表現中,GLM-4.7的代碼能力對齊Claude Sonnet 4.5:在SWE-bench-Verified獲得73.8%的開源SOTA分數(相較GLM-4.6提升5.8%);在LiveCodeBench V6達到84.9的開源SOTA分數,超過Claude Sonnet 4.5;SWE-bench多語言版達到66.7%(提升12.9%);Terminal Bench 2.0達到41%(提升16.5%)。
在z.ai中,GLM-4.7集成了全新的Skills模塊,內置智譜多模態全家桶(GLM-4.6V、GLM-ASR、GLM-TTS等)。
藉助GLM-4.7的任務規劃與執行能力,多模態技能可在複雜業務流中被統一調度與協同,幫助開發者構建交互更豐富、體驗更流暢的應用。
現在,只需要一句簡單的提示詞,GLM-4.7開源SOTA的Coding能力加之多模態全家桶的語音合成、TTS、圖像/視頻生成等,即可將你的想象力轉化為任何應用。
例如,當我們想要一個“黑金氛圍+電影感+柔光聚光漸變”UI風格的博客應用時,GLM-4.7 基於自身編程、推理和智能體能力,並通過智能調用GLM-TTS在幾分鐘內輕鬆完成。
可以説,人人編程的時代真的到來了。
開源與在線體驗
API 接入
- 開放平台:BigModel.cn
- GLM Coding Plan已升級GLM-4.7
在線體驗
- z.ai:體驗GLM-4.7全棧開發
- 智譜清言APP/網頁版:體驗GLM-4.7全新對話、創作與編程
開源鏈接
- Github:https://github.com/zai-org/GLM-4.5
- Huggingface:https://huggingface.co/zai-org/GLM-4.7
- 魔搭社區:https://modelscope.cn/models/ZhipuAI/GLM-4.7
blog:https://z.ai/blog/glm-4.7
