一、背景
得物經過10年發展,計算任務已超10萬+,數據已經超200+PB,為了降低成本,計算引擎和存儲資源需要從雲平台遷移到得物自建平台,計算引擎從雲平台Spark遷移到自建Apache Spark集羣、存儲從ODPS遷移到OSS。
在遷移時,最關鍵的一點是需要保證遷移前後數據的一致性,同時為了更加高效地完成遷移工作(目前計算任務已超10萬+,手動比數已是不可能),因此比數平台便應運而生。
二、數據比對關鍵挑戰與目標
關鍵挑戰一:如何更快地完成全文數據比對
現狀痛點:
在前期遷移過程中,遷移同學需要手動join兩張表來識別不一致數據,然後逐條、逐字段進行人工比對驗證。這種方式在任務量較少時尚可應付,但當任務規模達到成千上萬級別時,就無法實現併發快速分析。
核心問題:
- 效率瓶頸:每天需要完成數千任務的比對,累計待遷移任務達10萬+,涉及表數十萬張。
- 擴展性不足:傳統人工比對方式無法滿足大規模併發處理需求。
關鍵挑戰二:如何精準定位異常數據
現狀痛點:
遷移同學在識別出不一致數據後,需要通過肉眼觀察來定位具體問題,經常導致視覺疲勞和分析效率低下。
核心問題:
- 分析困難:在比對不通過的情況下,比對人員需要人工分析失敗原因。
- 複雜度高:面對數據量龐大、加工邏輯複雜的場景,特別是在處理大JSON數據時,肉眼根本無法有效分辨差異。
- 耗時嚴重:單次比對不通過場景的平均分析時間高達1.67小時/任務。
比數核心目標
基於以上挑戰,數據比對系統需要實現以下核心目標:
- 高併發處理能力:支持每天數千任務的快速比對,能夠處理10萬+待遷移任務和數十萬張表的規模。
- 自動化比對機制:實現全自動化的數據比對流程,減少人工干預,提升比對效率。
- 智能差異定位:提供精準的差異定位能力,能夠快速識別並高亮顯示不一致的字段和數據。
- 可視化分析界面:構建友好的可視化分析平台,支持大JSON數據的結構化展示和差異高亮。
- 性能優化:將用户單次比對分析時間從小時級大幅縮短至分鐘級別。
- 可擴展架構:設計可水平擴展的系統架構,能夠隨着業務增長靈活擴容。
三、解決方案實現原理
快速完成全文數據比對方法
比數方法調研
待比對兩表數據大小:300GB,計算資源:1000c


經過調研分析比數平台採用第二種和第三種相結合的方式進行比數。
先Union再分組數據一致性校驗原理
假如我們有如下a和b兩表張需要進行數據比對
表a:
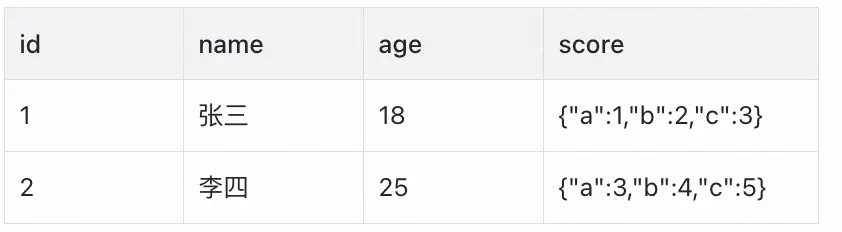
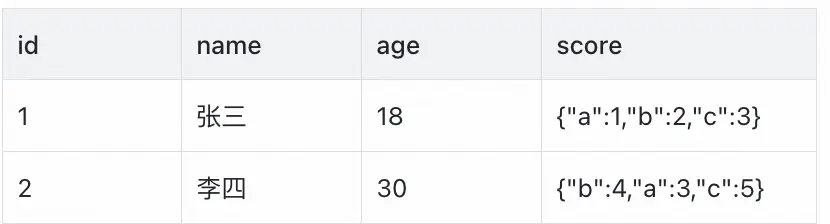
select count(1) from a ;
select count(1) from b ;
針對上面的查詢結果,如果數量不一致則退出比對,待修復後重新比數;數量一致則繼續字段值比較。
字段值比較:
第一步:union a 和 b
select 1 as _t1_count, 0 as _t2_count, `id`, `name`, `age`, `score`
from a
union all
select 0 as _t1_count, 1 as _t2_count, `id`, `name`, `age`, `score`
from b
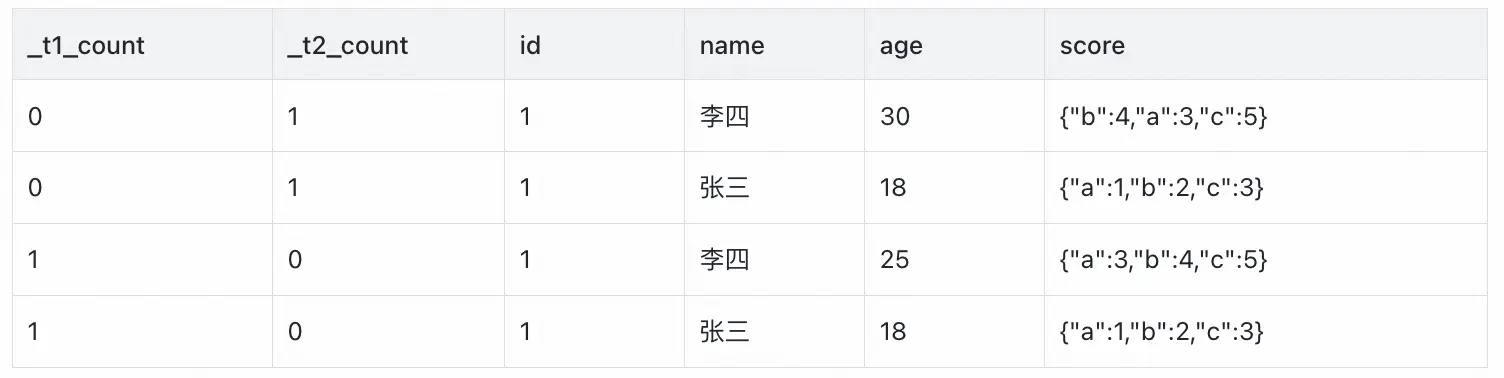
第二步:sum(_t1_count),sum(_t2_count) 後分組
select sum(_t1_count) as sum_t1_count, sum(_t2_count) as sum_t2_count, `id`, `name`, `age`, `score`
from (
select 1 as _t1_count, 0 as _t2_count, `id`, `name`, `age`, `score`
from a
union all
select 0 as _t1_count, 1 as _t2_count, `id`, `name`, `age`, `score`
from b
) as union_table
group by `id`, `name`, `age`, `score`

drop table if exists a_b_diff_20240908;
create table a_b_diff_20240908 as select * from (
select sum(_t1_count) as sum_t1_count, sum(_t2_count) as sum_t2_count, `id`, `name`, `age`, `score`
from (
select 1 as _t1_count, 0 as _t2_count, `id`, `name`, `age`, `score`
from a
union all
select 0 as _t1_count, 1 as _t2_count, `id`, `name`, `age`, `score`
from b
) as union_table
group by `id`, `name`, `age`, `score`
having sum(_t1_count) <> sum(_t2_count)
) as tmp
如果a_b_diff_20240908沒有數據則兩張表沒有差異,比數通過,如有差異如下:

第四步:讀取不一致記錄表,根據主鍵(比如id)找出不一致字段並寫到結果表中。
第五步:針對不一致字段的數據進行根因分析,如 json 、數組順序問題、浮點數精度問題等,給出不一致具體原因。
哈希值聚合實現高效一致性校驗
針對上面union後sum 再 group by 方式 在數據量大的時候還是非常耗資源和時間的,考慮到比數任務畢竟有70%都是一致的,所以我們可以先採用哈希值聚合比較兩表的的值是否一致,使用這種高效的方法先把兩表數據一致的任務過濾掉,剩下的再採用上面方法繼續比較,因為還要找出是哪個字段哪裏不一致。原理如下:
SELECT count (*),SUM(xxhash64(cloum1)^xxhash64(cloum2)^...) FROM tableA
EXCEPT
SELECT count(*),SUM(xxhash64(cloum1)^xxhash64(cloum2)^...) FROM tableB
如果有記錄為空説明數據一致,不為空説明數據不一致需要採用上面提到union 分組的方法去找出具體字段哪裏不一樣。
通過哈希值聚合,單個任務比數時間從500s降低到160s,節省大約70%的時間。
找到兩張表不一致數據後需要對兩張的數據進行分析確定不一致的點在哪裏?這裏就需要知道表的主鍵,根據主鍵逐個比對兩張表的其他字段,因此係統會先進行主鍵的自動探查,以及無主鍵的兜底處理。
精準定位異常數據實現方法
自動探查主鍵:實現原理如下
剛開始我們採用的前5個字段找主鍵的方式,如下:
針對表a的前5個字段 循環比對
select count(distinct id) from a 與 select count(1) from a 比較 ,如相等主鍵為id ,不相等繼續往下執行
select count(distinct id,name) from a 與 select count(1) from a比較,如相等主鍵為id,name ,不相等繼續往下執行
select count(distinct id,name,age) from a 與 select count(1) from a比較,如相等主鍵為id,name,age ,不相等繼續往下執行,直到循環結束
採用上面的方法不一致任務中大約有49.6%任務自動探查主鍵失敗:因此需重點提升主鍵識別能力。
針對以上主鍵探查成功率低的問題,後續進行了一些迭代,優化後的主鍵探查流程如下:
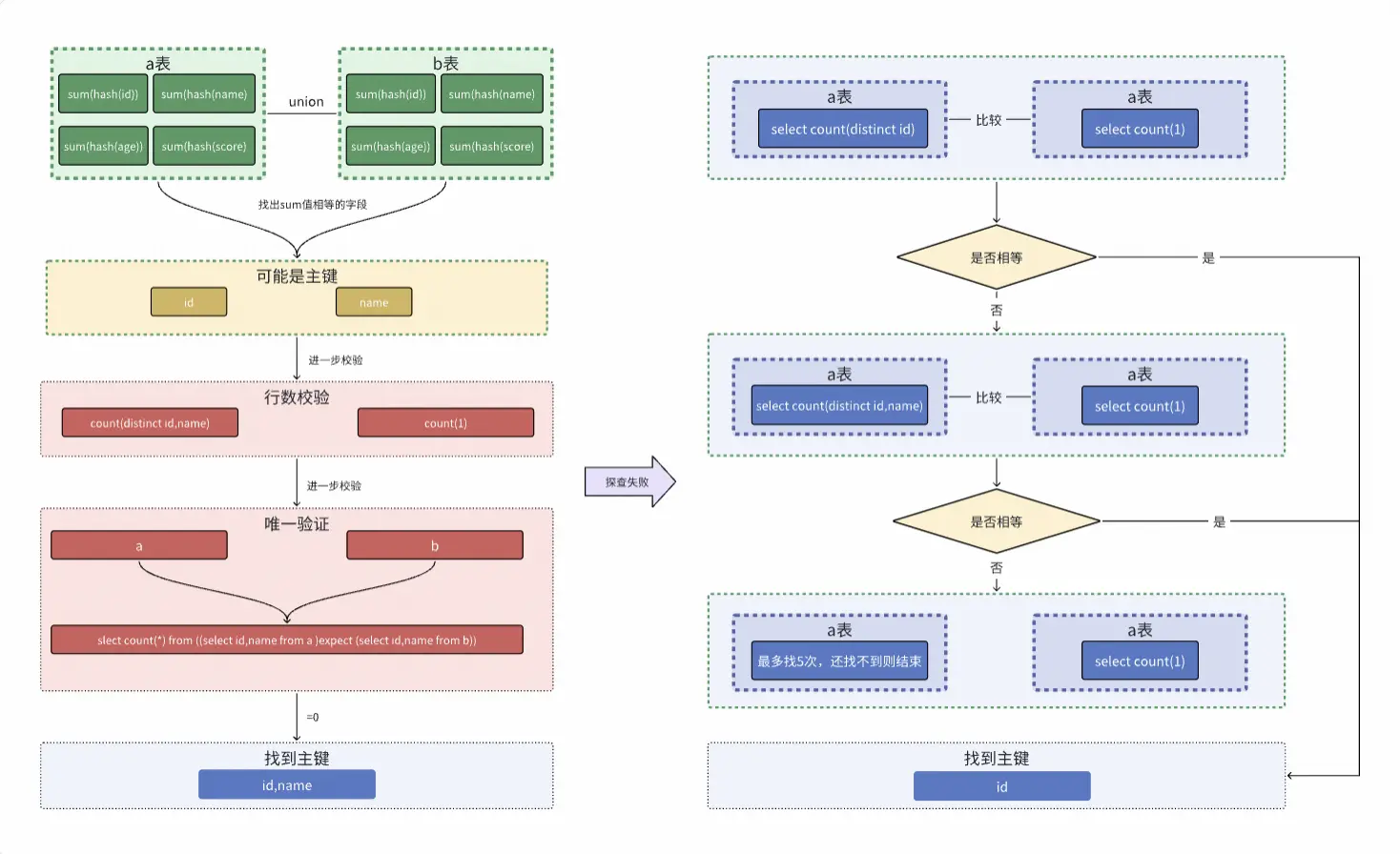
一、先採用sum(hash)高效計算方式進行探查:
1.先算出兩張表每個字段的sum(hash)值 。
select sum(hash(id)),sum(hash(name)),sum(hash(age)),sum(hash(score)) from a
union all
select sum(hash(id)),sum(hash(name)),sum(hash(age)),sum(hash(score)) from b;
2.找出值相等的所有字段,本案例中為 id, name。
3.對id,name 可能是主鍵進一步確認,先進行行數校驗,如 select count(distinct id,name) from a 的值等於select count(1) from a 則進一步校驗,否則進入到第二種探查主鍵方式。
4.唯一性驗證,如果值為0則表示探查主鍵成功,否則進入到第二種探查主鍵方式。
slect count(*) from ((select id,name from a ) expect (select id,name from b))
二、傳統distinct方式探查:
針對表a的前N(所有字段數/2或者前N、後N等)個字段 循環比對:
1.select count(distinct id) from a與select count(1) from a比較 ,如相等主鍵為id ,不相等繼續往下執行。
2.select count(distinct id,name) from a 與 select count(1) from a比較,如相等主鍵為id,name ,不相等繼續往下執行。
3.select count(distinct id,name,age) from a 與 select count(1) from a比較,如相等主鍵為id,name,age ,不相等繼續往下執行,直到循環結束。
三、全字段排序模擬:
如果上面兩種方式還是沒有找到主鍵則把不一致記錄表進行全字段排序然後對第一條和第二條記錄挨個字段進行分析,找出不一致內容,示例如下:
slect * from a_b_diff_20240908 order by id,name,age,score asc limit 10;

如果以上自動化分析還是找不到不一致字段內容,可以人工確認表的主鍵後到平台手動指定主鍵字段,然後點擊後續分析即可按指定主鍵去找字段不一致內容。
通過多次迭代優化找主鍵策略,找主鍵成功率從最初的50.4%提升到75%,加上全字段order by排序後最前兩條數據進行分析,相當於可以把找主鍵的成功率提升到90%以上。
根因分析:實現原理如下
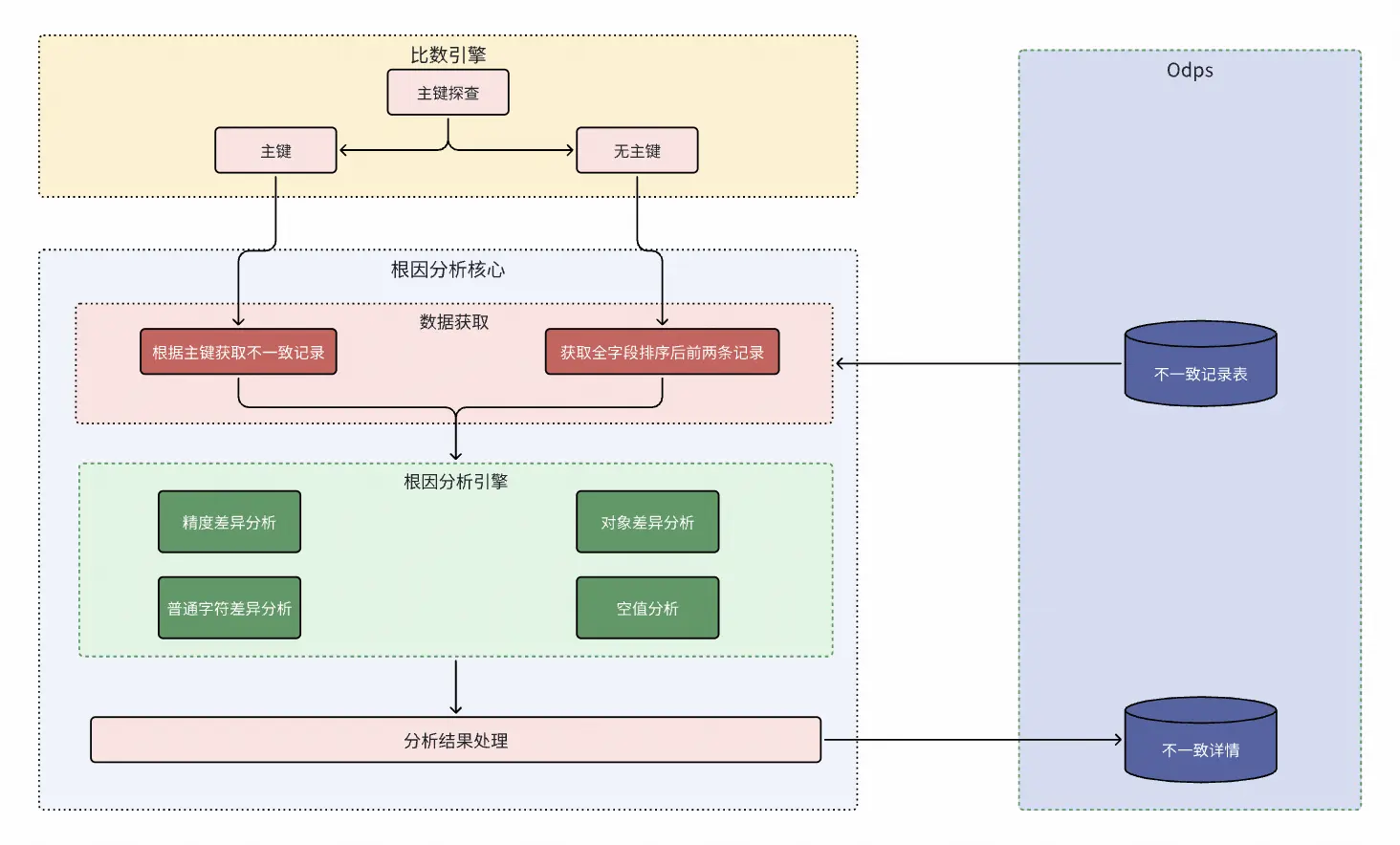
當數據不一致時,平台會根據主鍵找出兩個表哪些字段數據不一致並進行分析,具體如下:
-
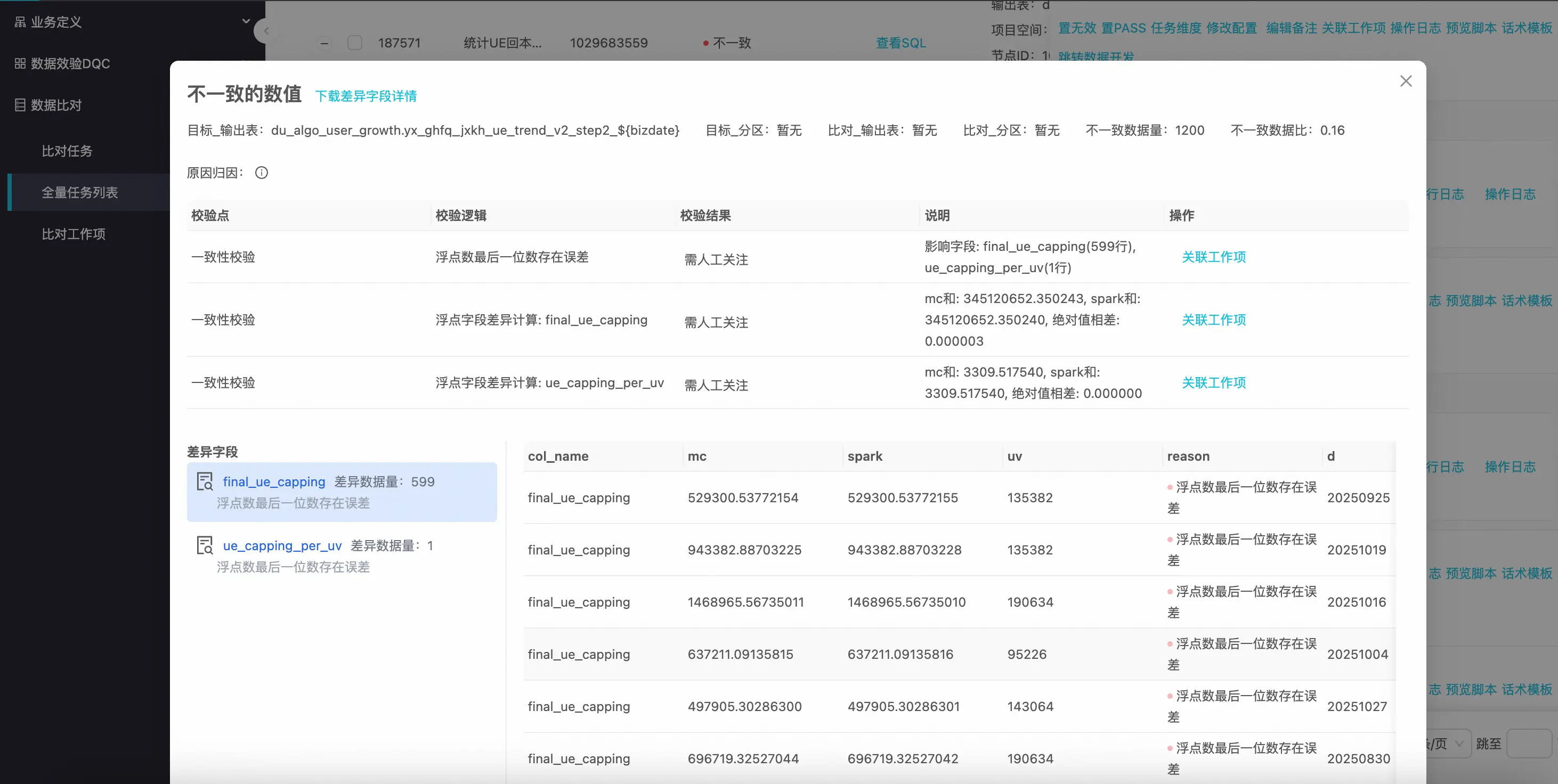
精準定位: 明確指出哪條記錄、哪個字段存在差異,並展示具體的源數據和目標數據值。
-
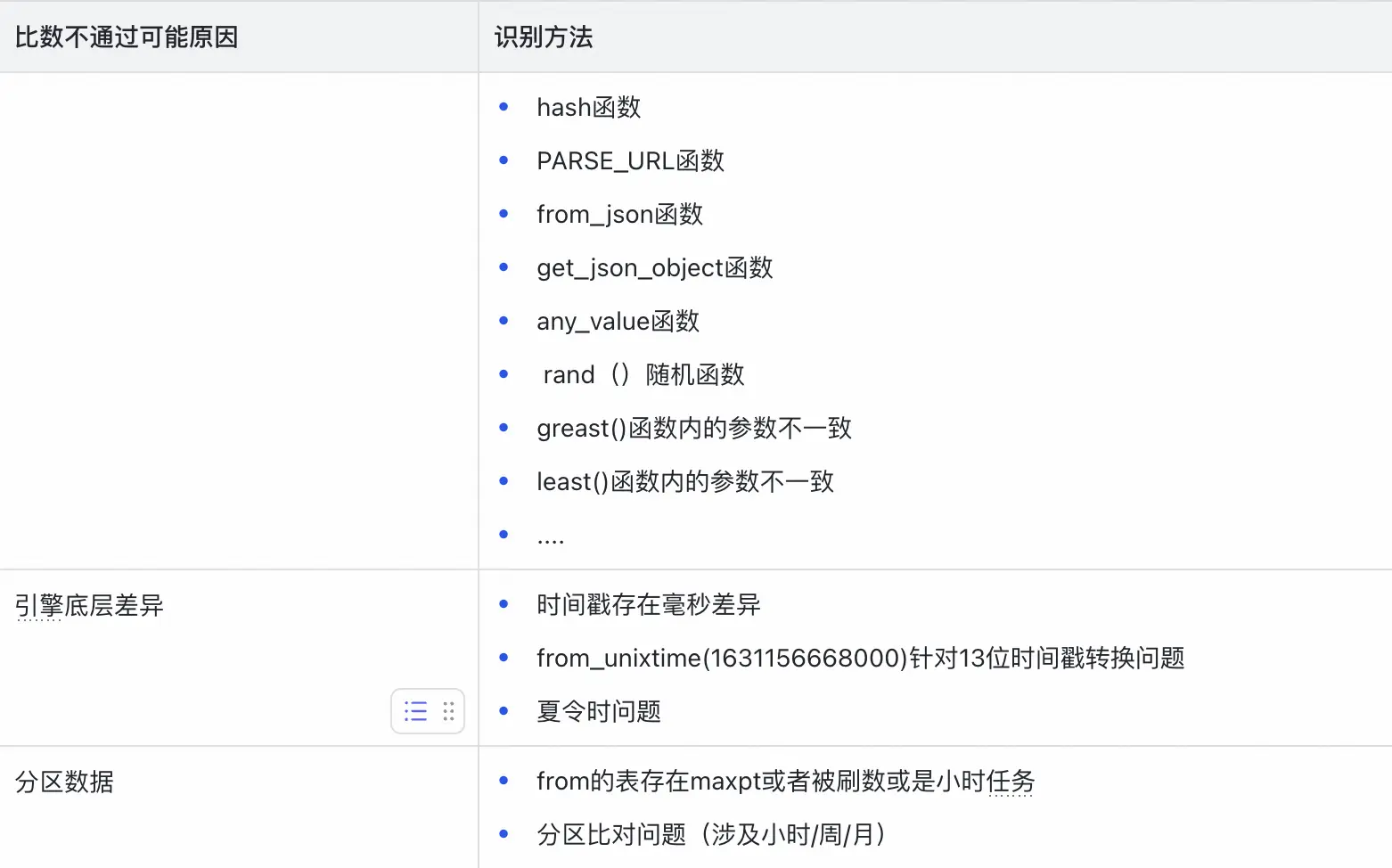
智能根因分析: 內置了多種差異模式識別規則,能夠自動分析並提示不一致的可能原因,例如:
-
精度問題:如浮點數計算1.0000000001與1.0的差異。
-
JSON序列化差異:如{"a":1, "b":2}與{"b":2, "a":1},在語義一致的情況下,因鍵值對順序不同而被標記為差異。同時系統會提示排序後一致。
-
空值處理差異:如NULL值與空字符串""的差異判定。
-
日期時區轉換問題:時間戳在不同時區下表示不同。
-
比對結果統計: 提供總數據量、一致數據量、不一致數據量及不一致率百分比,為項目決策提供清晰的量化依據。
-
比數人員根據平台分析的差異原因,決定是否手動標記通過或進行任務修復。
-
效果展示:

四、比數平台功能介紹
數據比對基本流程
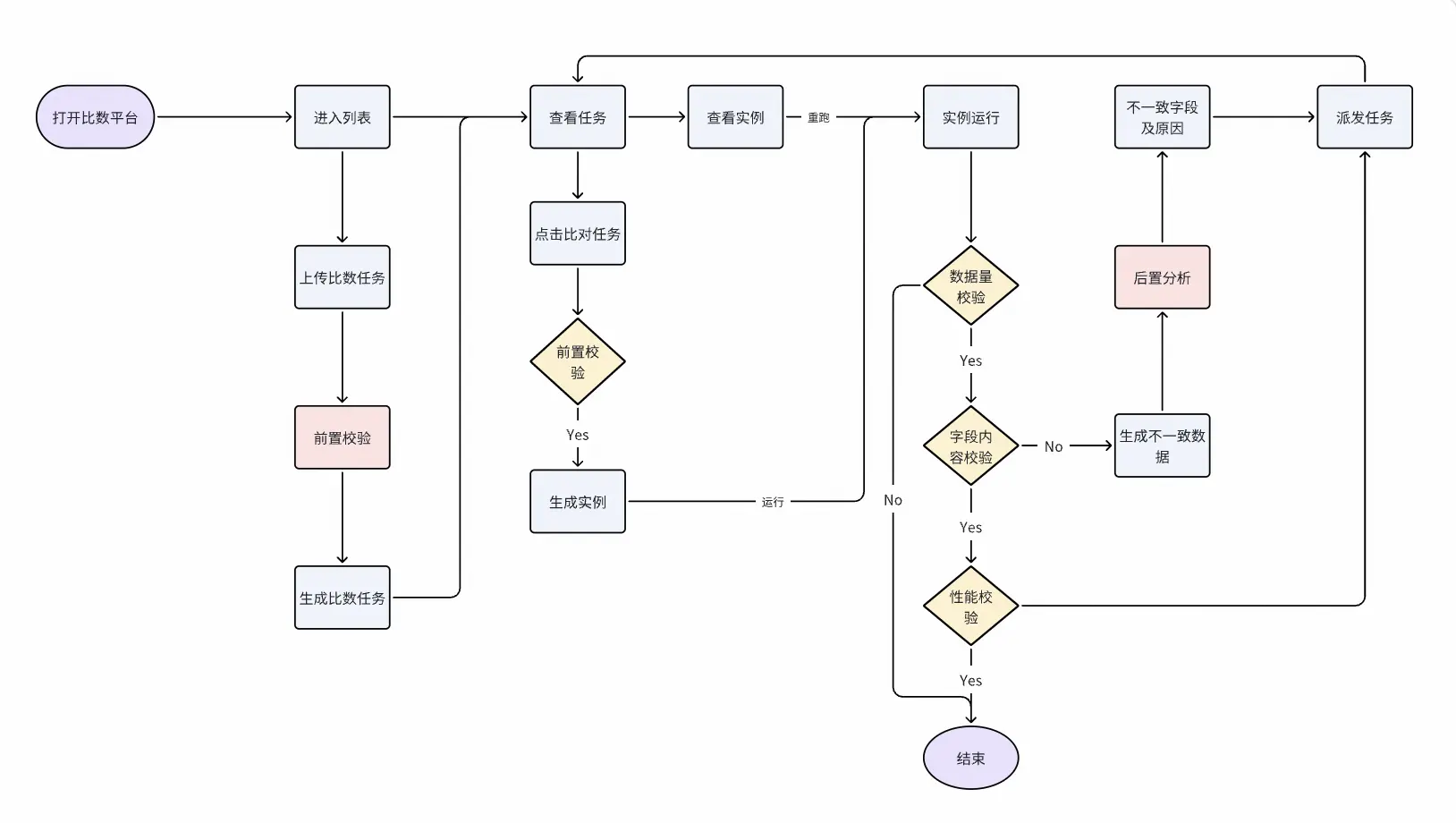
任務生成:三種比對模式
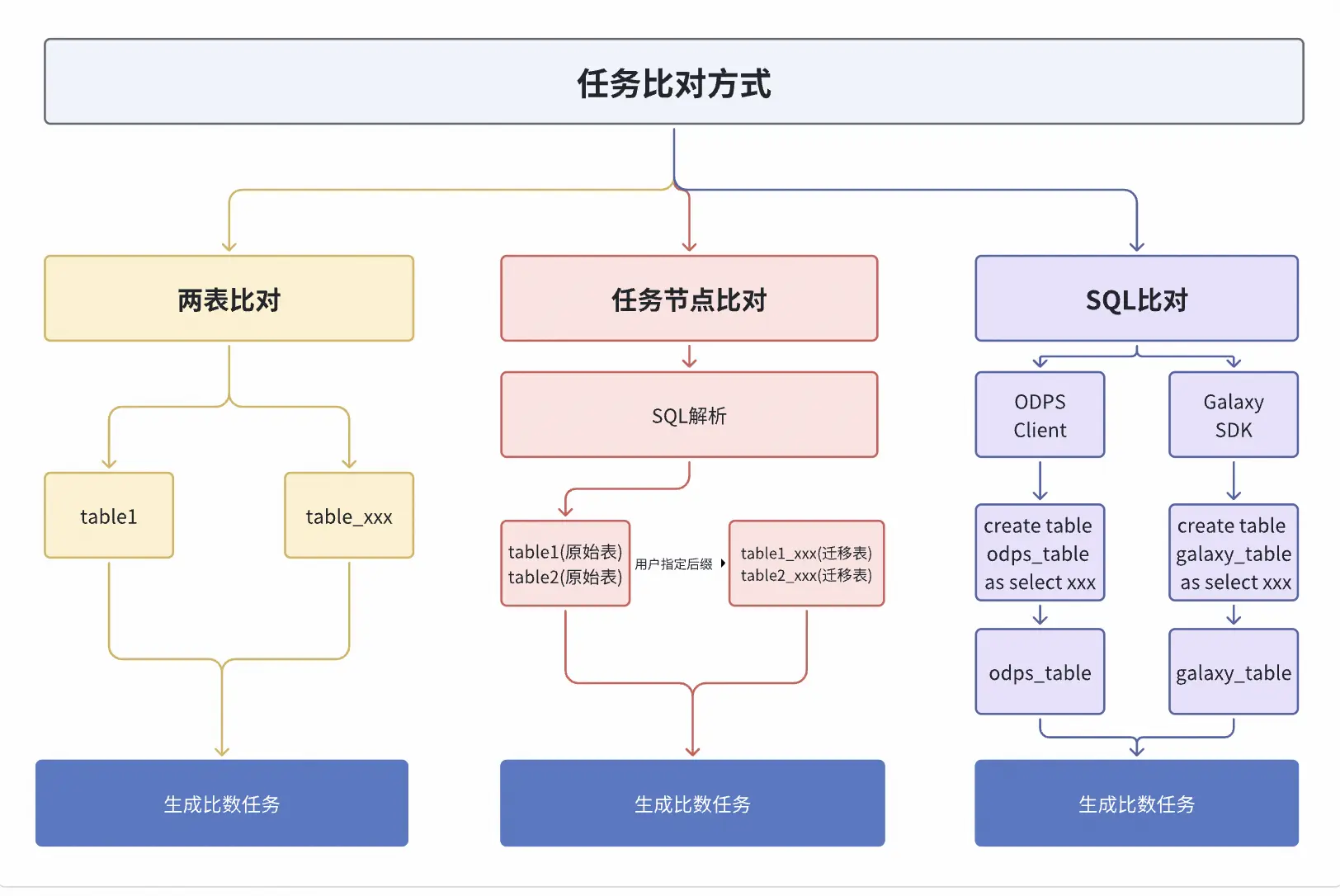
- 兩表比對: 最直接的比對方式。用户只需指定源表與目標表,平台即可啓動全量數據比對。它適用於臨時比對的場景。
- 任務節點比對: 一個任務可能輸出多個表,逐一配置這些表的比對任務繁瑣且易遺漏,任務節點比對模式完美解決了這一問題。用户只需提供任務節點ID,平台便會自動解析該節點對應的SQL代碼,提取出所有輸出表,並自動生成比對任務,極大地提升任務遷移比對效率。
- SQL查詢比對: 業務在進行SDK遷移只關心某些查詢在遷移後數據是否一樣,因此需要對用户提交的所有查詢SQL進行比對,平台會分別在ODPS和Spark引擎上執行該查詢,將結果集導出到兩張臨時表,再生成比對任務。
前置校驗:提前發現問題
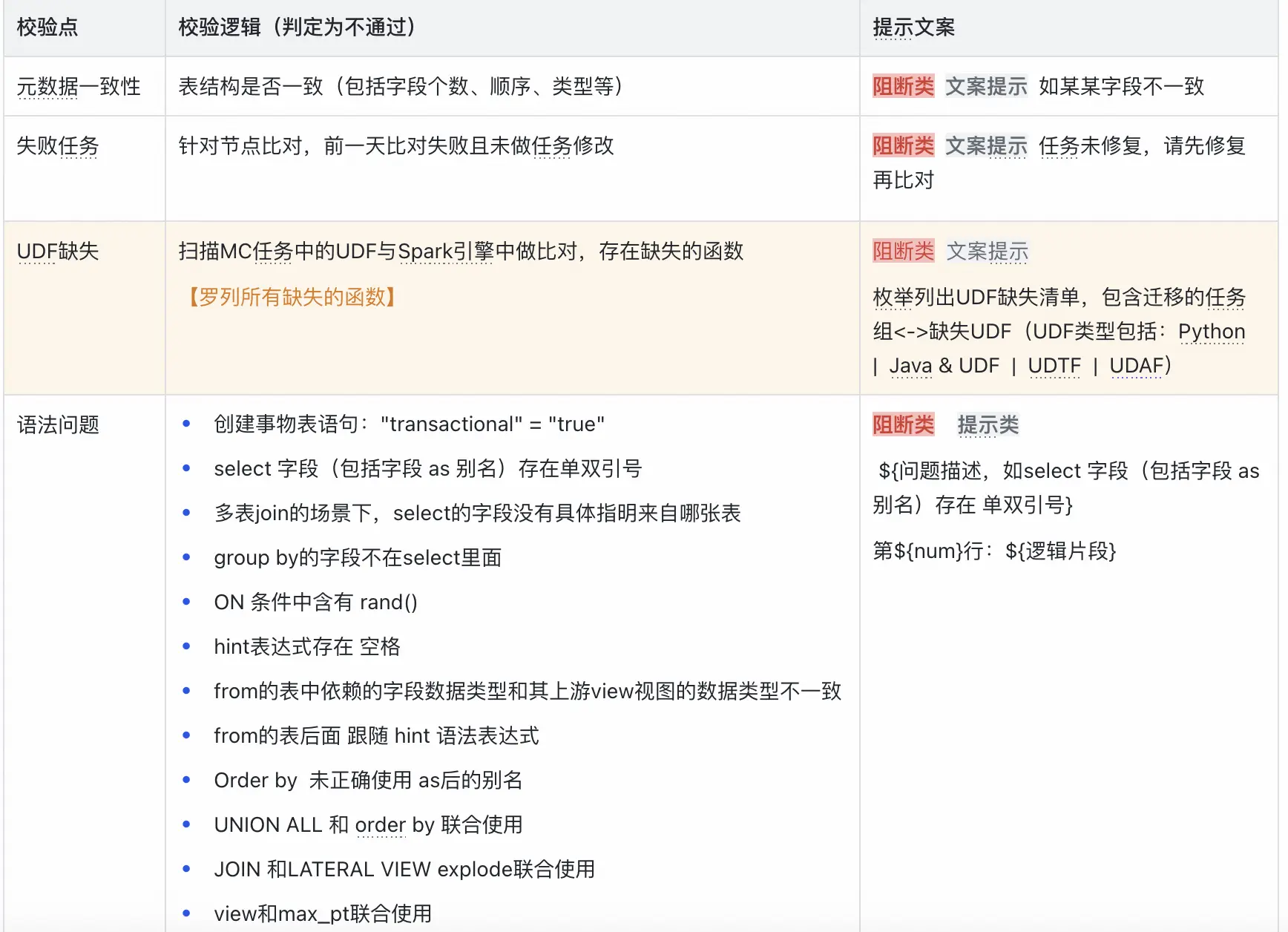
在啓動耗時的全量比對之前,需要對任務進行前置校驗,確保比對是在表結構一致、集羣環境正常的情況下進行,否則一旦啓動比數會佔用大量計算資源,最後結果還是比數不通過,會影響比數平台整體的運行效率。因此比數平台一般會針對如下問題進行前置攔截。
- 元數據一致性校驗: 比對雙方的字段名、字段類型、字段順序、字段個數是否一致。
- 函數缺失校驗: 針對Spark引擎,校驗SQL中使用的函數是否存在、是否能被正確識別,避免因函數不支持而導致的比對失敗。
- 語法問題校驗: 分析SQL語句的語法結構,確保其在目標引擎中能夠被順利解析,避免使用了某些特定寫法會導致數據出現不一致情況,提前發現語法層面問題,並對任務進行改寫。
更多校驗點如下:


破解比數瓶頸:資源分配與任務調度優化
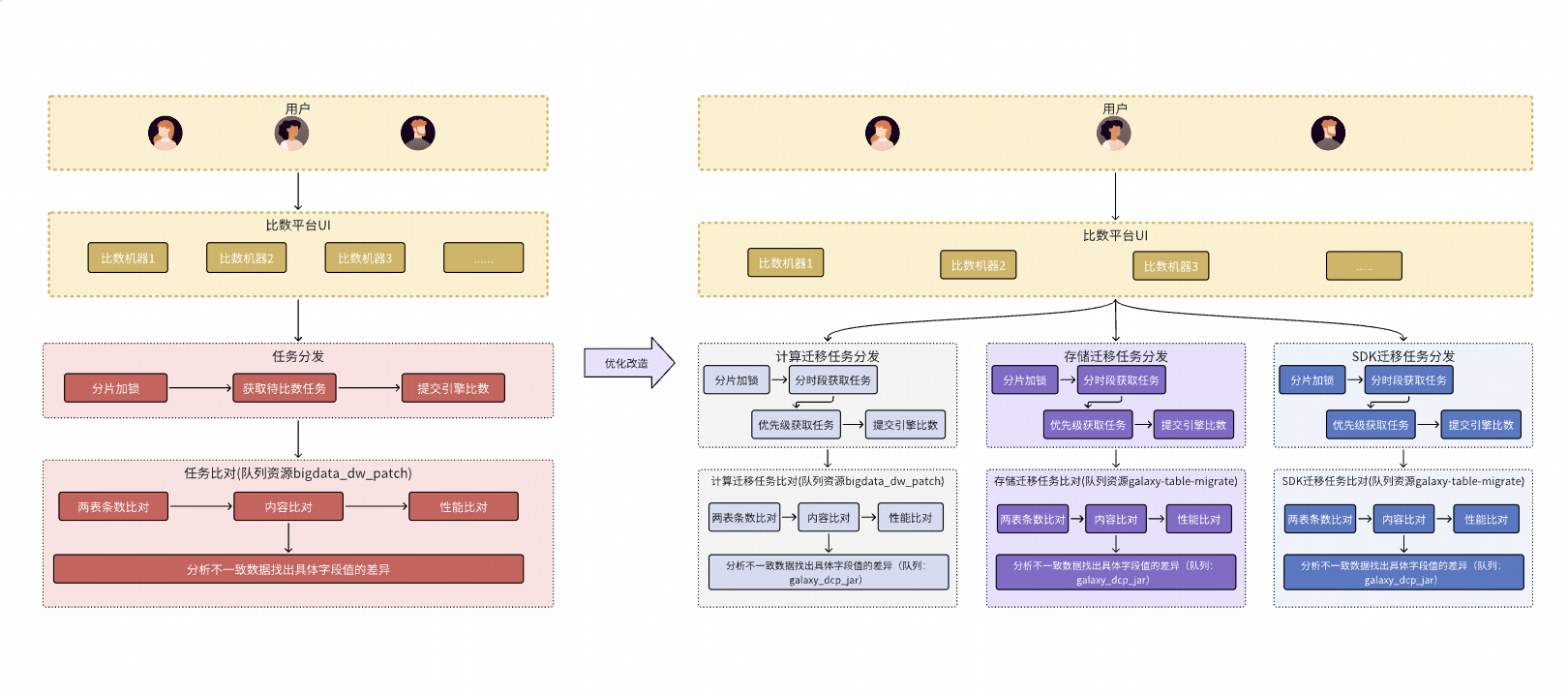
由於比數平台剛上線的時候只有計算遷移團隊在使用,後面隨着更多的團隊開始使用,性能遇到了如下瓶頸:
1.資源不足問題: 不同業務(計算遷移、存儲遷移、SDK遷移)的任務相互影響,基本比數任務與根因分析任務相互搶佔資源。
2.任務編排不合理: 沒有優先級導致大任務阻塞整體比數進程。
3.引擎參數設置不合理: 並行度不夠、數據分塊大小等高級參數。
針對以上問題比數平台進行了如下優化:
- 按不同業務拆分成多個隊列來運行,保證各個業務之間的比數任務可以同時進行,不會相互影響。
- 根因分析使用單獨的隊列,與數據比對任務的隊列分開,避免相互搶佔資源發生"死鎖"。
- 相同業務內部按批次分時段、分優先級運行,保障重要任務優先進行比對。
- 針對Spark引擎默認調優了公共參數、並支持用户自主設置其他高級參數。
通過以上優化達到到了如下效果:
- 比數任務從每天22點完成提前至18點前,同時支持比數同學自主控制高優任務優先執行,方便比數同學及時處理不一致任務。
- 通過優化資源隊列使用方式,使系統找不到主鍵輔助用户自主找主鍵接口響應時間從58.5秒降到 26.2秒。
五、比數平台收益分享
平台持續安全運行500+天,每日可完成2000+任務比對,有效比數128萬+次,0誤判。
- 助力計算遷移團隊節省45+人日/月,完成數據分析、離線數倉空間任務的比對、交割。
- 助力存儲遷移團隊完成20%+存儲數據的遷移。
- 助力引擎團隊完成800+批次任務的迴歸驗證,確保每一次引擎發佈的安全及高效。
- 助力SDK遷移團隊完成80%+應用的遷移。
六、未來演進方向
接下來,平台計劃在以下方面持續改進:
智能分析引擎: 針對Json複雜嵌套類型的字段接入大模型進行數據根因分析,找出不一致內容。
比對策略優化: 針對大表自動切分進行比對,降低比數過程出現因數據量大導致異常,進一步提升比對效率。
通用方案沉澱: 將典型的比對場景和解決方案能用化,應用到更多場景及團隊中去。
七、結語
比數平台是得物在遷移過程中,為了應對海量任務、大數據量、字段內容複雜多樣、異常數據難定位等挑戰,確保業務遷移後數據準確而專門提供的解決方案,未來它不單純是一個服務計算遷移、存儲遷移、SDK遷移、Spark版本升級等需要的數據比對工具,而是演進為數據平台中不可或缺的基礎設施。
往期回顧
1.得物App智能巡檢技術的探索與實踐
2.深度實踐:得物算法域全景可觀測性從 0 到 1 的演進之路
3.前端平台大倉應用穩定性治理之路|得物技術
4.RocketMQ高性能揭秘:承載萬億級流量的架構奧秘|得物技術
5.PAG在得物社區S級活動的落地
文 /Galaxy平台
關注得物技術,每週更新技術乾貨
要是覺得文章對你有幫助的話,歡迎評論轉發點贊~
未經得物技術許可嚴禁轉載,否則依法追究法律責任。
