AI 搜索公司 Jina AI 發佈了Jina-VLM,這是一個 24 億參數的視覺語言模型,在開放的 2B 規模 VLM 中實現了最先進的多語言視覺問答。
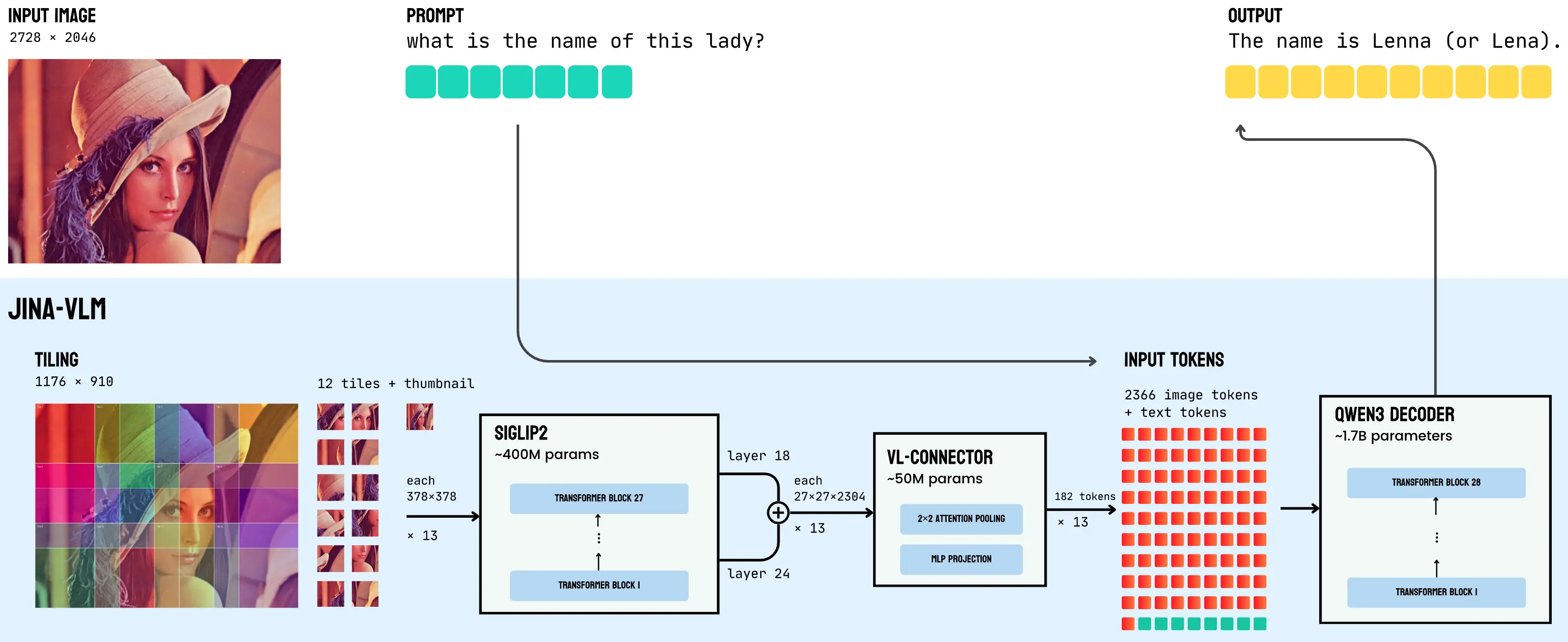
通過將 SigLIP2 視覺編碼器與 Qwen3 語言骨幹通過注意力池連接器相結合,Jina-VLM 在29 種語言中表現出色,同時保持了足夠的效率。Jina-VLM 架構圖如下,展示了從 SigLIP2 視覺編碼器 → VL-Connector → Qwen3 語言基座的數據流。
Jina-VLM 對硬件需求較低,可在普通消費級顯卡或 Macbook上流暢運行。
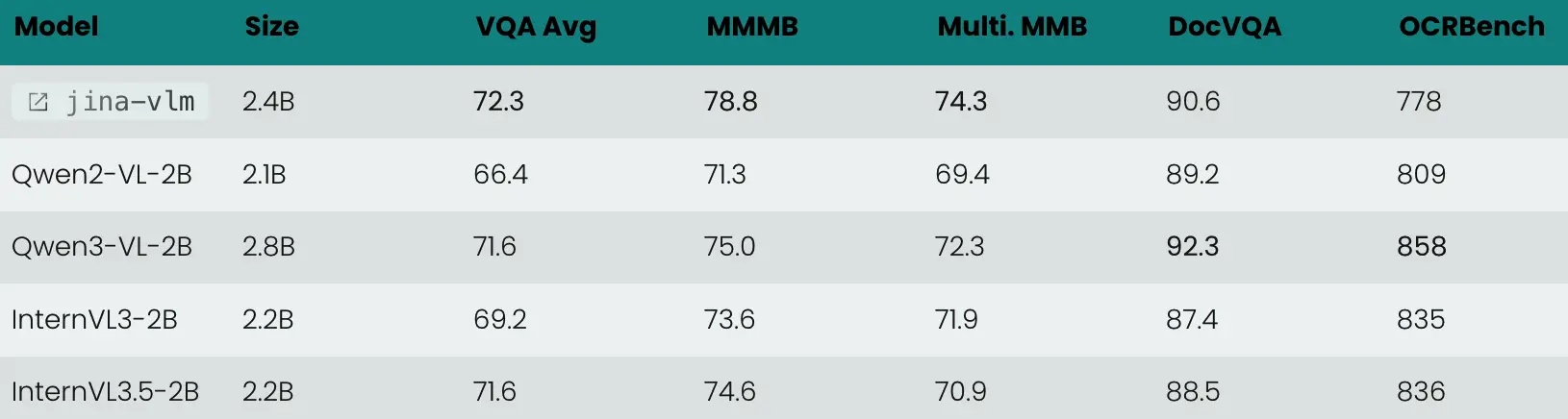
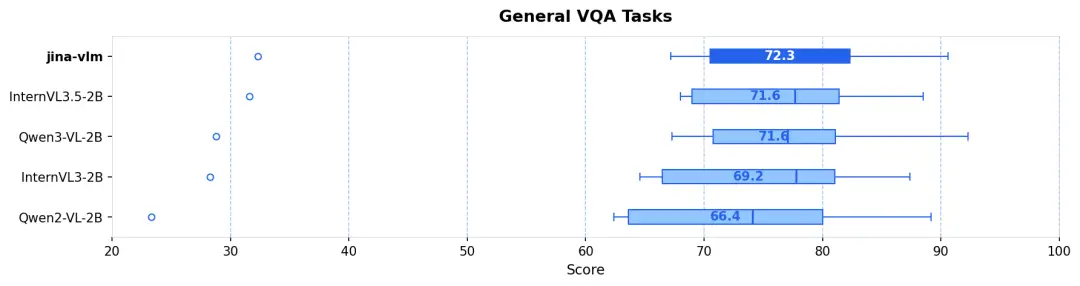
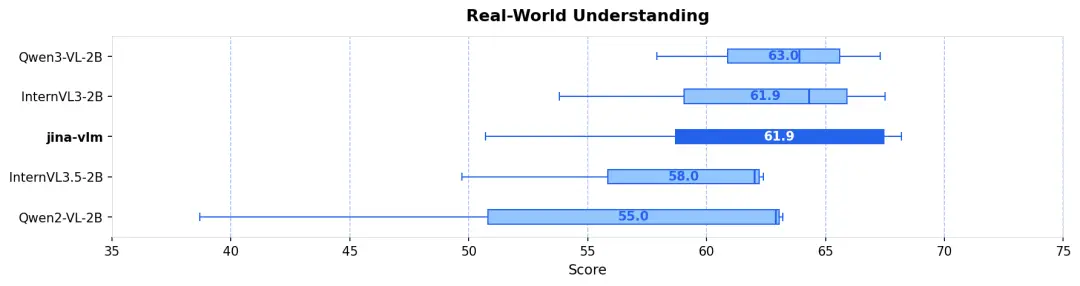
據介紹,在標準的 VQA 任務、多語言多模態理解(MMMB、MMBench),還是在 OCR 和純文本任務上,Jina-VLM 都是同規格模型裏最優級別的表現,且同時具備在消費級硬件友好的推理效率。
-
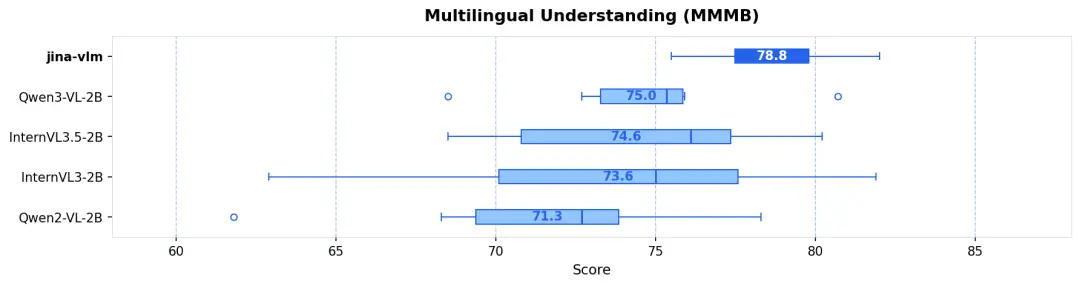
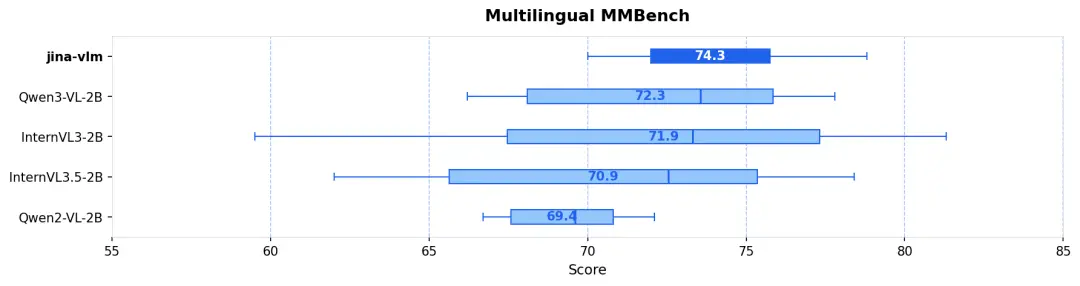
多語言理解 (MMMB SOTA) :在阿拉伯語、中文、英語、葡語、俄語和土耳其語等 6 大語種的測試中,Jina-VLM 以 78.8 分領跑,展現了卓越的跨語言視覺推理能力(見圖 1 & 圖 2)。
-
視覺問答 (VQA) :面對涵蓋圖表 (ChartQA)、文檔 (DocVQA)、場景文本 (TextVQA) 和科學圖表 (CharXiv) 等高難度測試中,模型表現穩健(見圖 3)。
-
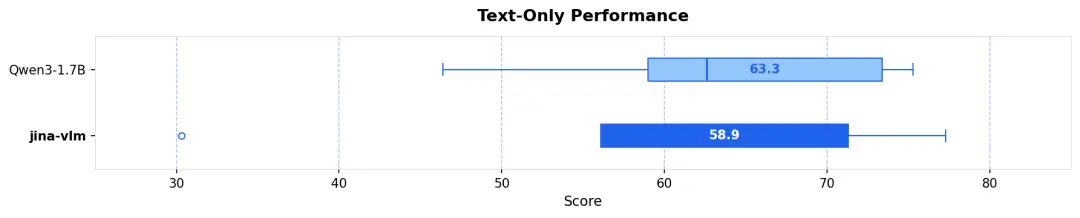
視覺增強,語言無損 :很多 VLM 在增強視覺能力後會犧牲文本智商。得益於特殊的訓練策略,Jina-VLM 在 MMLU(知識)和 GSM-8K(數學)等純文本任務上,幾乎完整保留了 Qwen3 基座的強悍性能(見圖 5)。
論文:https://arxiv.org/abs/2512.04032
Hugging Face: https://huggingface.co/jinaai/jina-vlm
