AReaL 是一個面向算法設計,以開發效率和靈活性為核心的強化學習框架,由螞蟻百靈大模型團隊開源。它通過極簡的 API 和可擴展的插件機制降低用户的學習曲線和使用心智負擔,讓開發者聚焦於算法本身而非系統細節,具備大規模擴展、無侵入 Agentic RL、故障感知與自恢復等能力。
該項目近日發佈新版本 v0.5.0,帶來了解耦式 Agentic RL,以及 Single Controller 架構兩個核心特性。
- 解耦式 Agentic RL
AReaL 通過 OpenAI API 代理,提供了一套解耦化的智能體訓練服務解決方案,便於環境提供者、算法開發者和系統開發者形成複雜工程中的零障礙流水線,極大提升了開發效率與系統可維護性。
AReaL Agentic RL 的架構設計建立在兩個核心原則之上:
1. Agent 完全獨立運行(Agent Autonomy)
在 AReaL 框架中,Agent 本身不依賴任何 RL 框架的組件,也不感知自身正在被用於訓練。它只是一個標準的、基於大語言模型(LLM)的決策系統,按照既定的編排邏輯接收輸入、調用工具、生成動作並輸出結果。這種設計確保了 Agent 的純淨性與可移植性——同一個 Agent 實現既可以用於在線推理,也可以無縫接入離線訓練,真正做到"一套代碼,兩處複用"。
2. RL 訓練作為外部觀察者(RL as Observer)
AReaL 不主動干預 Agent 的執行流程,而是通過"代理請求"的方式,監聽並記錄 Agent 與環境交互的完整軌跡(Trajectory)。這些軌跡包括:用户輸入、Agent 的思維鏈(Thought)、調用的動作(Action)、環境反饋(Observation)以及最終的獎勵信號(Reward)。通過這種方式,AReaL 將複雜的 Agent 執行過程轉化為標準的 RL 訓練數據,從而可以使用任意成熟的 RL 算法進行策略優化。
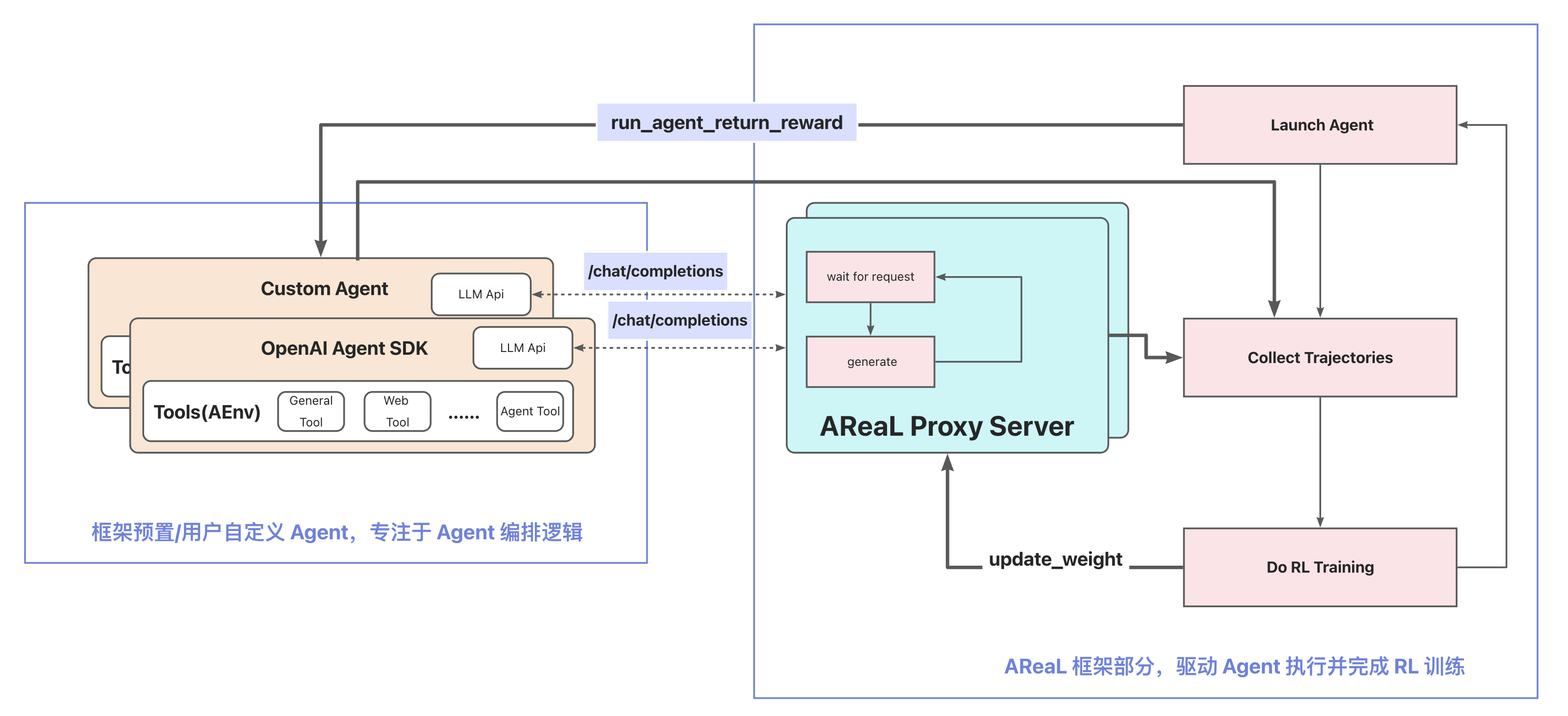
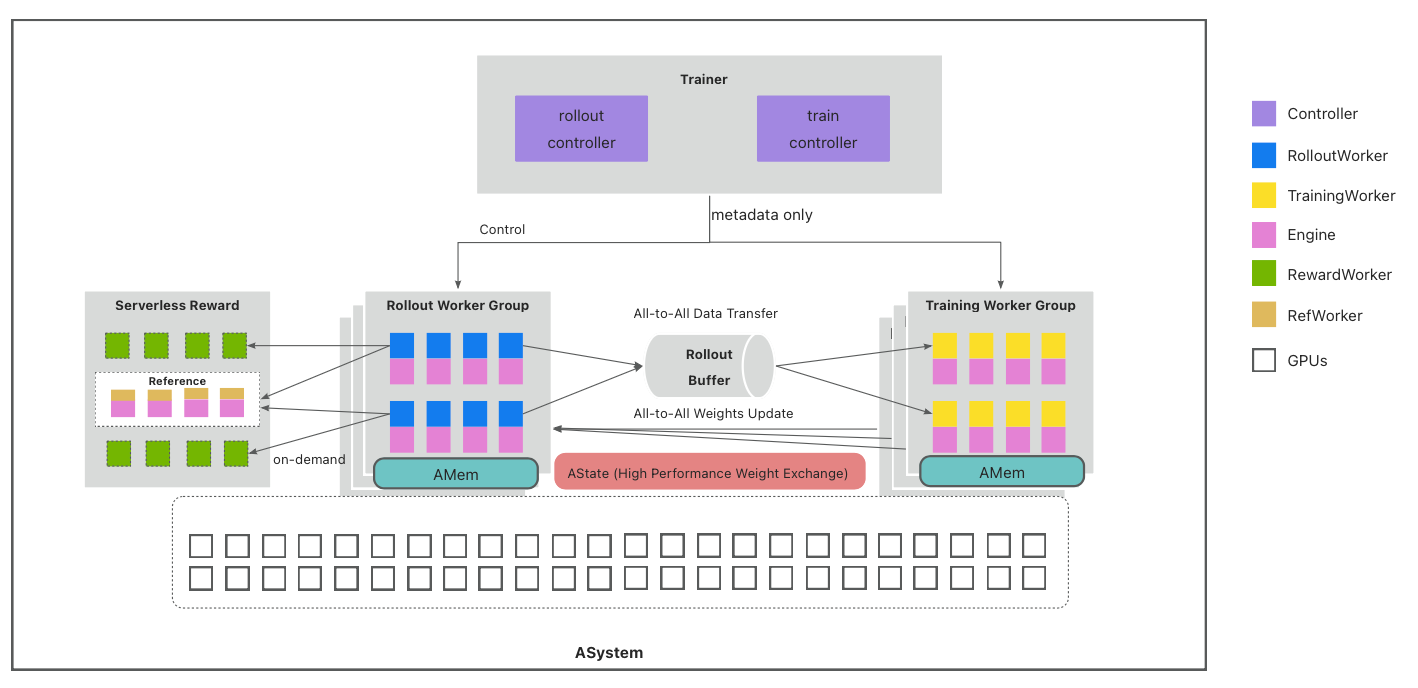
- Single Controller 架構
消除了 SPMD (Single Program, Multiple Data) 模式的長尾和數據不均勻問題,這種分層設計既能提升推理擴展性、增強系統層面精細化控制,又能保留算法編排的靈活易用性,降低算法開發者代碼遷移的成本。
Single Controller 架構如下:
下載地址:https://github.com/inclusionAI/AReaL/releases/tag/v0.5.0
