Qwen3-TTS 是由 Qwen 開發的一系列功能強大的語音生成,全面支持音色克隆、音色創造、超高質量擬人化語音生成,以及基於自然語言描述的語音控制,為開發者與用户提供最全面的語音生成功能。
依託創新的 Qwen3-TTS-Tokenizer-12Hz 多碼本語音編碼器,Qwen3-TTS 實現了對語音信號的高效壓縮與強表徵能力,不僅完整保留副語言信息和聲學環境特徵,還能通過輕量級的非 DiT 架構實現高速、高保真的語音還原。Qwen3-TTS 採用 Dual-Track 雙軌建模,達成了極致的雙向流式生成速度,首包音頻僅需等待一個字符。
Qwen3-TTS 多碼本全系列模型均已開源,包含1.7B和0.6B兩種尺寸,1.7B可以達到極致性能,具有強大的控制能力,0.6B均衡性能與效率。模型覆蓋 10 種主流語言(中文、英文、日語、韓語、德語、法語、俄語、葡萄牙語、西班牙語、意大利語)及多種方言音色,滿足全球化應用需求。
同時,模型具備強大的上下文理解能力,可根據指令和文本語義自適應調整語氣、節奏與情感表達,並對輸入文本噪聲的魯棒性有顯著提升。目前已經在Github上開源同時也可通過Qwen API體驗。
歡迎體驗
ModerScope:https://www.modelscope.cn/collections/Qwen/Qwen3-TTS
HuggingFace:https://huggingface.co/collections/Qwen/qwen3-tts
Github: https://github.com/QwenLM/Qwen3-TTS
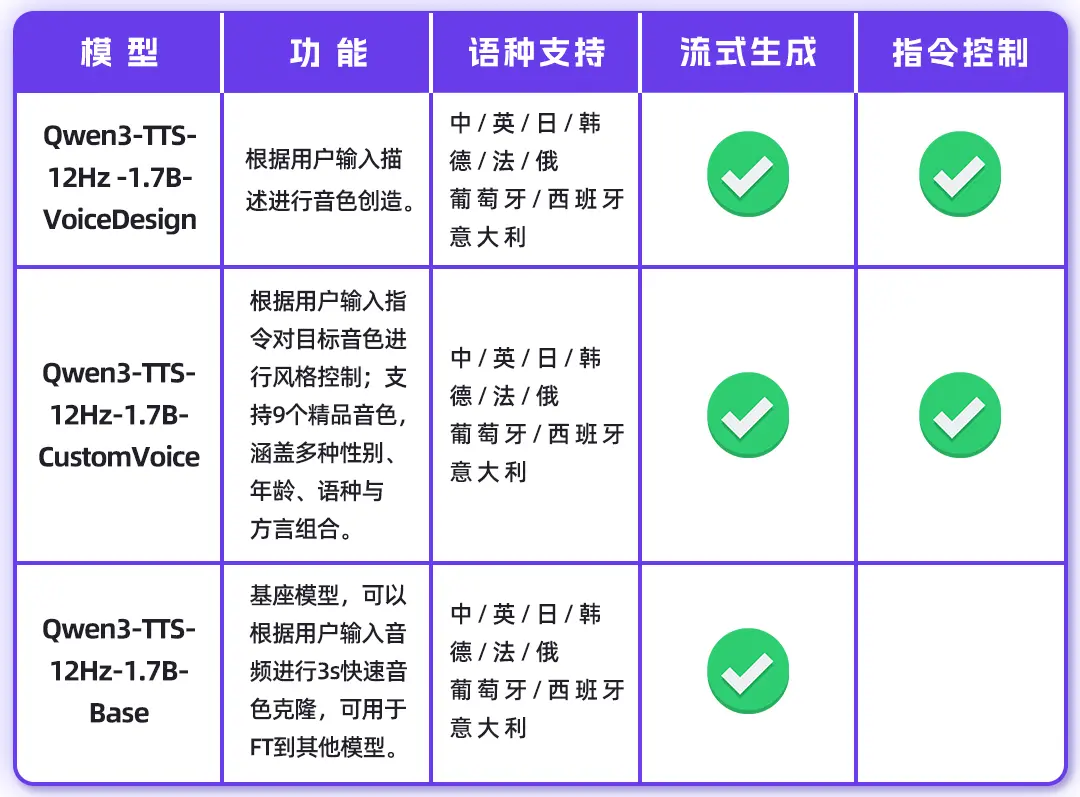
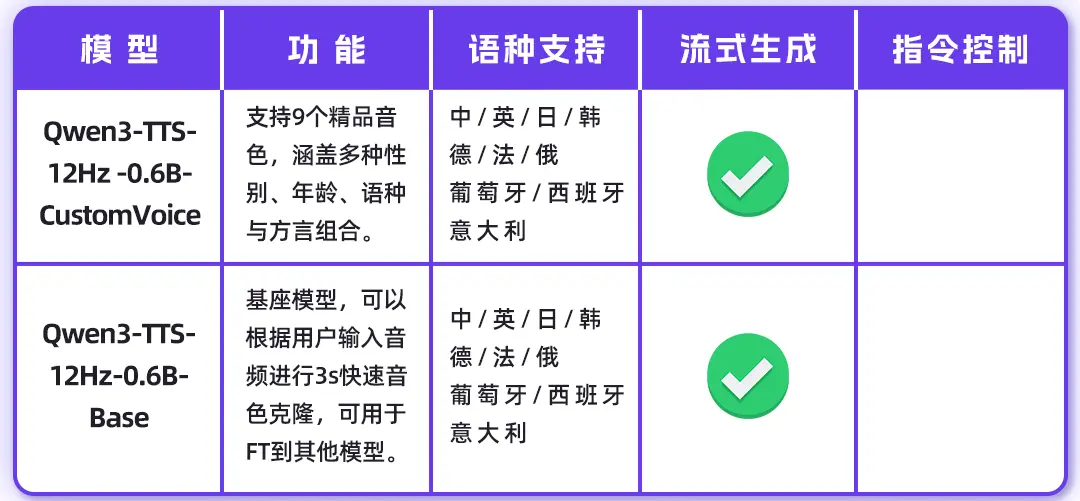
模型列表
1.7B模型
0.6B模型
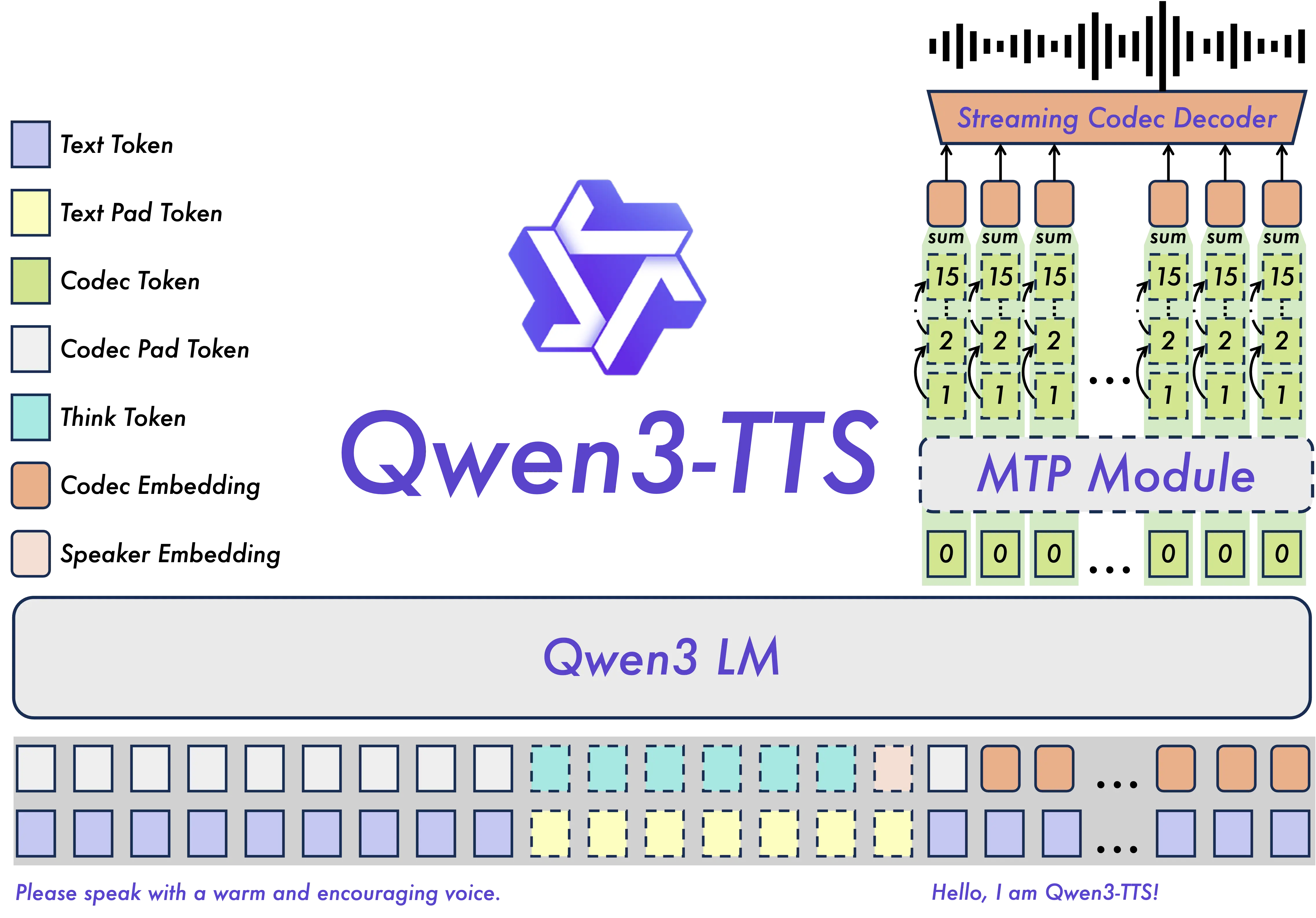
Qwen3-TTS特性
主要特點:
- 強大的語音表徵:基於自研 Qwen3-TTS-Tokenizer-12Hz,實現語音信號的高效聲學壓縮與高維語義建模,完整保留副語言信息及聲學環境特徵,並可通過輕量級的非 DiT 架構實現高效、高保真語音還原。
- 通用的端到端架構:採用離散多碼本 LM 架構,實現語音全信息端到端建模,徹底規避傳統 LM+DiT 方案的信息瓶頸與級聯誤差,顯著提升模型的通用性、生成效率與效果上限。
- 高極致的低延遲流式生成:基於創新的 Dual-Track 混合流式生成架構,單模型同時兼容流式與非流式生成,最快可在輸入單字後即刻輸出音頻首包,端到端合成延遲低至 97ms,滿足實時交互場景的嚴苛需求。
- 智能的文本理解與語音控制:支持自然語言指令驅動的語音生成,靈活調控音色、情感、韻律等多維聲學屬性;同時深度融合文本語義理解,自適應調節語氣、節奏、情感與韻律,實現“所想即所聽”的擬人化表達。
模型性能
我們對 Qwen3-TTS 在音色克隆、創造、控制等方面進行了全面評估,結果顯示其在多項指標上都達到了SOTA性能。具體來説:
- 音色創造任務上,Qwen3-TTS-VoiceDesign 在 InstructTTS-Eval 中指令遵循能力和生成表現力都整體超越 MiniMax-Voice-Design 閉源模型,並大幅領先其餘開源模型。
- 在音色控制任務上,Qwen3-TTS-Instruct 不僅具備單人多語言的泛化能力,平均詞錯率 2.34%;同時具備保持音色的風格控制能力,InstructTTS-Eval 取得了 75.4% 的分數;此外,也展現出卓越的長語音生成能力,一次性合成 10 分鐘語音的中英詞錯率為 2.36/2.81%。
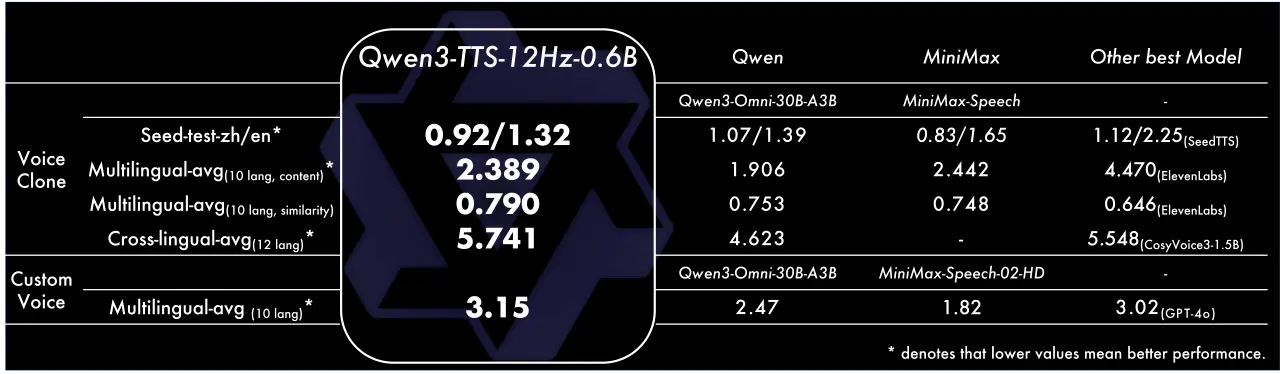
- 在音色克隆任務上,Qwen3-TTS-VoiceClone 在 Seed-tts-eval 上中英文克隆的語音穩定性表現上均超越MiniMax和SeedTTS;在 TTS multilingual test set 上 10 個語項上取得了 1.835% 的平均詞錯誤率和 0.789 的説話人相似度,超越 MiniMax 和 ElevenLabs;跨語種音色克隆也超越 CosyVoice3 位居 SOTA。

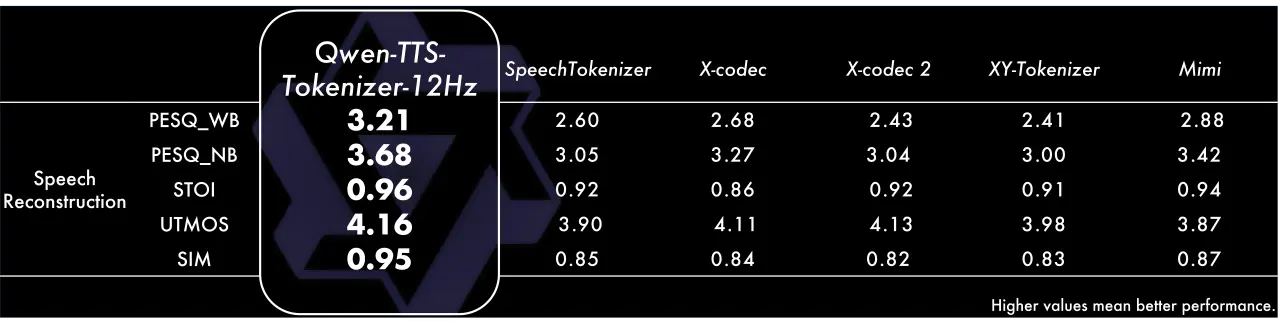
Tokenizer性能
我們對 Qwen-TTS-Tokenizer 進行了語音重構評估,在LibriSpeech test-clean set的結果顯示其在關鍵指標上都達到了的SOTA水平。具體來説,在感知語音質量評估(PESQ)中,Qwen-TTS-Tokenizer在寬帶和窄帶上分別取得了3.21和3.68的分數,大幅領先同類tokenizer。在短時客觀可懂度(STOI)以及UTMOS上,Qwen-TTS-Tokenizer取得了0.96和4.16的分數,展現出卓越的還原質量。在説話人相似度上,Qwen-TTS-Tokenizer取了0.95的分數,顯著超越對比模型,表明其近乎無損的説話人信息保留能力。