編者按: 你是否曾經在配置 CUDA 環境時被"driver version mismatch"或"no kernel image for device"這類錯誤困擾,卻難以釐清"CUDA 版本"、"驅動版本"、"計算能力"之間的複雜關係?為何 nvidia-smi、nvcc 和 PyTorch 報告的"CUDA 版本"常常不一致?
我們今天為大家帶來的文章,作者的觀點是:CUDA 生態系統的混亂根源在於術語與組件的多重含義,只有通過一套嚴謹的本體論(ontology)釐清各組件的定義、層級關係與版本語義,才能從根本上理解並解決兼容性問題。
本文從術語辨析入手,逐一澄清"CUDA"、"driver"、"kernel"等關鍵概念的多重含義,進而剖析 CUDA 軟件棧的分層架構 ------ 從應用層的 Runtime API(libcudart),到底層的 Driver API(libcuda)與內核驅動(nvidia.ko),最終抵達 GPU 硬件。文章重點闡述了版本語義的多維性(計算能力、驅動版本、Toolkit 版本、Runtime/Driver API 版本)及其兼容性約束,並通過編譯模型、執行模型與典型故障場景,揭示版本不匹配的根本成因。文中還提供了實用的診斷工具指南與面向開發者、用户、PyTorch 及容器使用者的實踐建議。
作者 | James Akl
編譯 | 嶽 揚
CUDA 的術語存在嚴重的多重含義問題:"CUDA" 一詞本身至少指代五種不同的概念,"driver" 在不同上下文中含義也不同,而各種工具報告的版本號衡量的也是不同的子系統。本文提供了一套關於 CUDA 組件的嚴謹本體論(譯者注:ontology,指的是一種對某個領域內所有存在事物、其本質屬性及相互關係的正式、系統的描述和分類體系。):一種對 CUDA 生態系統中存在哪些內容、各組件間如何相互關聯、它們的版本語義、兼容性規則以及故障模式的系統性描述。為了消除歧義,每個術語都經過精確定義。只有先釐清了"CUDA"、"driver"、"kernel"這些術語的確切所指以及各組件之間的關係,我們才能有效地解決版本衝突和理解系統運作的邏輯。這是進行後續所有 CUDA 問題排查和系統管理的基礎。
01 CUDA 術語與歧義消除
1.1 術語"CUDA"
"CUDA" 一詞至少承載五種不同的含義:
1)CUDA 作為計算架構:由 NVIDIA 設計的並行計算平台和編程模型。
2)CUDA 作為指令集:NVIDIA 硬件支持的 GPU 指令集架構(ISA),按計算能力劃分版本(compute_8.0、compute_9.0 等)。
3)CUDA 作為源語言:用於編寫 GPU 代碼的 C/C++ 語言擴展(如 global、device 等)。
4)CUDA Toolkit:包含 nvcc、庫文件、頭文件和開發工具的開發套件。
5)CUDA Runtime:應用程序所鏈接的運行時庫(libcudart)。
當有人提到"CUDA 版本"時,可能指的是 Toolkit 版本、Runtime 版本、Driver API 版本或計算能力。要表達精確,必須明確限定具體所指。
1.2 術語"kernel"
在 GPU 計算的語境中,kernel 有兩種完全不同的含義:
1)操作系統內核:運行在特權內核空間中的操作系統內核。例如:Linux kernel(如版本 6.6.87)、Windows NT kernel、macOS XNU kernel。
2)CUDA kernel:帶有 global 修飾的 C++ 函數,在 GPU 上執行。當從主機代碼調用時,CUDA kernel 會以線程塊網格的形式啓動。
在本文中,OS kernel 始終指操作系統內核(Linux、Windows 等),CUDA kernel 始終指 GPU 函數。
1.3 術語"driver"
在計算領域,"driver" 是使操作系統能夠與硬件設備通信的軟件。在 CUDA 語境中,"driver" 包含以下兩種含義:
1)NVIDIA GPU Driver(也稱 "NVIDIA Display Driver"):運行在(OS)kernel 空間的驅動程序(Linux 上為(OS)kernel 模塊,Windows 上為(OS)kernel 驅動),用於管理 GPU 硬件。儘管歷史上被稱為"顯示驅動",但這個統一的驅動實際上處理了所有 GPU 操作:圖形渲染、計算任務、內存管理與調度。該名稱反映了 NVIDIA 從專注於圖形的 GPU 向通用計算加速器的演進過程。
- 以(OS)kernel 模塊形式安裝:nvidia.ko、nvidia-modeset.ko、nvidia-uvm.ko(Linux),或作為 Windows(OS)kernel 驅動。
- 使用獨立的版本號劃分:535.104.05、550.54.15 等。
2)CUDA Driver API:一個底層的 C 語言 API(Linux 上為 libcuda.so,Windows 上為 nvcuda.dll),提供對 GPU 功能的直接訪問。這是由 NVIDIA GPU 驅動包提供的用户態庫。
- 位置示例:/usr/lib/x86_64-linux-gnu/libcuda.so(Linux)。
- 其 API 版本不同於 GPU 驅動版本,但二者打包在同一驅動程序安裝包中。
NVIDIA GPU 驅動包同時包含(OS)kernel 組件((OS)kernel 模塊/驅動)和 libcuda 用户態庫。
02 組件架構
CUDA 生態系統由多個層級構成,每個層級都有其明確的職責。理解這種分層結構,是推理版本兼容性與系統行為的基礎。
2.1 系統層級
CUDA 軟件棧橫跨(OS)kernel 空間和用户空間:
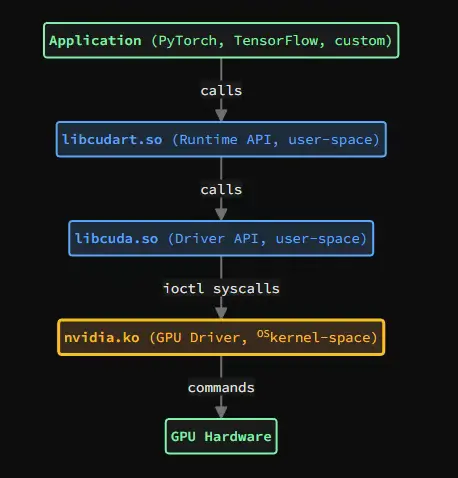
2.2 組件定義
libcuda.so / nvcuda.dll (Driver API,後端) :
- 由 NVIDIA GPU 驅動程序包提供。
- 操作系統內的安裝位置:
- Linux: /usr/lib/x86_64-linux-gnu/libcuda.so (或 /usr/lib64/libcuda.so)
- Windows: C:\Windows\System32\nvcuda.dll
- 提供底層原語:cuInit、cuMemAlloc、cuLaunchKernel 等。
- 通過系統調用與(OS)kernel 驅動通信:
- Linux: ioctl 系統調用 (用於與(OS)kernel 設備通信的 I/O 控制系統調用)
- Windows: 向(OS)kernel 驅動發起 DeviceIoControl 調用
- 其版本與 GPU 驅動程序版本綁定(例如,driver 535.x 提供支持 CUDA Driver API 12.2 的 libcuda.so/nvcuda.dll)。
libcudart.so / cudart64_*.dll (Runtime API,前端) :
- 由 CUDA Toolkit 提供(或隨 PyTorch 等應用程序打包)。
- 文件位置:
- Linux: libcudart.so (動態庫), libcudart_static.a (靜態庫)
- Windows: cudart64_.dll (動態庫), cudart_static.lib (靜態庫)
- 提供封裝後的高層 API:cudaMalloc、cudaMemcpy、cudaLaunchKernel 等。
- 其內部調用 libcuda.so/nvcuda.dll (Driver API) 來執行相關操作。
- 可靜態鏈接,也可動態鏈接。
- 應用程序代碼通常直接使用 Runtime API,而非使用 Driver API。
CUDA Toolkit:
- 開發套件,包含:
- nvcc: 用於編譯 (CUDA)kernel 代碼的編譯器。
- libcudart/cudart64_*.dll: 運行時庫(Runtime library)。
- 頭文件 (cuda.h, cuda_runtime.h)。
- 數學庫:cuBLAS、cuDNN、cuFFT 等。
- 性能分析和調試工具:nvprof、nsight、cuda-gdb。
- 版本獨立於 GPU 驅動:例如 toolkit 12.1、12.4 等。
- 在編譯 (CUDA)kernel 代碼時需要此工具包。
- 運行時需要運行時庫(libcudart),但不需要 nvcc 和頭文件。
- 安裝路徑:
- Linux: /usr/local/cuda/ (默認)
- Windows: C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.x\
NVIDIA GPU 驅動程序:
- 操作系統層級的驅動程序,用於管理 GPU 硬件。
- 提供(OS)kernel 模塊 (Linux 上的 nvidia.ko,Windows 上的(OS)kernel 驅動) 和用户空間庫 (Linux/macOS 上的 libcuda.so,Windows 上的 nvcuda.dll)。
- 必須在所有運行 CUDA 應用程序的機器上安裝。
- 通過向前兼容支持多個 CUDA Runtime API 版本(較新的驅動支持較舊的運行時版本)。
- 注意:自 CUDA 10.2 (2019) 起,NVIDIA 已棄用對 macOS 的 CUDA 支持。現代 CUDA 開發主要面向 Linux 和 Windows。
2.3 分層架構模型(Layered architecture model)
CUDA 軟件棧將應用層和系統層之間的職責分離:
- 前端(應用層) :libcudart.so + 應用程序代碼。提供高層 Runtime API(如 cudaMalloc、cudaMemcpy 等)。由應用程序打包或鏈接使用。
- 後端(系統層) :libcuda.so + GPU 驅動(nvidia.ko)。提供底層 Driver API 和硬件管理功能。系統級安裝,在執行時必須存在。
這種職責分離使應用程序能使用統一的高層 API,而後端負責處理與硬件相關的具體細節。libcudart 將 Runtime API 調用轉換為 Driver API 調用,再由 libcuda 通過(OS)kernel 驅動執行。
2.4 編譯期組件 vs. 執行期組件
術語説明:"執行期"(execution-time)指應用程序運行時(即 runtime),這與"Runtime API"(libcudart)這一特定 CUDA 庫不同 ------ 後者是執行期所必需的一個具體庫。
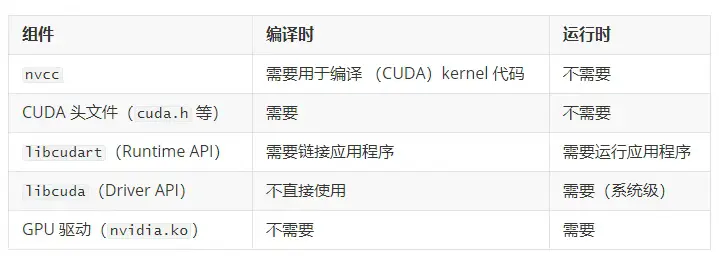
示例:
PyTorch 的編譯過程:
- PyTorch 使用 CUDA Toolkit 12.1 進行編譯(即構建過程中鏈接並使用了 toolkit 12.1 的頭文件和庫文件)。
- 編譯期:使用 toolkit 12.1 中的 nvcc、頭文件和 libcudart。
- 執行期:PyTorch 會打包或依賴 libcudart.so(通常靜態鏈接或隨包分發),並調用系統 GPU 驅動提供的 libcuda.so。
- 系統必須安裝支持 CUDA Driver API 版本 ≥ PyTorch 所需版本的 GPU 驅動(本例中 ≥ 12.1)。
03 版本語義
CUDA 生態系統擁有多套獨立的版本編號體系。每個版本號衡量的是系統的不同方面。混淆這些版本是造成誤解的主要根源。
3.1 計算能力(Compute capability)
計算能力(CC)定義了 GPU 的指令集和硬件特性。這是 GPU 硬件本身的屬性,而非軟件屬性:
- 格式:X.Y,其中 X 為主版本號,Y 為次版本號(例如 8.0、9.0)。
- 由 GPU 硬件決定:RTX 4090 的 CC 為 8.9,H100 的 CC 為 9.0。
- 可通過 nvidia-smi 或 cudaGetDeviceProperties() 查詢計算能力(Compute capability )。
GPU 代碼可編譯為兩種形式:
- SASS(Shader Assembly):針對特定計算能力(CC)編譯的 GPU 專屬機器碼。可直接在匹配該 CC 的硬件上運行,但無法在不同計算能力(CC)的硬件間移植。
- PTX(Parallel Thread Execution):NVIDIA 的虛擬指令集架構(ISA)和中間表示。是一種與平台無關的字節碼,可在執行時由驅動程序即時編譯(JIT-compiled)為適用於任何支持 GPU 架構的原生 SASS。
二進制兼容性規則:
SASS(編譯後的機器碼)具有嚴格的兼容性限制:
- 不同計算能力之間無法保證二進制兼容。例如,為 CC 8.0 編譯的 SASS 通常無法在 CC 8.6 硬件上運行,即使兩者主版本同為 8.x ------ 不同 CC 可能採用不同的指令編碼方式。
- SASS 無法在更舊的硬件上運行:CC 8.0 的 SASS 不能在 CC 7.5 上運行(舊硬件缺少所需指令)。
- SASS 無法跨主版本運行:CC 8.0 的 SASS 不能在 CC 9.0 硬件上運行(主版本不同,ISA 也不同)。
PTX(中間表示)提供前向兼容性:
- PTX 具備跨計算能力(compute capabilities)的可移植性:為 CC 8.0 編譯生成的 PTX 代碼,在程序運行時(execution time)可以被 NVIDIA 驅動程序即時編譯(JIT-compiled)成適用於任何它所支持的 GPU 架構的原生 SASS 機器碼,比如 CC 8.6、8.9、9.0 等。
- 要求:二進制文件必須包含 PTX,且驅動程序必須支持目標 GPU 架構。
- 性能考量:JIT 編譯會在首次(CUDA)kernel 啓動時帶來一次性的開銷;預編譯的 SASS 可避免此開銷。
- 建議:同時包含針對已知目標架構的 SASS 代碼和用於未來 GPU 向前兼容的 PTX 代碼。
3.2 GPU 驅動程序版本
格式(Linux):R.M.P(例如 535.104.05、550.54.15)
- R:主發佈版本(對應所支持的 CUDA Driver API 主版本)
- M:次發佈版本
- P:補丁版本
格式(Windows):顯示驅動使用不同的版本編號(例如 31.0.15.3623),但 CUDA 組件報告的版本仍採用類似的 R.M 編號方式。
每個驅動版本都有一個所支持的 CUDA Driver API 最高版本。例如:
- 驅動 535.x 版本支持 CUDA Driver API 12.2
- 驅動 550.x 版本支持 CUDA Driver API 12.4
關鍵點:驅動版本決定了所能支持的 CUDA Driver API 最高版本,該版本必須 ≥ 應用程序所使用的 Runtime API 版本。
可通過 nvidia-smi 查詢驅動版本及其支持的最高 CUDA Driver API 版本。
3.3 CUDA Toolkit 版本
格式:X.Y.Z(例如 12.1.0、12.4.1)
- 對應開發階段安裝的 toolkit 版本。
- 決定了 nvcc 版本、libcudart 版本以及可用的 API 功能。
- 可通過 nvcc --version 查詢 Toolkit 版本(需已安裝 Toolkit)。
3.4 CUDA Runtime API 版本
- 由 libcudart 所支持的 API 版本。
- 通常與 Toolkit 版本一致(Toolkit 12.1 提供的 libcudart 對應 Runtime API 12.1)。
- 應用程序可能會捆綁特定版本的 libcudart。
- 可在應用程序代碼中通過 cudaRuntimeGetVersion() 查詢 Runtime API 版本。
3.5 CUDA Driver API 版本
- 由 libcuda.so 提供的 API 版本。
- 由 GPU 驅動版本決定。
- 必須 ≥ 應用程序所使用的 Runtime API 版本。
- 可在應用程序代碼中通過 cudaDriverGetVersion() 查詢,或通過 nvidia-smi 查看(顯示為 "CUDA Version")。
3.6 PyTorch 的 CUDA 版本
當 PyTorch 報告 CUDA 版本時,指的是:
- 編譯期 Toolkit 版本:PyTorch 編譯時所鏈接的 CUDA Toolkit 版本。可通過 torch.version.cuda 查詢(例如 "12.1")。
- 運行期驅動版本:系統在運行時可用的 CUDA Driver API 版本。可通過 torch.cuda.is_available() 及驅動檢查確認。
PyTorch 可能使用 Toolkit 12.1 編譯(構建時鏈接該版本),但運行在支持 CUDA Driver API 12.4 的系統驅動上。只要 Driver API 版本 ≥ Toolkit 的 CUDA 版本(12.4 ≥ 12.1),這種配置就是有效的。
04 版本兼容性
CUDA 中的版本兼容性遵循一些特定規則。理解這些規則對於確保應用程序在不同系統上都能夠正確運行非常重要。
術語説明:兼容性是從後端(驅動 + GPU 硬件)的角度描述的。 "前向兼容"(Forward compatible) 指後端能夠與基於較舊 Toolkit 版本構建的前端協同工作(例如:driver version 12.4 可運行使用 Toolkit 12.1 的 libcudart 構建的應用程序)。 "後向兼容"(Backward compatible) 指後端能夠與基於較新 Toolkit 版本構建的前端協同工作(例如:driver version 12.1 可運行使用 Toolkit 12.4 的 libcudart 構建的應用程序)。CUDA 驅動支持前向兼容(可運行舊版前端),但不支持後向兼容(無法運行新版前端)。
4.1 前向兼容:舊前端 + 新後端
CUDA 在以下維度上保持前向兼容:
Driver API 與 Runtime API 的前向兼容
- 支持 CUDA Driver API 12.4 的驅動,可運行使用 Runtime API 12.1、12.2、12.3 或 12.4 構建的應用程序。
- 新驅動支持舊版 Runtime。
- 應用程序無需重新編譯,即可在安裝了新驅動的系統上運行。
PTX 提供跨計算能力(compute capabilities)的前向兼容
- 為 CC 8.0 編譯的 PTX 代碼,可以被驅動程序進行 JIT 編譯,從而兼容運行在 CC 8.6、8.9 甚至 9.0 的硬件上(甚至可以跨越主版本的界限)。
- 要求:二進制文件必須包含 PTX,且驅動必須支持目標 GPU 架構。
- 應用程序無需重新編譯即可在新 GPU 上運行,代價是一次性的 JIT 編譯開銷。
4.2 後向兼容:新前端 + 舊後端
CUDA 不支持後向兼容:
Driver API 無法支持較新的 Runtime API
- 僅支持 CUDA Driver API 12.1 的驅動,無法運行需要 Runtime API 12.4 的應用程序。
- 舊驅動不支持新版 Runtime。
- 解決方法:升級 GPU 驅動以支持所需的 Driver API 版本。
SASS 無法在更舊的硬件上運行
- 為 CC 8.0 編譯的 SASS 無法在 CC 7.5 硬件上運行(較舊的 GPU 缺少必要的指令)。
- 解決方法:針對較舊的計算能力重新編譯,或在二進制文件中包含 PTX 以便進行 JIT 編譯。
SASS 在不同計算能力之間不具備可移植性
- 為 CC 8.0 編譯的 SASS 通常無法在 CC 8.6 或 9.0 硬件上運行。
- 解決方法:在二進制文件中包含 PTX 以實現前向兼容,或為所有目標架構分別編譯 SASS。
4.3 兼容性要求
要使 CUDA 應用程序成功執行,必須同時滿足以下兩個獨立條件:
條件 1:API 版本兼容
Driver API 版本 ≥ Runtime API 版本
即:由 libcuda.so 提供的 Driver API 版本(由 GPU 驅動決定)必須 ≥ 應用程序所使用的 libcudart 提供的 Runtime API 版本(由應用捆綁或鏈接)。
條件 2:GPU 代碼可用
以下至少一項必須成立:
二進制文件包含與 GPU 計算能力匹配的 SASS
或
二進制文件包含 PTX 且驅動支持對該 GPU 架構進行 JIT 編譯
應用程序二進制文件必須包含可執行的 GPU 代碼,形式可以是:
- 與 GPU 計算能力匹配的預編譯 SASS(執行最快,無 JIT 開銷)
- PTX 中間表示,驅動程序可將其 JIT 編譯為 SASS 代碼(支持向前兼容,產生一次性 JIT 開銷)
常見故障模式:
- cudaErrorInsufficientDriver:違反條件 1(Driver API 版本 < Runtime API 版本)
- cudaErrorNoKernelImageForDevice:違反條件 2(既無匹配的 SASS,也無可用的 PTX)
05 診斷工具與版本信息查詢
不同的工具會報告不同的版本號。清楚每個工具檢測的是什麼,對於排查兼容性問題至關重要。
5.1 nvidia-smi
nvidia-smi(NVIDIA System Management Interface)用於查詢 GPU 驅動程序,並報告與驅動相關的信息。
報告內容包括:
- GPU 驅動版本(例如 535.104.05)
- 支持的最高 CUDA Driver API 版本(例如 12.2)
- GPU 型號(例如 "NVIDIA GeForce RTX 4090")
- 計算能力(可通過 nvidia-smi --query-gpu=compute_cap --format=csv 查詢)
不報告以下內容:
- CUDA Toolkit 版本(系統可能未安裝 Toolkit)
- 應用程序使用的 Runtime API 版本
- nvcc 編譯器版本
示例輸出:
Driver Version: 535.104.05 CUDA Version: 12.2
- 535.104.05:系統上安裝的 GPU 驅動版本
- 12.2:該驅動所支持的最高 CUDA Driver API 版本(版本 ≤ 12.2 的應用程序才可以正常運行)
5.2 nvcc --version
報告內容包括:
- 已安裝的 CUDA Toolkit 版本(例如 12.1.0)
- nvcc 編譯器版本(與 Toolkit 版本一致)
不報告以下內容:
- GPU 驅動版本
- 當前使用的 Runtime API 版本
- 當前使用的 Driver API 版本
可能無法使用的情況:
- 系統僅安裝了驅動,未安裝 CUDA Toolkit
- 應用程序僅捆綁了 libcudart,未包含完整的 Toolkit
- 在容器中運行,且容器鏡像僅包含運行時(runtime-only),不含 Toolkit
5.3 torch.version.cuda
報告內容:
- PyTorch 編譯時所鏈接的 CUDA Toolkit 版本(例如 "12.1")
不報告以下內容:
- 驅動版本
- 系統當前可用的 Runtime Driver API 版本
5.4 torch.cuda.is_available()
報告內容:
- PyTorch 是否能訪問支持 CUDA 的 GPU
- 要求驅動與運行時版本兼容
返回布爾值,指示 CUDA 是否可用。若返回 False,通常表明存在版本不匹配或缺少 GPU 驅動。
5.5 cudaRuntimeGetVersion() 和 cudaDriverGetVersion()
可在應用程序代碼中以編程方式查詢:
- cudaRuntimeGetVersion():Runtime API 版本(來自 libcudart)
- cudaDriverGetVersion():Driver API 版本(來自 libcuda)
示例:
int runtimeVersion, driverVersion;
cudaRuntimeGetVersion(&runtimeVersion); // 例如 12010(對應 12.1)
cudaDriverGetVersion(&driverVersion); // 例如 12040(對應 12.4)
06 編譯模型與執行模型
6.1 編譯流水線
編譯 CUDA 代碼時:
1)源代碼(.cu 文件):包含(CUDA)kernel 定義(global 函數)和主機端代碼。
2)nvcc 編譯過程:
- 將設備端代碼(GPU)與主機端代碼(CPU)分離。
- 設備端代碼被編譯為指定計算能力(compute capabilities)的 PTX(中間表示)和/或 SASS(GPU 機器碼)。
- 主機端代碼由主機編譯器編譯(例如 Linux 上的 g++,Windows 上的 cl.exe)。
3)鏈接階段:
- 目標文件與 libcudart(Runtime API)鏈接。
- 生成的二進制文件包含主機代碼和內嵌的 GPU 代碼(PTX/SASS)。
為目標計算能力進行編譯配置,nvcc 使用 -arch 和 -code 編譯選項:
- -arch=compute_XY:設置虛擬架構(PTX 功能級別),決定編譯時可使用的 CUDA 特性。
- -code=sm_XY:為特定 GPU 架構(CC X.Y)生成 SASS(原生機器碼)。
- -code=compute_XY:在二進制文件中嵌入 CC X.Y 的 PTX,用於前向兼容。
- 可通過逗號分隔指定多個 -code 目標。
默認行為:如果僅指定 -arch=compute_XY 而未指定 -code,nvcc 會隱式為該架構同時生成 sm_XY SASS 和 compute_XY PTX。
最佳實踐:始終同時指定 -arch(虛擬架構)和 -code(真實架構)。雖然可以單獨使用 -code 而不指定 -arch,但 nvcc 會推斷 PTX 級別,這可能不符合預期。
示例:
nvcc -arch=compute_80 -code=sm_80,sm_86,sm_89,compute_80 kernel.cu -o app
此命令會生成四種輸出:
- SASS(分別對應 CC 8.0(A100)、8.6(RTX 3090/3080)、8.9(RTX 4090/4080))
- CC 8.0 的 PTX,用於未來 GPU 的前向兼容
在執行時:
- 在 A100(CC 8.0)上:直接加載 sm_80 SASS
- 在 RTX 3090(CC 8.6)上:直接加載 sm_86 SASS
- 在 RTX 4090(CC 8.9)上:直接加載 sm_89 SASS
- 在 H100(CC 9.0)上:沒有匹配的 SASS,因此驅動程序將 CC 8.0 的 PTX JIT 編譯為適用於 CC 9.0 的 SASS
6.2 執行模型
當應用程序運行時:
1)應用程序調用 cudaMalloc、cudaMemcpy、cudaLaunchKernel 等(Runtime API)。
2)libcudart 將這些調用轉換為 Driver API 調用(如 cuMemAlloc、cuMemcpyHtoD、cuLaunchKernel)。
3)libcuda.so 通過 ioctl 系統調用與(OS)kernel 驅動程序通信。
4)驅動程序在 GPU 硬件上調度(CUDA)kernel 執行。
5)GPU 執行(CUDA)kernel(SASS 指令),處理數據並返回結果。
傳輸內容説明:當(CUDA)kernel 被"啓動"時,主機不會將 C++ 源代碼發送到 GPU。而是:
- 預編譯的 GPU 機器碼(SASS)或 PTX 已在編譯時由 nvcc 嵌入應用程序二進制文件中。
- 應用程序啓動時,驅動將合適的代碼加載到 GPU 內存:
- 若存在與 GPU 計算能力匹配的 SASS,則直接加載 SASS。
- 若僅有 PTX,則驅動將 PTX JIT 編譯為該 GPU 架構的 SASS,再加載執行。
- (CUDA)kernel 啓動時,主機指定:
- 網格/塊維度(線程塊的數量,每個線程塊中的線程數量)
- (CUDA)kernel 參數(傳遞給(CUDA)kernel 的函數參數)
- 共享內存大小
- GPU 的硬件調度器在多個線程塊上並行執行 SASS 代碼。
該執行模型並非網絡層面上的 RPC(遠程過程調用),但在概念上有相似之處:
- 命令提交:主機將命令(如(CUDA)kernel 啓動、內存傳輸)放入命令緩衝區。
- 驅動解析:驅動程序將命令翻譯為 GPU 特定的操作。
- 異步執行:GPU 獨立執行;主機可繼續執行其他任務,或通過 cudaDeviceSynchronize() 進行同步。
該編程模型類似於遠程執行:主機代碼在一個獨立的處理器(GPU)上調用操作,該處理器擁有自己的內存空間和指令集。
07 版本不匹配場景
場景 1:Runtime 版本 > Driver 版本
環境配置:
- GPU 驅動支持 CUDA Driver API 12.1。
- 應用程序使用 Runtime API 12.4 構建。
結果:
- 應用程序調用 libcudart(Runtime API 版本 12.4)。
- libcudart 調用 libcuda.so(由 GPU 驅動提供,Driver API 版本 12.1)。
- libcuda.so 不支持 Runtime API 12.4 所需的新 Driver API 功能。
故障:應用程序崩潰或返回 cudaErrorInsufficientDriver。
解決思路:升級 GPU 驅動至支持 CUDA Driver API ≥ 12.4 的版本。
場景 2:編譯的計算能力 > GPU 計算能力
環境配置:
- 代碼為 CC 8.0 編譯(例如 A100)。
- 在 CC 7.5 硬件上運行(例如 RTX 2080 Ti)。
結果:
- 驅動嘗試加載 CC 8.0 的(CUDA)kernel 代碼。
- GPU 不支持 CC 8.0 指令。
故障:cudaErrorNoKernelImageForDevice 或類似錯誤。
解決思路:
- 為支持 CC 7.5 而重新編譯代碼(-arch=compute_75)。
- 或者在二進制文件中包含用於 JIT 編譯的 PTX(例如使用 -arch=compute_75 且不指定僅 sm_ 的 -code)。
場景 3:缺少用於前向兼容的 PTX
環境配置:
- 代碼使用 -code=sm_80 編譯(僅包含 CC 8.0 的 SASS,未嵌入 PTX)。
- 在 CC 9.0 的新 GPU 上運行(例如 H100)。
結果:
- 二進制文件僅包含用於 CC 8.0 的 SASS。
- 沒有可用於 JIT 編譯的 PTX。
- CC 8.0 的 SASS 與 CC 9.0 不兼容(主版本不同,ISA 不同)。
故障:cudaErrorNoKernelImageForDevice ------ 二進制文件中找不到兼容的(CUDA)kernel 鏡像。
解決思路:
- 重新編譯幷包含 PTX:-arch=compute_80 -code=sm_80,compute_80。
- 在 -code 參數中使用 compute_80 確保 PTX 代碼被嵌入二進制文件。
- 在 CC 9.0 硬件上執行時,驅動會將 PTX 代碼 JIT 編譯為適用於 CC 9.0 的 SASS。
場景 4:PyTorch Toolkit 版本 vs. 驅動版本
環境配置:
- PyTorch 使用 CUDA Toolkit 12.1 編譯。
- 系統驅動支持 CUDA 12.4。
結果:
- PyTorch 捆綁或鏈接 libcudart(版本 12.1)。
- 驅動提供 libcuda.so(版本 12.4)。
- 12.4 ≥ 12.1:成功,無問題。
環境配置(反向):
- PyTorch 使用 CUDA Toolkit 12.4 編譯。
- 系統 GPU 驅動僅支持 CUDA Driver API 12.1。
結果:
- PyTorch 運行時所執行的調用,需要使用 Driver API 12.4 版本才提供的功能。
- libcuda.so(Driver API 12.1)不支持這些功能。
故障:cudaErrorInsufficientDriver 或運行時錯誤。
解決思路:升級 GPU 驅動至支持 CUDA Driver API ≥ 12.4 的版本。
場景 5:系統安裝了多個 CUDA Toolkit
環境配置:
- 系統在 /usr/local/cuda-12.1 安裝了 Toolkit 12.1。
- 系統在 /usr/local/cuda-12.4 安裝了 Toolkit 12.4。
- PATH 指向 /usr/local/cuda-12.1/bin。
- 應用程序使用 Toolkit 12.4 編譯。
結果:
- nvcc --version 報告版本號為 12.1(來自 PATH)。
- 應用程序實際使用 Toolkit 12.4 的 libcudart。
- nvcc --version 報告的版本與應用程序運行時(runtime)版本不一致。
注意:nvcc --version 報告的是 PATH 中的 Toolkit,而非應用程序實際鏈接的版本。應用程序可能捆綁或鏈接了不同版本的 Toolkit。
解決思路:通過 ldd ./app 檢查應用程序實際鏈接的庫,以確定真實的 libcudart 版本。
場景 6:Docker 容器僅有 CUDA 運行時(runtime),無 Toolkit
環境配置:
- 容器鏡像基於 nvidia/cuda:12.1-runtime。
- 應用程序需要在運行時(runtime)使用 nvcc 編譯(CUDA)kernel 代碼。
結果:
- 運行時鏡像包含 libcudart,但不包含 nvcc 或頭文件。
- nvcc 未找到。
故障:nvcc not found。
解決思路:
- 使用 nvidia/cuda:12.1-devel 鏡像,其中包含完整 Toolkit。
- 或在運行時鏡像中單獨安裝 Toolkit。
注意:運行時鏡像 vs. 開發鏡像:
- 運行時鏡像(-runtime):包含運行 CUDA 應用所需的 libcudart 和庫,不含 nvcc 或頭文件。
- 開發鏡像(-devel):包含完整 Toolkit(nvcc、頭文件、庫),用於編譯 CUDA 代碼。
場景 7:libcudart 的靜態鏈接 vs. 動態鏈接
環境配置:
- 應用程序靜態鏈接 libcudart_static.a(Toolkit 12.1)。
- 系統驅動支持 CUDA 12.4。
結果:
- 應用程序內嵌了 libcudart 代碼(版本 12.1)。
- libcudart 調用 libcuda.so(版本 12.4)。
- 12.4 ≥ 12.1:成功。
環境配置(反向):
- 應用程序靜態鏈接 libcudart_static.a(Toolkit 12.4)。
- 系統驅動支持 CUDA 12.1。
結果:
- 內嵌的 libcudart(版本 12.4)調用 libcuda.so(版本 12.1)。
- 12.1 < 12.4:失敗。
注意:靜態鏈接會將 libcudart 打包進應用程序二進制文件,其版本在編譯時確定,無法在運行時更改。動態鏈接允許在程序運行時,通過庫搜索路徑(Linux 上為 LD_LIBRARY_PATH,Windows 上為 PATH)或系統庫,來選擇使用哪個版本。
08 組件關係總結
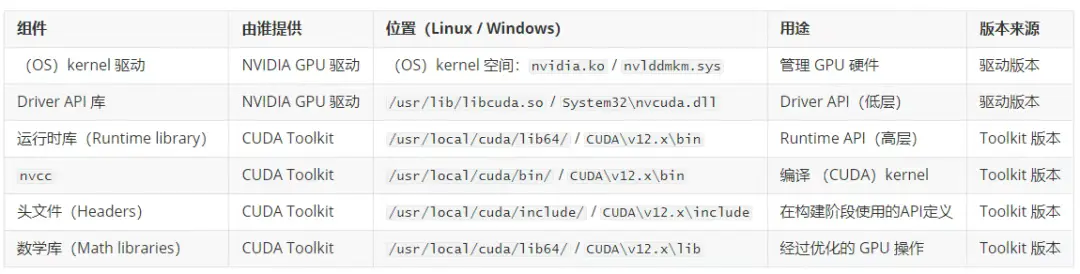
09 實用指南
9.1 面向應用程序開發者
- 明確最低驅動版本:在文檔中註明所需的 CUDA Driver API 版本。
- 捆綁或指定運行時版本:若靜態鏈接 libcudart,需確保與系統驅動兼容;若動態鏈接,應註明所需的 libcudart 版本。
- 為多種計算能力(compute capabilities)編譯:使用 -arch 和 -code 標誌來支持多種 GPU,並嵌入 PTX 以實現前向兼容。
- 在運行時(runtime)檢查版本:通過 cudaDriverGetVersion() 和 cudaRuntimeGetVersion() 驗證兼容性。
9.2 面向終端用户
- 安裝合適的 GPU 驅動:確保驅動支持的 CUDA Driver API 版本 ≥ 應用程序所需的 Runtime 版本。
- 運行時通常無需安裝完整 Toolkit:大多數應用程序不需要 nvcc 等開發工具,僅需 libcudart 和 GPU 驅動即可。
- 檢查兼容性:運行 nvidia-smi 以確認 GPU 驅動版本及其支持的 CUDA Driver API 版本。
9.3 面向 PyTorch 用户
- 編譯時 Toolkit 版本(torch.version.cuda):指 PyTorch 編譯時(build time)所鏈接的 CUDA Toolkit 版本,無需與系統中安裝的 Toolkit 一致。
- 運行時驅動程序版本要求:系統 GPU 驅動必須支持 CUDA Driver API 版本 ≥ PyTorch 的編譯 Toolkit 版本。
- 示例:
- 若 PyTorch 使用 CUDA Toolkit 12.1 編譯,則系統 GPU 驅動必須支持 CUDA Driver API ≥ 12.1。
- 若系統 GPU 驅動支持 CUDA Driver API 12.4,則可運行使用 CUDA Toolkit 12.1、12.2、12.3 或 12.4 編譯的 PyTorch。
注意:TensorFlow 採用相同的兼容性模型,請查閲其發佈説明以確認其編譯所用的 Toolkit 版本。
9.4 面向 Docker / 容器用户
- 僅運行時鏡像(-runtime):包含 libcudart 及運行庫,適用於運行預編譯的 CUDA 應用程序,不含 nvcc。
- 開發鏡像(-devel):包含完整的 CUDA Toolkit(nvcc、頭文件、庫文件),編譯 CUDA 代碼時必需。
- NVIDIA Container Toolkit:確保容器能訪問主機的 GPU 和 GPU 驅動。容器內可用的 CUDA Driver API 最高版本由主機上的 GPU 驅動版本決定。
10 結論
CUDA 的架構是一個分層系統,各組件在編譯時和運行時承擔不同職責。要準確理解它,需做到以下幾點:
1)術語辨析(Disambiguation) :
"CUDA" 可指計算架構、指令集(ISA)、語言擴展、Toolkit 或 Runtime。
"Driver" 可指 (OS)kernel 空間的驅動(如 nvidia.ko)或用户空間的 Driver API 庫(如 libcuda.so)。
"Kernel" 可指操作系統內核(OS kernel)或 GPU 函數(CUDA kernel)。
2)分層結構(Layering) :
libcudart(前端,Runtime API,面向應用)調用 libcuda(後端,Driver API,面向系統);
libcuda 進而調用(OS)kernel 驅動(nvidia.ko);
(OS)kernel 驅動最終管理 GPU 硬件。
3)版本規則(Versioning) :
Driver API 版本必須 ≥ Runtime API 版本。
GPU 要麼需有與其計算能力匹配的 SASS,要麼二進制文件中必須包含 PTX,以便驅動能 JIT 編譯為對應架構的 SASS。
4)編譯時 vs. 運行時(Build vs. execution) :
編譯時需要 CUDA Toolkit(含 nvcc);
運行時僅需 libcudart(可捆綁或動態鏈接)和系統 GPU 驅動。
版本不匹配會產生特定的故障模式:驅動程序版本不足、找不到(CUDA)kernel 映像或不支持 API 調用。通過這種系統化的理解,我們可以清楚為什麼 nvidia-smi、nvcc --version 和 torch.version.cuda 會報告不同的版本號,每個版本號的含義是什麼,以及如何診斷版本不兼容問題。
END
本期互動內容 🍻
❓除了本文提到的術語,你還遇到過哪些容易混淆的CUDA相關概念?(例如:stream、context、graph...)
本文經原作者授權,由 Baihai IDP 編譯。如需轉載譯文,請聯繫獲取授權。
原文鏈接:
https://jamesakl.com/posts/cuda-ontology/
