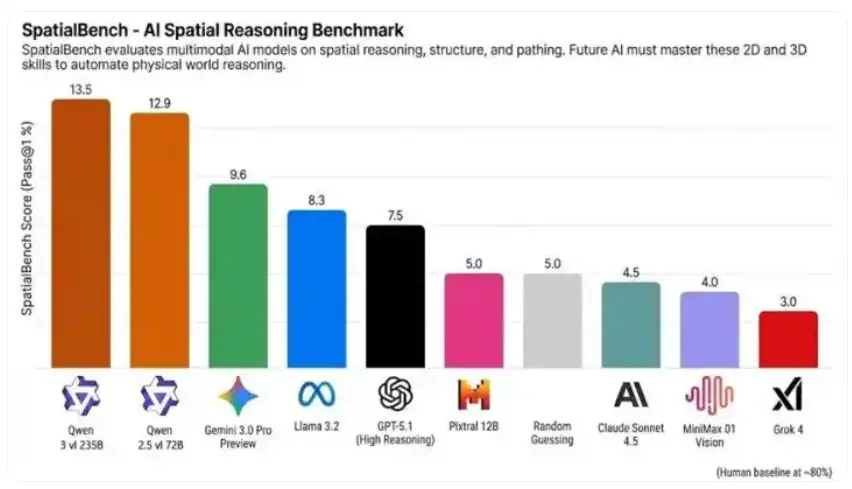
空間推理基準測試SpatialBench更新了最新一期榜單,阿里千問的視覺理解模型Qwen3-VL、Qwen2.5-VL位列頭兩名,超越Gemini 3、GPT-5.1、Claude Sonnet4.5等國際頂尖模型。
據瞭解,SpatialBench是一項近年來興起的第三方空間推理基準測試榜單,主要聚焦多模態模型在空間、結構、路徑等方面的綜合推理能力,被AI社區視為是衡量“具身智能”進展的新興測試標準之一。SpatialBench不僅測試模型已知的知識,還測試模型在二維和三維空間中“感知”和操控抽象概念的能力,這對具身智能的落地尤為關鍵。
SpatialBench榜單顯示,Qwen3-VL-235B和Qwen2.5-VL-72B分別斬獲13.5分和12.9分,領先於Gemini 3.0 Pro Preview(9.6) 、GPT-5.1(7.5)、Claude Sonnet 4.5等海外頂尖模型。然而,AI大模型的整體表現距離人類仍有差距,人類基準線80分左右,可專業處理電路分析、CAD 工程和分子生物學等複雜空間推理任務,目前大模型還無法完全自動化完成此類工作。
Qwen2.5-VL於2024年開源,Qwen3-VL是阿里在2025年開源的新一代視覺理解模型。Qwen3-VL在視覺感知和多模態推理方面實現重大突破,在32項核心能力測評中超過Gemini2.5-Pro和GPT-5,不但可以調用摳圖、搜索等工具完成“帶圖推理”,也可以憑藉一張設計草圖或一段小遊戲視頻直接“視覺編程”。同時,Qwen3-VL專門增強了3D檢測能力,可以更好地感知空間,基於Qwen3-VL,機器人更好地判斷物體方位、視角變化和遮擋關係,實現遠處蘋果的精準抓取。
目前,Qwen3-VL已開源不同版本,包括2B、4B、8B、32B等密集模型以及30B-A3B、235B-A22B等MoE模型,每個模型都有指令版和推理版兩款,是當下最受企業和開發者歡迎的開源視覺理解模型。同時,Qwen3-VL模型也已上線千問APP,用户可免費體驗。
