本文作者:OceanBase AI Application Developer & Data Scientist 格奧
編者按
OceanBase DataPilot 在被譽為“數據智能時代新基準”的 HuggingFace DABstep 基準測試 Hard 級別中獲得全球最高分,並已連續 1 個月大幅領先第二名,位居全球第一。該⼯具旨在評估最前衞的語⾔模型和 AI 代理在多步驟推理中的能⼒,特別是在數據分析領域的表現。
引言:當“更聰明的 Prompt”不再奏效
當今世界數據無處不在,而數據科學一直被視為人類智能的重要體現。
在大型語言模型(LLM)的應用探索中,數據分析一直被視為重要方向。然而,當開發者試圖將 Text-to-SQL 或簡單的 Python Agent 投入真實的金融、風控或運維場景時,往往會撞上一堵無形的牆:模型似乎“聽懂”了,但分析出來的數據總是不對;腳本在測試集跑通了,上線面對髒數據卻頻繁崩潰;複雜的業務口徑在不同輪次的對話中發生漂移。
所以,一家來自荷蘭的支付解決方案提供商 Adyen 與享譽全球的AI 社區 Hugging Face 才會一起聯手,想搞清楚 AI 到底能不能勝任這份工作。 2025年2月,他們聯合發佈了一個 DABstep(Data Agent Benchmark for Multi-step Reasoning)基準測試,將這一矛盾擺在了枱面上,即便是 o3-mini、DeepSeek-R1 這樣的頂尖推理模型,在 Hard 模式下的準確率也僅在 13%-16% 徘徊。
它的難主要體現在三個極度真實的方面:
-
首先,DABstep 的問題是高度真實的。在測試裏包含了 450+ 真實業務任務,全部來自於Adyen 內部真實的金融業務場景。比如欺詐風險分析,支付費率計算。這些都不是研究人員憑空想象出來的簡單問題,而是反映了分析師每天面臨的挑戰;
-
第二是數據環境的真實性。DABstep包含結構化和非結構化數據,分別用於衡量領域知識和技術技能。其中,結構化數據包括CSV和JSON文件,代表真實世界的數據,如交易記錄和業務元數據;非結構化數據包括文檔、手冊和詳細指南等。這些任務需要高級數據分析技能,以處理結構化數據和理解多個數據集及文檔中的非結構化數據。
-
最後是解決路徑的真實性。DABstep 的問題無法通過單一代碼片段解決,而是需要多步驟的迭代推理。AI 必須像一個真正的人類分析師一樣,先做探索性分析,然後分步驟迭代的去解決問題。例如,代理至少需要知道數據集中有哪些列才能回答問題。
DABstep 基準測試分為 2 個難度級別:
簡單級別 :作為熱身任務,幫助驗證設置、集成和研究⽅向。通常只需要⼀個結構化數 據集和少量背景知識。⼈類在經過3⼩時以上的⼯作後平均能達到62%的基線準確率,⽽ Llama 70B零樣本提示可以超過90%的準確率。
困難級別 :需要更復雜的⽅法,涉及多個結構化數據集和領域特定知識。這些問題通常⽆法通過單⼀代碼⽣成解決,⽽是需要多步驟推理。
DABstep 在 HuggingFace 官網提供了一個實時排行榜,全球參與者都可以即時查看全球排名。OceanBase 團隊推出的數據分析 Agent——DataPilot 在 Hard 級別的全球榜單中獲得最高分,並已連續 1 個月大幅領先第二名,穩居全球第一。
DataPilot 是 OceanBase 推出的智能問數與洞察平台:支持快速搭建分析域、自動化語義層配置與指標管理;提供自然語言驅動的問答式分析,輸出可解釋的 SQL/推理過程與統計結論;內置細粒度數據權限與審計能力,確保數據安全合規_。_
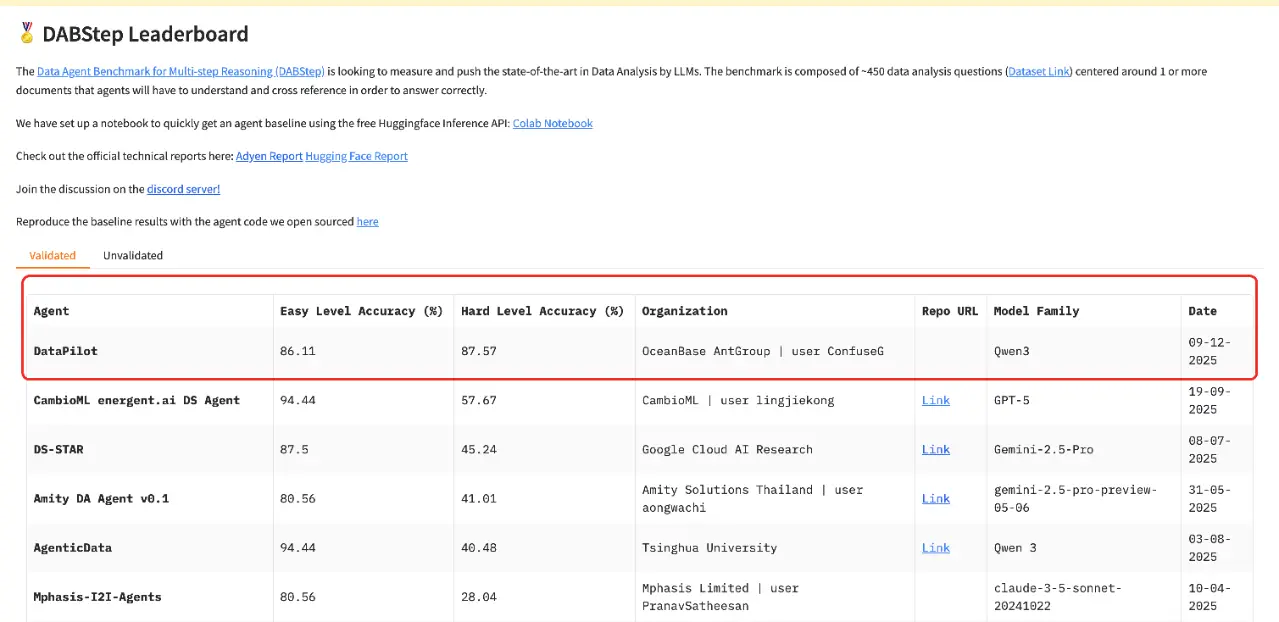
*DABstep 全球實時榜單:__https://huggingface.co/spaces/adyen/DABstep
我們可以看到,DABstep 榜單上有很多參與者,那為什麼 OceanBase DataPilot 能拿到最高分?答案不在於 OceanBase 用了更強的模型,而在於建立了一套能夠持續積累和複用的知識體系。
OceanBase DataPilot 的做法是:通過測試集和專業數據分析師構建的 success story 樣本,以及必要的人工糾偏和引導,在這套框架下沉澱了能夠比較穩定解答問題的數據理解、必要業務規則、公式指標、代碼規範。基於這些構建的上下文,智能體能夠在測試集上穩定回答推理問題,並且充分發揮 LLM 的能力,觸類旁通解決相似問題,實現一定的外推泛化性能。
1、 數據分析的“真實之痛”
數據分析從來不是簡單的“寫代碼”或“畫圖表”。在 DABstep 揭示的真實場景中,分析師通常面臨着三重典型問題:
第一重約束是口徑歧義。
文檔可能會説“國內交易費率更低”,但數據表裏有 issuer_country(髮卡國)、acquirer_country(收單國)、ip_country(IP歸屬地)等多個字段。到底哪兩個字段匹配才算“國內”?模型往往靠直覺“猜”,導致在部分樣本上正確,部分樣本上謬誤。這種歧義在真實業務中比比皆是,而模型缺乏明確的業務規則,只能在黑暗中摸索。
第二重約束是數據髒亂。
真實數據中,空值可能是 null、None,也可能是空數組 []。普通的 Python 腳本在面對這些“非標”數據時,往往不是算錯,而是直接拋出異常崩潰。
第三重約束是性能與資源受限。
即使邏輯正確,一個 O(R * T)(R=規則數量,T=交易數量)的雙重循環在面對百萬級交易流水時也可能直接超時。在 DABstep 或真實業務中,“跑得太慢”等同於“不可用”。
2、OceanBase 是如何設計 Data Agent 的?
(1)核心理念:從“臨時對話”到“版本化資產”
想象一下,你在和 AI 聊天時,它每次都要重新理解"國內交易是什麼意思"、"空值該怎麼處理"。這就像每天上班都要重新培訓新員工,效率極低。普通的 RAG(檢索增強生成)系統往往將上下文視為臨時的、用完即棄的對話內容。OceanBase DataPilot 的思路是_把知識變成可以長期保存、反覆使用的"資產"。_
具體來説,系統做了三件事。
第一,把上下文當成資產而不是臨時對話內容,將 AI 需要的知識拆成三層,分別管理、分別迭代。
第二,把每次做題變成一次小型訓練,用"樣例題解過程 + 標準答案"做自動迴歸,持續修正並沉澱經驗。
第三,把穩定交付當成產品目標,不僅要算對,還要能跑完、跑得快、不會因為髒數據頻繁崩潰。
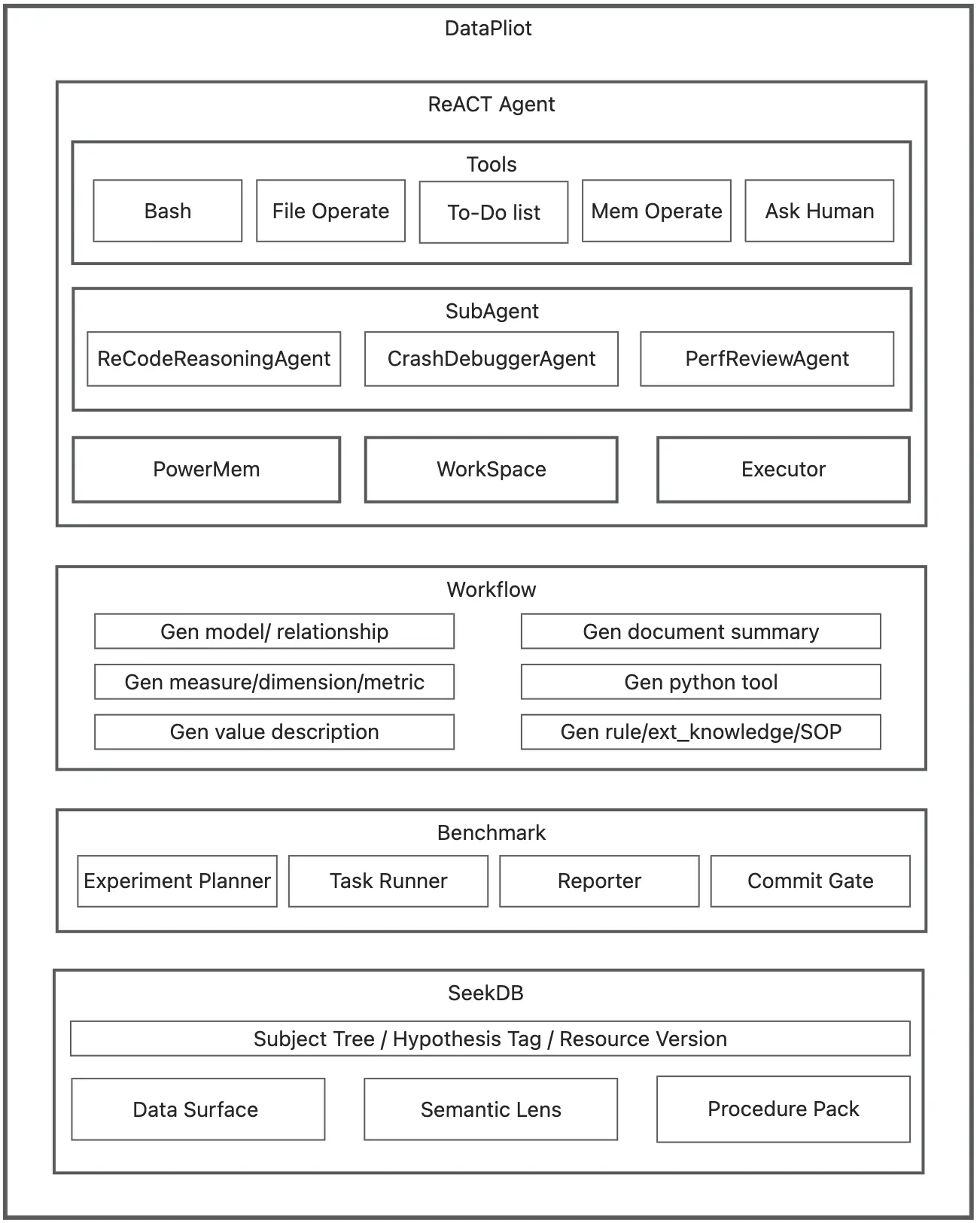
這張架構圖把 DataPilot 的“資產化閉環”落到可執行模塊上:上層 ReACT Agent 作為構建態與運行態的統一入口,用工具與沙箱執行驅動數據洞察,必要時調用子智能體生成多版本假設實現。
中層 Workflow 把對話結論、口徑、工具與 SOP 結構化生成資源,並統一打上 Subject Tree / Hypothesis Tag / Resource Version。下層 seekdb 負責混合檢索與版本化管理,既能按標籤精確召回,也能按語義 query 組合上下文。Benchmark 則把不同 Hypothesis Tag 當作可對照實驗分組:同一任務流程下僅切換檢索標籤,批量評測並輸出分支分數,從而選擇最優分支上下文沉澱為主幹默認版本。
整套系統分為兩部分。資產平面存放可檢索、可版本化的知識與能力,相當於長期記憶;運行平面把這些資產組裝成一次可執行的分析作業,負責當次執行。打個比方,資產平面就像一個知識庫和工具箱,裏面裝着各種標準操作手冊、代碼模板、歷史經驗;運行平面就像一個裝配車間,根據當前任務從工具箱裏挑選合適的工具組裝起來幹活。
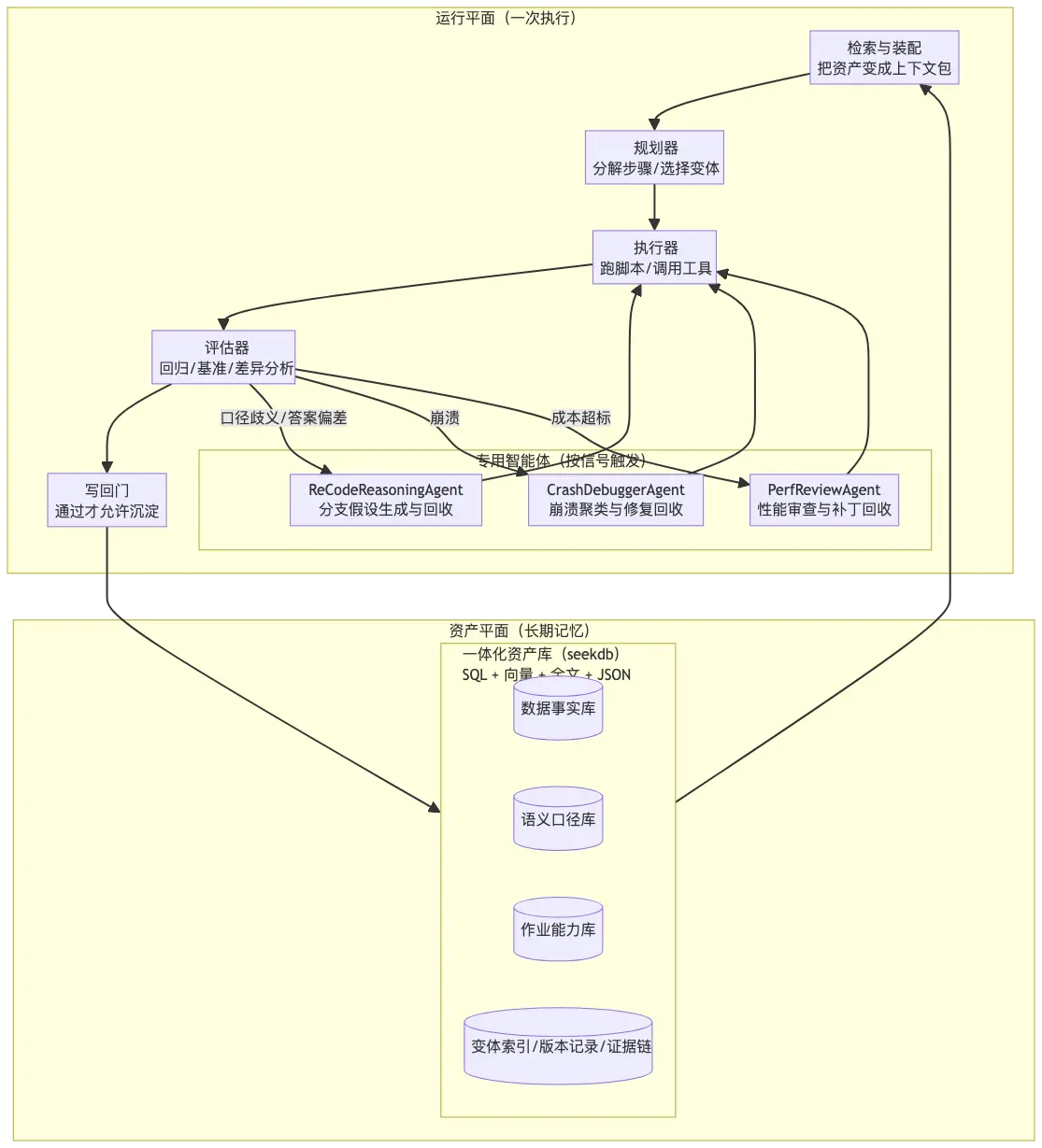
在資產平面“知識”又被分成三層。
把“知識”分層的原因很簡單:不同類型的知識,生命週期、複用方式、驗證方式完全不同。混在一起會很難維護。
第一層是數據事實層(Data Surface),回答最基礎的問題:數據到底長什麼樣?字段是什麼類型?有多少空值?可能的取值範圍是什麼?這一層的產物是字段字典、數據畫像(缺失率、值域)、易錯點提醒。
比如,明確告訴 Agent:"這個叫 Country 的字段,雖然名字像國家,但實際存的全是 IP 地址。"這樣的信息看似簡單,但對避免誤判至關重要。
第二層是語義口徑層(Semantic Lens),回答業務定義問題:業務到底怎麼算?什麼叫"月交易量"?是按金額還是筆數?是自然月還是滾動窗口?"欺詐率"怎麼算?按金額還是按筆數?邊界值如何判定?輸出需要保留幾位小數?空列表用什麼語義表達?這一層的產物是術語卡、指標卡、粒度約束。比如,固化一條規則:"國內交易 = 髮卡國和收單國相同,不看 IP 國家。"這樣的規則一旦確定,就不再允許歧義和漂移。
第三層是可執行作業層(Procedure Pack),負責怎麼穩定做出來。
這一層是最硬核的部分,包含能處理髒數據、能在資源限制下跑完、能一鍵迴歸的代碼。這裏不僅要算對,還要能處理髒數據(不崩潰)、能在資源限制下跑完(性能可控)、能一鍵迴歸(證明沒有退化)。
產物包括可複用工具、端到端作業腳本、驗證器/迴歸集、多個實現變體。比如,一個通用工具:"安全的成員判斷函數safe_in,處理空值、空數組、None 等各種邊界情況。"這是最硬核的資產,包含了處理髒數據和性能優化的代碼結晶。
從工程實現角度看,分層讓檢索與裝配更直接:_資產可以用結構化元數據進行治理與過濾,用全文做關鍵詞召回,用向量做語義召回;必要時再對候選做輕量重排。_運行態通常可以先用硬條件縮小範圍,再用混合召回拉出候選資產組合,最後按適用條件與成本畫像完成選擇與裝配。
(2)GRPO 理念的上下文構建:Train-Free 的資產迭代
OceanBase DataPilot 借鑑了 GRPO(Group Relative Policy Optimization) 的思想,但將其應用於"上下文資產"而非"模型參數"的優化。
這是一種 Train-Free 的迭代方式,每一輪同時產出多個候選改動,用迴歸分數做相對比較,再選擇最優候選寫回。
訓練信號來自兩個方向。Success Story(樣例題解過程)給你"方向線索",告訴你哪些字段關鍵、哪些邊界會翻轉答案、哪些
解釋方式可沉澱為口徑條目。Golden Answer(標準答案)給你"裁判尺度",衡量你的改動有沒有讓一批樣本更對齊,並且這個
對齊是可以被機器驗證的。
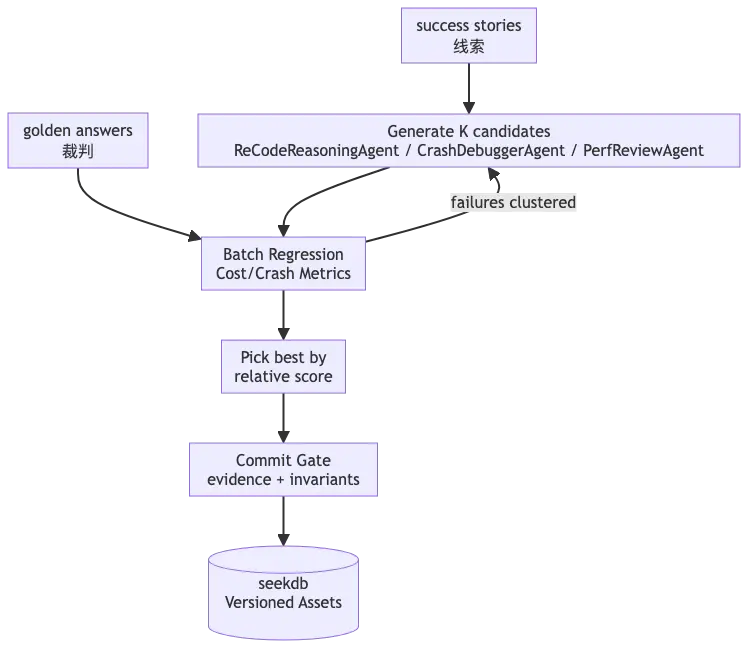
迭代閉環可以概括為“分支生成—標籤化對照評測—主幹沉澱”。
在生成階段,ReACT Agent 在推理或人機交互中識別歧義點/未知點,將其顯式化為佔位符分叉,並由 ReCodeReasoningAgent(或其他子智能體)產出多套候選實現與上下文變體;這些候選以 Subject Tree / Hypothesis Tag / Resource Version 的形式被結構化寫入 SeekDB,形成可檢索、可組合的分支版本。
隨後進入對照評測階段,Benchmark 接收一組待檢驗的 Hypothesis Tag 列表,對每個標籤執行完全一致的任務流程與迴歸樣本,只在上下文召回時透傳對應 Tag 做混合檢索,從而得到“同題同流程、僅上下文假設不同”的可比實驗結果,併為每個分支輸出可解釋的分數與證據報告。
最後進入沉澱階段,系統依據評測成績與多目標權衡(正確性/穩健性/成本)選取最優假設分支,將其對應的資源集合提升為默認主幹,其餘分支保留為可追溯但不生效的候選,以便後續複測與回滾。
(3)三個典型進化閉環案例
整套方法可分為三個典型閉環,對應前面三重典型問題的解決,分別代表了口徑歧義、腳本崩潰和性能瓶頸。
邏輯閉環:解決"口徑歧義"—— 讓 AI 知道"國內交易"到底怎麼算
例如一個數據表裏有三個"國家"字段:髮卡國、收單國、IP 國家,AI 每次都在猜"國內"到底指哪兩個字段匹配。解決過程是這樣的:系統生成三個候選定義(H1/H2/H3),分別對應不同的字段組合,然後用標準答案批量測試,看哪個定義的準確率最高。把最優定義寫入"語義口徑層"作為強制規則,再把判定邏輯封裝成工具函數,所有腳本必須調用。結果是以後遇到"國內交易",AI 不再猜測,而是直接查詢已確定的口徑定義。這個案例的核心在於把歧義消除,將隱性的業務規則顯性化、資產化。
健壯性閉環:解決"腳本崩潰"—— 讓代碼能處理各種髒數據
在真實業務的數據中,空值可能是 null、None、空數組[],普通代碼遇到就崩潰。解決過程包括四個步驟:收集所有崩潰日誌並按錯誤類型分類,提取最小復現樣本寫成迴歸測試用例,開發通用的安全判斷函數 safe_in統一處理各種空值情況,把這個函數寫入工具庫並強制所有腳本使用。以後寫代碼時,不用每次都想"空值怎麼辦",直接調用標準工具即可。這個例子把健壯性經驗沉澱為可複用的工具,避免同類錯誤反覆出現。
效率閉環:解決"性能瓶頸"—— 讓慢代碼跑得快
假設有一個"規則匹配交易"的任務,因為嵌套循環(規則數 × 交易數),在百萬級數據上超時。解決方法是先識別熱點,發現主要耗時在雙重循環;然後生成優化方案,先把交易按特徵聚合減少匹配次數;接着驗證優化,用標準答案確認結果一致,用性能測試確認確實更快;最後把優化版本作為新變體保存,標註適用條件(大數據量時使用)。當以後遇到同類任務,系統會優先選擇高性能版本,自動規避性能陷阱。該例子可以把性能優化也變成可複用的資產,而不是每次都重新優化。
以上三個案例揭示了 OceanBase 方案的本質:不是讓 LLM 每次都從零開始推理,而是通過資產化的方式,把"數據長什麼樣"(Data Surface)、"業務怎麼算"(Semantic Lens)、"代碼怎麼寫"(Procedure Pack)這三層知識固化下來。當遇到新問題時,系統先從資產庫中檢索相關知識,然後基於這些知識構建上下文,讓 LLM 在一個"有記憶"的環境中推理。
更重要的是,這套體系具備泛化能力。雖然初始的資產是通過測試集和 success story 構建的,但一旦建立起來,系統就能觸類旁通。
比如,學會了處理"國內交易"的口徑歧義後,遇到類似的"跨境交易"、"本地貨幣"等概念時,系統能夠複用同樣的消歧方法。學會了 safe_in函數後,遇到其他類型的邊界情況(如除零、類型轉換),也能用類似的思路去抽象和沉澱。學會了特徵聚合優化後,遇到其他嵌套循環的性能瓶頸,也能快速識別並應用類似的優化策略。
這就是為什麼 OceanBase DataPilot 能在 DABstep 上拿到最高分的原因。不是因為模型更聰明,而是因為建立了一套讓模型"變聰明"的機制。這套機制通過三層資產管理,將隱性的推理能力顯性化;通過 success story 和 golden answer,將一次性的成功經驗持久化;通過混合搜索和事務寫回,將碎片化的知識系統化。最終,系統不再是"做對一次題",而是"學會一類題"。
3、 讓“存 + 找 + 寫回”構建順滑的閉環
值得注意的是,這套方法論要成立,有一個常被低估的前提:"長期資產"必須既能被穩定治理,又能被高質量檢索,還能被安全寫回。如果這些能力分散在多個組件裏(例如元數據一套、文檔一套、向量索引一套),系統很容易在工程上變得很脆。改動寫回時可能出現"部分成功"的情況,比如索引更新了但內容沒更新,或者內容更新了但索引沒更新。檢索裝配需要在應用層拼接多路召回與重排,結果不可控也難以迴歸。證據鏈散落在日誌和文件裏,難以追溯、難以長期複用。
為了讓上面的閉環在工程上足夠順滑,資產庫需要把“治理、檢索、寫回”三類能力穩定地提供出來。這就引出了一個關鍵問題:DABstep 這樣的負載,本質上在考驗數據庫的什麼能力?
OceanBase 為什麼天然適合 AI Agent 負載
(1)多模一體
傳統的數據架構往往是"拼接"的,用 MySQL 處理交易,用 ES 存文檔,用 Milvus 存向量,中間再掛一個 Redis 做緩存。這種架構在 AI Agent 場景下存在致命問題。一方面是割裂的上下文,Agent 需要頻繁查詢事實(Schema)、查閲口徑(文檔)、檢索歷史代碼(向量),跨系統的每一次跳轉都意味着延遲、網絡抖動和潛在的一致性錯誤。另一方面是難以回溯的狀態,當 Agent 犯錯時,你很難復現是因為向量庫索引沒更新,還是數據庫裏的元數據變了。
OceanBase seekdb 採用一體化架構(TP + AP + AI),在一個引擎內同時承載結構化元數據、全文文檔、向量語義索引與 JSON 證據包。這意味着"上下文構建"發生在一個統一的數據平面內,數據的一致性和交互的原子性得到了物理級別的保障。
(2)混合搜索
在 seekdb 的方案中,混合搜索不再是錦上添花的功能,而是 Agent 工程的基石。DABstep 的任務往往隱含着複雜的查詢需求,比如"在距離五百米以內(空間查詢),人均消費25元以下(關係過濾),評價4.5分以上且'不用排隊'(向量語義)的咖啡廳"這樣的組合條件。對於 Agent 而言,構建一次精準的上下文就是一次混合搜索的過程。找事實時利用關係數據庫能力,快速獲取表結構、字段統計信息;找口徑時利用全文檢索關鍵字;找經驗時利用向量檢索,召回歷史上處理過類似的代碼片段。
seekdb 將這些能力融合在同一套 SQL 引擎中。用户(或 Agent)只需一條 SQL 即可完成"語義 + 關鍵詞 + 標量"的混合篩選,無需在應用層進行復雜的歸併排序。這種"Data In, Data Out"的能力,讓 Agent 能夠以毫秒級速度,在一次執行中同時完成"查數據 + 查語義 + 查能力 + 跑作業",從而保證了系統"算對、跑完、跑穩"。
(3)事務寫回
在 Agent 的迭代過程中,每次"學到的經驗"都需要寫回到資產庫。但這個寫回過程涉及多個維度:更新註冊表(標記哪些口徑、工具被更新)、內容落庫(新的口徑定義、代碼片段)、證據鏈記錄(迴歸測試報告、性能基準)。如果這三個操作不在同一個事務裏,就可能出現"部分成功"的髒狀態,比如註冊表説"口徑已更新",但實際內容還是老的。
seekdb 的事務能力確保了這一點,把涉及的"註冊表更新 + 內容落庫 + 證據鏈記錄"作為一次原子操作提交。要麼全部成功並可追溯,要麼全部回滾不污染長期記憶。從工程角度看,這意味着寫回時不會出現"索引更新了但內容沒更新"的不一致狀態,回滾時能完整恢復到上一個穩定版本,證據鏈(如迴歸測試結果)與資產內容強綁定,可追溯、可審計。這是保證資產質量的關鍵機制。
(4)可嵌入也可服務
seekdb 還支持兩種部署模式,滿足不同階段的需求。在構建態(訓練/迭代階段),seekdb 可以作為輕量級嵌入式數據庫直接在開發環境中運行,快速響應資產的增刪改查,加速迭代週期。在運行態(生產環境),seekdb 可以作為獨立的數據服務部署,承載高併發的查詢請求,支持多個 Agent 實例併發訪問資產庫。這種靈活性讓團隊可以在"快速迭代"和"穩定服務"之間自由切換,無需重新設計架構。
4、從“榜單”到可落地的“技術路徑”
在 AI Agent 走向深水區的今天,Hugging Face 發佈的 DABstep 榜單揭示了一個殘酷的現實:即便擁有最強推理能力的 LLM,在面對真實複雜的業務數據分析時,準確率也往往不盡如人意。然而,OceanBase 憑藉"數據底座 + Agent 工程化"的方法論成功登頂。OceanBase DataPilot 在 DABstep Hard 難度中拿到最高分,其意義遠超一個榜單的排名。它證明了真正能支撐 AI 走向生產的,不是更聰明的提示詞,而是通過數據底座的一體化能力解決上下文碎片化難題,將 Agent 的推理過程轉化為可持久化、可迴歸、可迭代資產的工程體系。
該體系的關鍵在於三個技術決策。第一是用數據庫而非文件系統管理資產,利用事務、索引、查詢優化器等成熟能力,避免重複造輪子。第二是用迴歸測試而非人工評估驅動迭代,通過自動化的 pass/fail 判定和相對比較(A/B testing),減少主觀性和人工成本。第三是用混合搜索而非單一檢索方式構建上下文,結合關係過濾(精確匹配)、全文召回(關鍵詞)、向量召回(語義),在召回率和準確率之間找到工程平衡點。
在這個體系中,混合搜索所體現的價值遠不止是加速檢索,更是提升推理質量的基礎設施。在數據分析場景中,Agent 需要從三個維度構建上下文:事實維度(schema、statistics、data profile)通過關係查詢獲取,口徑維度(business rules、metric definitions)通過全文檢索定位,經驗維度(code snippets、procedures、best practices)通過向量檢索召回。這三類信息的粒度、分佈、召回策略完全不同,通過混合搜索可以高效組裝。更重要的是,混合搜索的結果是確定性的,給定相同的查詢和資產版本,返回的上下文是可復現的,這是實現迴歸測試和版本控制的前提。
未來,OceanBase 會將文中所述的完整 Data Agent 能力集成進 DataPilot 新版本中,包括資產管理(Data Surface、Semantic Lens、Procedure Pack)、混合搜索引擎(關係 + 全文 + 向量)、自動化迴歸系統(regression runner + commit gate),實現更加堅實可靠的智能問數產品,敬請期待!
歡迎訪問 OceanBase 官網獲取更多信息:https://www.oceanbase.com/
