隨着語音交互走進更多應用場景,越來越多團隊開始探索「能跑得快、夠可定製、還真能落地」的語音 AI 代理。而下面這份分享帶來了一條完整的工程路徑:從硬件到流式處理,再到端雲協同,讓語音 AI 真正具備可用性。
在現實工程中,語音 AI 的實現大致有三種形態:
- 本地運行,將模型直接部署在設備端,隱私好、響應快,但設備需要更強的算力。
- 遠程服務,設備只負責錄音和播放,將識別與生成完全交給雲端。模型最強,但延遲與穩定性是主要風險。
- 混合模式,也是最常用的方式:本地處理 VAD、喚醒詞、指令等即時任務,複雜推理解給服務器。延遲、成本、體驗都更平衡。
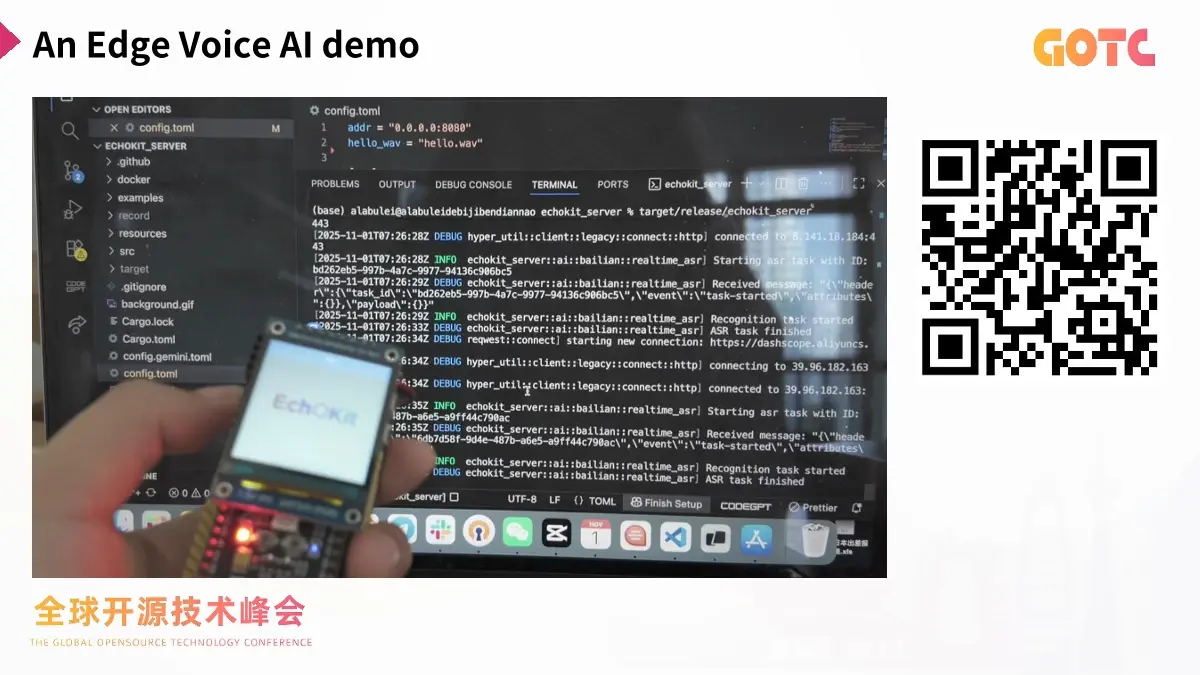
分享從介紹硬件實踐案例 EchoKit 開始。這是一套基於 ESP32 的低功耗設備方案,能承擔本地的小模型任務,如 VAD 與喚醒詞。同時,它配套的 EchoKit Server(由 Rust 編寫)能在雲端或局域網中調度本地與遠程 AI 服務,通過一個簡單的二進制文件與 YAML 配置完成部署,支持容器化運行。對於構建語音設備的團隊來説,硬件與服務端協同的能力尤為關鍵。
不過真正的挑戰來自延遲控制。
如果按串行流程執行:VAD → 上傳 → ASR → 推理 → 工具調用 → TTS → 下載,整套流程可能耗時 17~74 秒。這種速度顯然無法用於實際交互。
而通過流式處理,整個體驗完全不同。音頻邊上傳邊處理,ASR 幾乎在 1–2 秒內給出第一句文本,LLM 與 TTS 也能同步產出第一批結果,把總交互時間壓縮到 6~9 秒。再配合更快的模型與 KV cache 優化,時延可進一步降低至約 2 秒。甚至在更高級的流式架構中,ASR 輸出可以直接構建 LLM 的 KV cache,讓模型在一句話還沒説完時就提前開始推理。
當然,流式能力的基礎是穩定的音頻傳輸。0.5 秒的語音分片必須嚴格在 0.5 秒內完成上傳與下行,否則會明顯卡頓。相比 WebSocket,WebRTC 在流媒體傳輸上更可靠,而實際應用中諸如 Agora 的實時網絡可進一步減少抖動,保證交互順暢。
最終目標是實現:0.5 秒級別的端到端響應。

完整內容查看:https://www.oschina.net/doc/486
